
Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Moving from AI pilots to dependable, scaled delivery in the ai cloud requires clear economics, disciplined execution, and tight control of risk. This guide shows how to quantify ROI, design a pragmatic implementation flow, and establish controls that keep systems reliable over time. It focuses on measurable outcomes—cost per inference, adoption, service quality—and the operational choices that drive them. The goal is to align architecture, process, and governance so AI remains cost-effective, safe, and maintainable at scale.
Introduction
In most organizations, AI initiatives start fast and stall when they hit production realities: cost sprawl, inconsistent quality, security concerns, and unclear ownership. The ai cloud changes the pace and the stakes—access to powerful models and elastic infrastructure is immediate, but so are new risks and bills. What matters now is a strategy that connects business goals to a controlled delivery model: the right architecture, the right controls, and the right metrics. If you can tie model choices and deployment patterns to unit economics and reliability, you turn AI from experimentation into a durable capability.
Understanding the Topic
An AI cloud strategy defines how an organization uses cloud-based AI capabilities—models, data services, and orchestration—to deliver outcomes with known cost, risk, and reliability. It sets the reference architecture, the operating model (people, process, controls), and the performance targets that guide investment and scale.
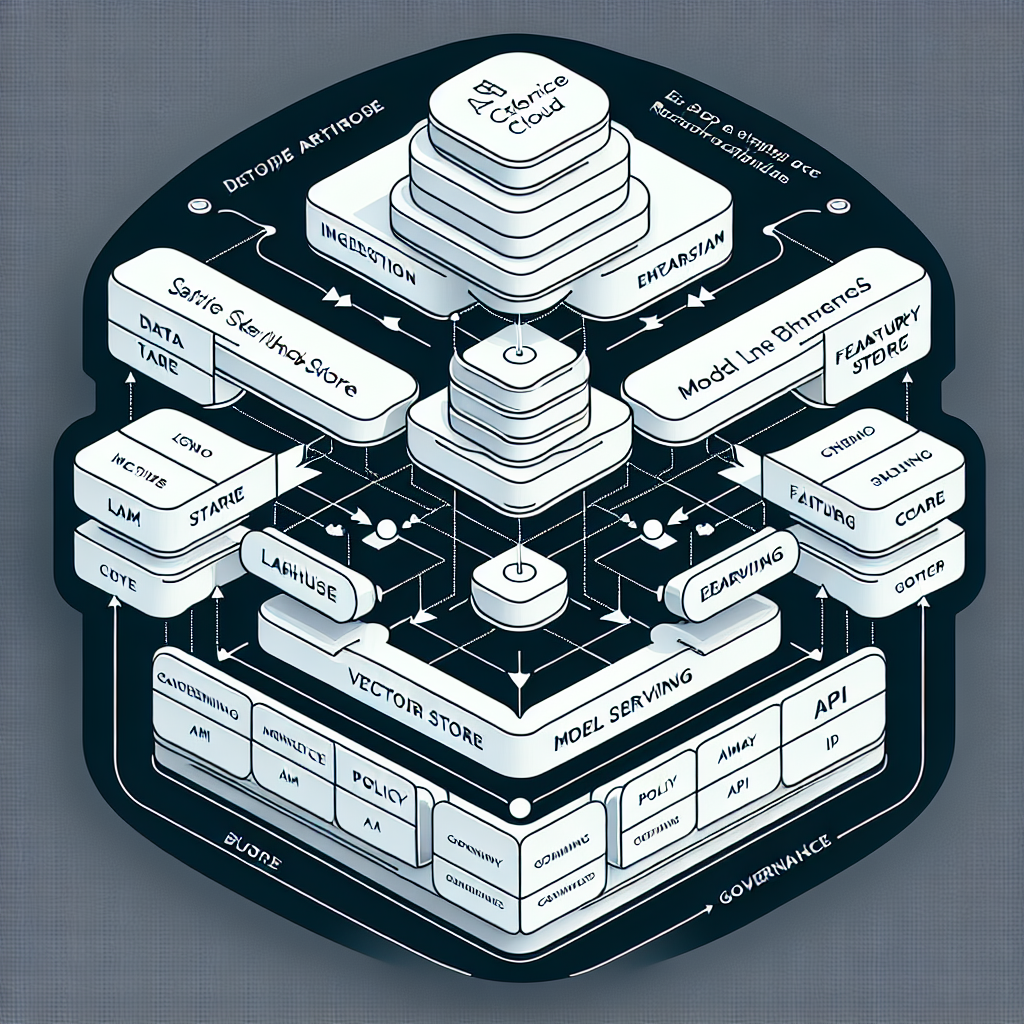
In the enterprise context, this means standardizing how teams access models (hosted or API), how data flows into retrieval and features, and how governance creates a safe boundary—identity, policy, monitoring, and cost controls—around all AI workloads. Done well, the strategy keeps experimentation fast while production remains predictable.
