
Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Modern data initiatives rarely fail on algorithms. They fail on the scaffolding—how data moves, who can use it, and what changes are allowed. This piece details a pragmatic approach to governance and infrastructure for data analytics that holds up under production pressure: clear policies, reliable environments, observable pipelines, and cost-aware operations. It shows what changes when teams leave slideware and start shipping, how choices in storage and compute shape access and reliability, and how governance becomes enforceable instead of ceremonial. The focus is execution: policy-as-code, lifecycle management, and measurable outcomes like freshness, completeness, and incident MTTR.
Introduction
In real operations, data analytics succeeds or stalls on two foundations: governance that is enforceable, and infrastructure that is boringly reliable. As organizations scale, ad hoc access rules, long-lived manual data copies, and untracked changes quickly erode trust and slow delivery. The shift now is from platform-by-accident to platform-by-design—codifying policies, isolating environments, automating lineage and quality checks, and tying cost controls to usage.
This matters because data analytics is no longer a single team’s toolset. It’s a shared capability across domains, models, and products. Without a structured operating model, you get conflicting definitions, silent failures, and audit pain. With the right governance and infrastructure, you get repeatable delivery, predictable SLAs, and the confidence to expand use without multiplying risk.
Understanding the Topic
Governance and infrastructure for data analytics define how data is sourced, secured, transformed, cataloged, and consumed—plus the environments and controls that make those steps reliable and auditable. Governance sets policies (access, quality, retention, lineage, privacy). Infrastructure provisions the runtime (storage, compute, networking), automates enforcement, and provides observability.
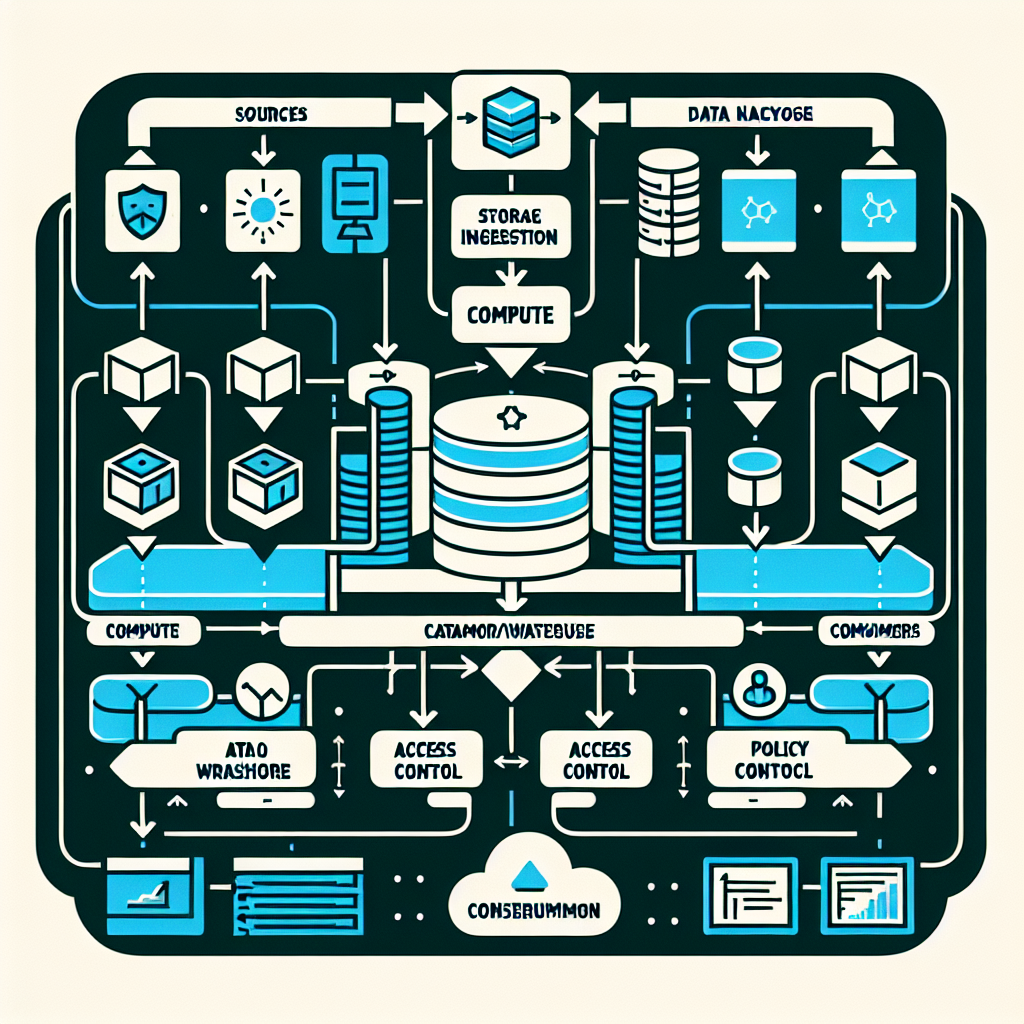
In an enterprise context, the stack spans ingestion (batch and streaming), storage (lake/warehouse/lakehouse), compute engines, metadata services (catalog, lineage), policy services (IAM, RBAC/ABAC, policy-as-code), orchestration, and monitoring. Governance is not a steering committee; it’s policies encoded into infrastructure, validated continuously, and surfaced to users through catalogs and access workflows.
