

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Executive Summary
Teams are moving from suggestion-only copilots to agents that propose, test, and deliver code. The shift rewards solid guardrails more than raw model power.
This piece shows what works, where it breaks, and how to sequence adoption without frying your process or trust.
Understand AI Coding Tools 2026 across a spectrum: assistive prompts, semi-automated patches, autonomous delivery
See real-world boundaries: context limits, flaky tests, ownership mismatches, compliance gates
Use a practical flow for propose → diff → test → review → governed merge
Learn what changes at scale: queues, quality gates, audit trails, role shifts
Introduction
The sprint is already red. A production issue landed on the same day a cross-cutting refactor started. Half the team is context-switching. Someone asks if the copilot can handle the boilerplate and tests so humans can triage production.
That’s the moment AI coding stops being a demo. It becomes a reliability problem. Does it keep the build green, preserve architecture intent, and respect code ownership?
AI Coding Tools in 2026: From Copilots to Fully Autonomous Development describes this shift. We’re not just typing faster. We’re handing parts of the software lifecycle to systems that don’t get tired but also don’t feel risk.
It’s trending because timelines compress, backlogs expand, and budgets aren’t growing. AI Coding Tools 2026 promise throughput. They only pay off when paired with constraints that keep the output shippable.
Where code meets commitment: how these systems behave under pressure
System boundaries in live codebases. Copilots do fine with local edits and clear intent. Push them into cross-module changes or ambiguous tickets and failure patterns show: invented APIs, brittle refactors, shallow tests that pass but miss behavior. Under a deadline, those misses cost more than the time saved.
Context windows help but are not project memory. Without a reliable way to surface architectural constraints, deprecation notes, and non-obvious invariants, generated code tends to mirror the most visible patterns, not the most correct ones.
Non-determinism is both a strength and a liability. You’ll get diverse approaches, which is great for exploration. It’s risky for migrations, hotfixes, and anything touching compliance-sensitive paths. Deterministic transforms still need to rule those lanes.
Tests become the contract. If tests are thin, the agent optimizes for passing them, not for correctness in production. The lesson isn’t to write essays for specs. It’s to write tests that capture behavior, edge cases, and performance characteristics you actually care about.
Ownership friction appears fast. If the agent can open PRs anywhere, it will. That breaks local conventions, triggers defensive reviews, and slows everything. Scope and permissions belong at the start, not the incident report.
Finally, silent regressions. Auto-generated code passes review but shifts latency, memory, or failure modes in ways your dashboards don’t flag immediately. Guardrails need to include runtime signals, not just static checks.
Operational path from suggestion to self-serve delivery
Start with a narrow lane. Define a ticket class the system is allowed to touch. Tie it to explicit acceptance criteria in human language and in tests. If there’s no test, the system writes one that fails first, then attempts the fix.
Give it the right context. Repository map, coding standards, architectural notes, and examples of accepted diffs. Avoid raw dumps. Curate a small, high-signal set. Too much context dilutes intent and increases wrong-but-confident outputs.
Run the loop: propose → diff → test → review → governed merge. The agent proposes a patch, runs checks, and posts a diff. Reviewers focus on behavior and risk, not minor style nits. Style is automated. Risk isn’t.
Define escalation paths. If tests are flaky, or the change crosses a boundary, the agent pauses and reassigns. Automatic retries without a change in strategy waste cycles and clog CI.
Track outcome quality. Not just pass/fail. Capture categories of edits that required human rewrite, and why. That feedback updates prompts, instructions, and which lanes remain autonomous.
At scale, queues matter. You’ll need prioritization, batching, and time windows where autonomous work won’t compete with hotfixes. Otherwise you create noise when the team least needs it.
Security and secrets deserve explicit policies. The agent should never invent credentials or broaden scopes. Read-only contexts for exploration, write permissions only within the lane, and auditable logs for every action.
Examples and applications that actually happen
A routine upgrade task looks safe. The agent updates signatures and adjusts call sites. CI is green. A week later, a rarely used path throws because one edge case was guarded by a comment, not a test. The fix wasn’t hard. The missing contract was.
A new feature requires a small API change plus UI wiring. The agent scaffolds the server change well, but the client code adopts patterns the team moved away from. Reviews stall. The lesson lands: teach the system what “modern” means in your repo via curated examples, not slogans.
Observability work seems ideal. The agent adds instrumentation. Dashboards light up, but latency creeps. The added data volume wasn’t budgeted. The remedy is to encode performance expectations as tests or policies the agent sees before proposing diffs.