ROI Foundations
ROI in the ai cloud hinges on unit economics and adoption. Track cost per query or per document processed, model latency and throughput, and quality metrics tied to specific tasks (accuracy, coverage, deflection). Tie these to business drivers like cycle-time reduction, error-rate improvement, or workload deflection. ROI improves as reuse increases: shared components (prompt templates, retrieval pipelines, evaluation harnesses) convert one-off wins into scalable capability.
Risk Dimensions
Key risks include data exposure, vendor lock-in, model failures (hallucinations, prompt injection), operational instability, and cost volatility. Controls span identity and access, isolation of sensitive workloads, content safety filters, retrieval hardening, evaluation gates before promotion, and FinOps guardrails. Mature teams treat model behavior as a reliability problem: monitor, alert, and roll back when quality drops.
Operating Model
A practical operating model clarifies ownership: platform team for shared services and guardrails; product teams for use case delivery; governance for policy and audits. Standard intake (use case brief, data readiness, risk posture), a controlled promotion path (dev → staging → prod), and post-deployment SLOs keep the system predictable.
How This Works in Practice
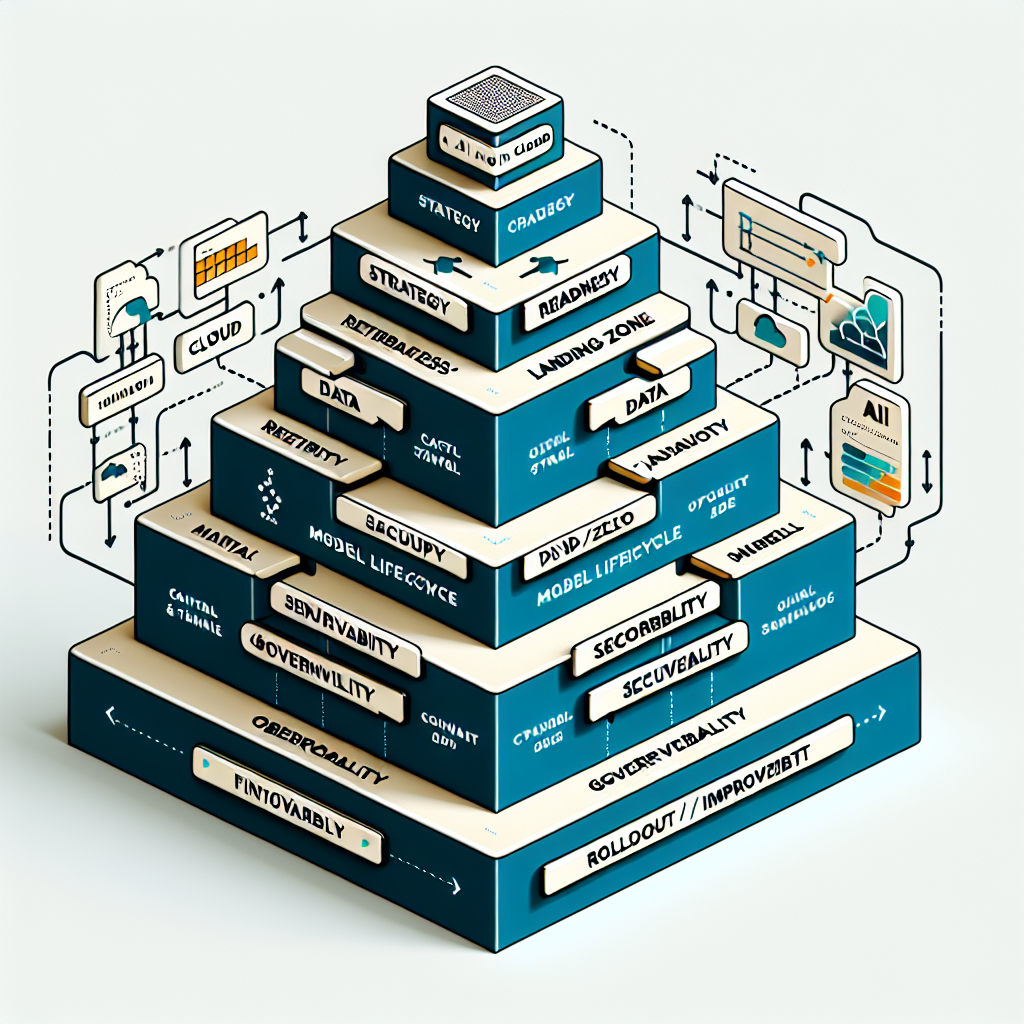
1. Set Objectives and Metrics
Start with 2–3 concrete outcomes per use case (e.g., reduce handling time by 30%, achieve 85% answer quality, cap cost per query). Translate them into measurable metrics: latency targets, accuracy thresholds, and unit cost ceilings.
2. Assess Data Readiness
Inventory sources, classify sensitivity, and define the retrieval plan. Decide what stays on-platform versus in private storage. Establish minimal metadata and access controls before building pipelines.
3. Define Reference Architecture
Select model access (managed API vs self-hosted), retrieval pattern (vector search + metadata filters), and serving topology (regional, autoscaled, GPU strategy). Outline observability, evaluation, and rollback paths.