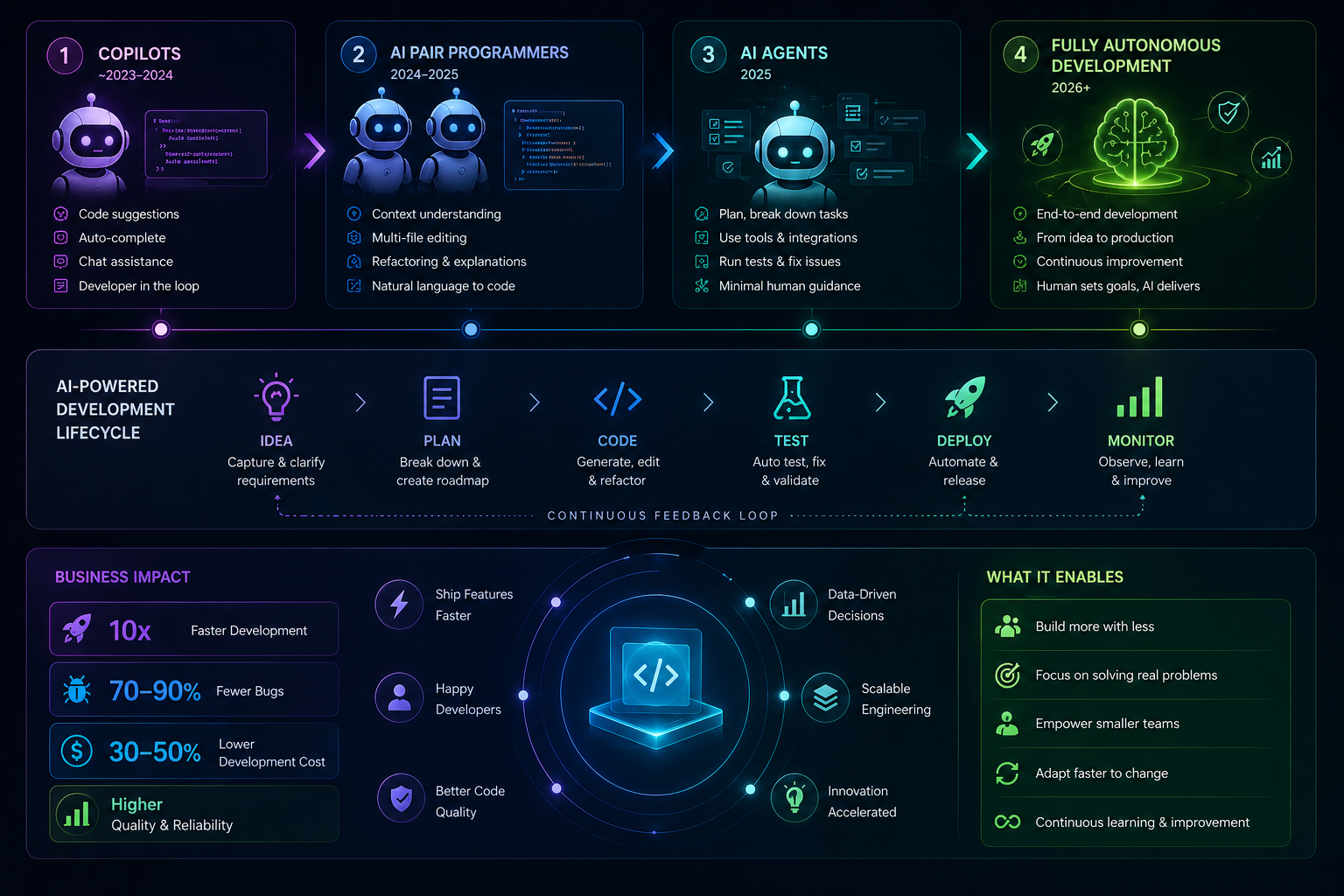
What changes with experience
Beginners and experienced practitioners both get value from AI Coding Tools 2026, but they optimize different things. The table clarifies the gap so teams can pair wisely.
Area Students/Beginners Experienced Practitioners Prompting Describe the task in general terms Anchor on constraints, acceptance, and repo norms Trust boundary Trust green tests Trust tests plus runtime signals and risk profile Review style Line-by-line changes Behavioral and architectural impact first Failure handling Retry with longer prompts Reduce scope or change strategy, then retry Time use Generate more, edit later Generate less, validate early Metrics focus Speed of completion Mean review cycles and post-merge stability Common pitfall Overfitting to examples in suggestions Under-specifying edge cases in tests Governance Ad-hoc approvals Policy gates, auditable lanes, scoped permissions
FAQ
Can I let an autonomous agent commit to main?
Not without a protected lane, passing checks, and a rollback plan. Merge through the same gates humans use.
How do we measure quality without slowing down?
Track categories of rework and post-merge incidents tied to autonomous changes. Use that to refine scope, not to ban the tool.
Will juniors learn less if the AI writes code?
They learn different things. Make them own review rationales, tests, and post-merge follow-up. That builds judgment.
What about secrets and tokens?
Never embed or request them in prompts. Use scoped service accounts and audits. Treat the agent like a contractor with least privilege.
How does this work with legacy code and thin tests?
Start by writing characterization tests around critical paths. Let the agent operate only inside those fences.
The handoff is shifting toward review and accountability
AI Coding Tools 2026 move typing out of the bottleneck. The real work becomes defining lanes, encoding expectations, and deciding what good looks like when you didn’t write the first draft.
As copilots become more autonomous, responsibility concentrates in review, tests, and policy. That’s where teams differentiate. Not in how much they generate, but in how consistently they ship safe changes.