4. Build the Landing Zone
Provision identities, networking, secrets, storage, and baseline policies. Automate via infrastructure-as-code. Enforce isolation for sensitive workloads and set cost policies (budgets, alerts, quotas).
5. Implement Data and Retrieval
Stand up ingestion, transformation, and indexing. Use deterministic chunking and metadata tags to control recall. Add a feedback loop to refine retrieval quality and reduce hallucinations.
6. Model Lifecycle and Serving
Standardize prompt templates, tools, and guardrails. Integrate evaluation harnesses (offline tests, canary traffic) before promotion. Right-size serving with autoscaling and capacity caps to prevent cost shocks.
7. Security and Governance
Apply content filters, policy checks, and data loss prevention. Log prompts and outputs with privacy controls. Embed approval workflows for changes to models, prompts, and retrieval sources.
8. Observability and SRE
Monitor latency, error rates, and quality drift. Set SLOs and alerts. Build playbooks for rollback and incident response. Track adoption and business impact alongside technical signals.
9. FinOps and Cost Control
Measure cost per request, per user, and per use case. Use reservations or spot capacity where appropriate. Enforce budgets and quotas; tune caching, batching, and routing for cost efficiency.
10. Rollout and Continuous Improvement
Start with constrained scope and expand as metrics stabilize. Collect user feedback, label failure cases, and adjust prompts, retrieval, and models. Periodically revisit architecture and vendor choices to avoid lock-in.
Tools and Technologies
Cloud AI Services
Model APIs, managed vector search, serverless functions, GPU instances, identity and access control, key management, monitoring and logging.
Model Serving
High-throughput inference servers, token-aware schedulers, autoscaling orchestrators, request routing and A/B testing.
Retrieval and Storage
Lakehouse storage, feature stores, vector databases and embeddings, metadata catalogs, streaming ingestion.
Orchestration and Agents
Prompt management, tool calling, task graphs, policy checks, evaluation harnesses for offline and canary testing.
Observability and Evaluation
Tracing, quality scoring, drift detection, safety filters, synthetic test suites, user feedback capture.
Security and Governance
Identity providers, secrets management, data loss prevention, content moderation, audit logging, policy-as-code.
CI/CD and Platform
Version control, pipelines, infrastructure-as-code, containerization, service discovery, configuration management.
FinOps
Budgeting, cost attribution, unit economics dashboards, capacity planning, rightsizing recommendations.
Examples and Applications
Knowledge Retrieval and Assistance
Centralized retrieval augmented generation reduces search time and improves answer quality. Impact shows up as faster resolution, lower rework, and consistent responses.
Document Processing and Compliance
Automated extraction, classification, and review with human-in-the-loop lowers cycle time and error rates. Guardrails and audit logs meet compliance requirements.
Developer and Operations Productivity
Code assistance, test generation, and runbook recommendations shorten release cycles and improve MTTR. Tracking deflection and quality keeps ROI visible.
Risk Monitoring
Pattern detection across logs and text surfaces anomalies early. Clear thresholds and escalation paths turn insights into action without alert fatigue.
Learning vs Scaling Considerations
Early builds focus on reliable retrieval, prompt discipline, and basic evaluation. At scale, invest in shared components, cost-aware routing, and formal SLOs to keep performance and spend stable.
Tables and Comparisons
Option Benefits Trade-offs Practical Notes Single-cloud, managed services Speed, integrated security, less ops Vendor lock-in, feature constraints Negotiate commitments; abstract interfaces for portability Multicloud, portable stack Flexibility, resilience to vendor change Higher complexity, duplicated effort Standardize APIs and IaC; adopt common observability Self-hosted open models Control, privacy, cost predictability at scale Operational burden, talent requirements Use high-throughput serving; enforce evaluation gates Proprietary model APIs State-of-the-art capability, minimal ops Variable pricing, behavior drift Implement canaries and fallbacks; monitor unit cost Dedicated GPUs Performance, isolation Cost, capacity planning risk Rightsize; mix with burst capacity for peaks Shared/serverless GPU Elasticity, lower idle cost Cold starts, noisier performance Warm pools, caching, batching to stabilize latency Online retrieval Freshness, dynamic context Latency, dependency on upstream systems Cache popular queries; degrade gracefully on failures Batch indexing Stability, predictable performance Lag, lower recency Hybrid approach: scheduled refresh + event triggers Centralized platform Consistency, reuse, governance Potential bottlenecks Self-service with guardrails to balance speed and control Federated teams Speed, domain fit Duplication, uneven quality Common standards and shared components reduce sprawl
FAQ
How do we calculate ROI for ai cloud use cases?
Start with a baseline metric (time, errors, cost) and model the impact per unit of work. Track cost per request, quality scores, and adoption. Validate with controlled pilots, then project using measured unit economics.
What should we build first?
A secure landing zone, retrieval pipeline, and evaluation harness. These create a stable foundation so each new use case inherits security, quality, and cost controls.
How do we control costs as we scale?
Set budgets and quotas, rightsize capacity, and optimize routing. Use caching and batching for heavy workloads, and continuously review model choices against unit cost.
How do we protect sensitive data?
Classify data, isolate workloads, enforce least-privilege access, and apply content filtering. Log with privacy controls and audit changes to prompts, models, and retrieval sources.
How do we mitigate hallucinations and prompt injection?
Harden retrieval with metadata filters, restrict tool access, and use evaluation gates before promotion. Monitor quality drift and roll back or retrain when thresholds are breached.
Conclusion
A durable ai cloud strategy connects business goals to a controlled delivery model with clear metrics, stable operations, and enforceable guardrails. When architecture, process, and governance move in lockstep, unit economics improve, reliability rises, and risks stay contained. The result is a platform that supports fast experimentation without compromising production. Use these patterns to scale AI with confidence and measurable impact.