Core definitions
Data governance: the set of policies and controls that define ownership, access, quality, lifecycle, and compliance. Infrastructure: the provisioned components and configurations that implement those policies and run workloads at scale. Together, they turn intent into execution.
Beginner-accessible framing
Think of governance as rules you can test, and infrastructure as the machines that enforce them. When rules live only in documents, teams drift. When rules are code linked to pipelines and access systems, teams move faster with fewer surprises.
Key properties of a modern stack
Policy-as-code: access, retention, and quality checks tested and versioned.
Environment isolation: dev/test/prod with change control and promotion paths.
Observable pipelines: freshness, completeness, schema drift, lineage, and alerts.
Metadata-first: cataloged data assets, owners, contracts, and SLAs.
Cost awareness: auto-scaling, resource quotas, usage tagging, and budgets.
How This Works in Practice
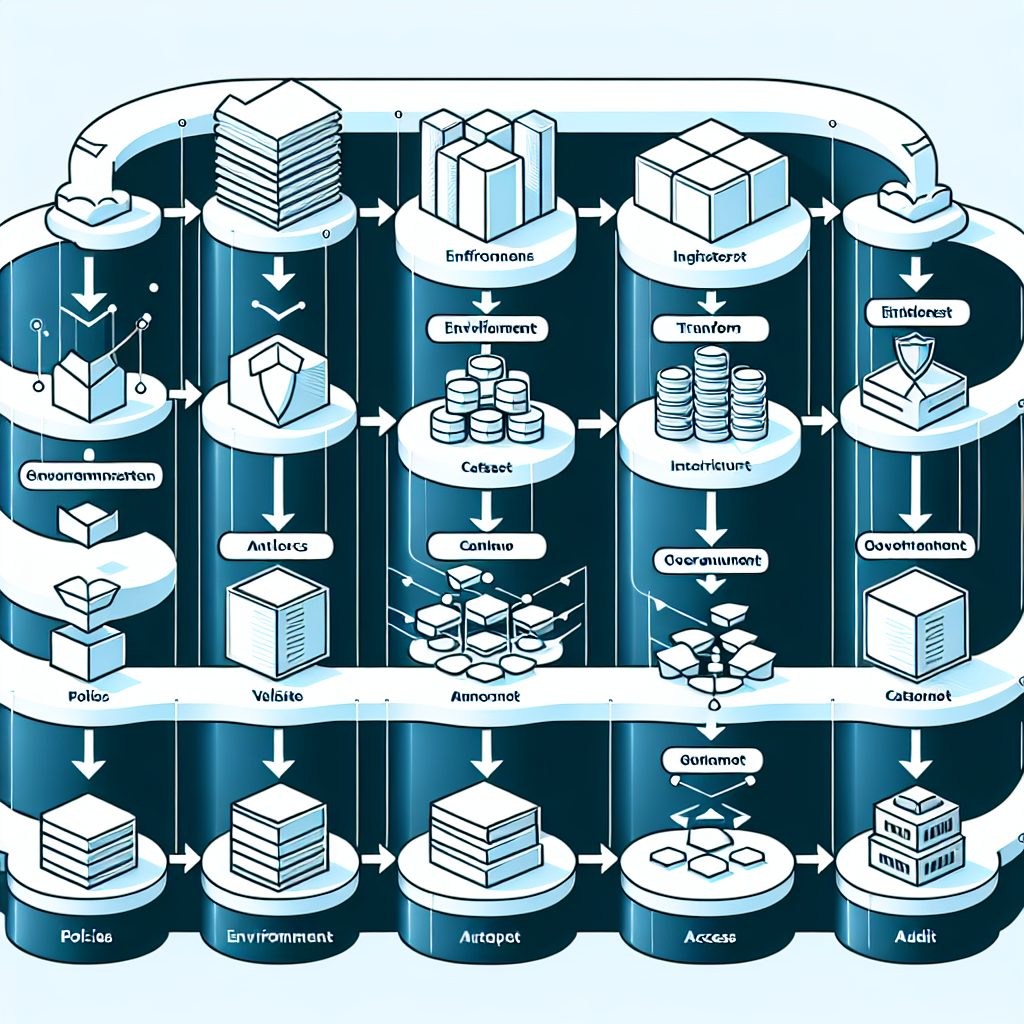
The operational flow is sequential and testable from policy to production. Each step ties a decision to an outcome you can measure.
Define policies and data contracts. Specify domain ownership, PII handling, access levels (RBAC/ABAC), retention, quality thresholds (freshness, completeness), and lineage requirements. Capture contracts for schemas and SLAs.
Provision environments. Create isolated dev/test/prod with separate accounts/projects, networks, and encryption. Attach policy engines and IAM roles to each environment. Enforce resource quotas and tagging for cost attribution.
Ingest data. Use managed connectors or streaming to land data into staging zones. Record lineage at source, include schema registry, and apply initial validations (size, null rates, basic profiling).
Transform and model. Apply transformations with versioned code. Enforce change control: pull requests, automated tests, and promotion gates. Track dependencies between datasets, models, and dashboards.
Validate quality. Run data quality checks (freshness, completeness, uniqueness, referential integrity) with thresholds tied to SLAs. Fail fast on contract violations. Alert owners and create incidents automatically.
Catalog and classify. Register assets, owners, tags, sensitivity, and lineage paths. Publish discoverable definitions and trust signals to analysts and engineers.
Provision access. Grant access via roles or attributes mapped to cataloged classifications. Use request workflows with audit trails. Prefer views over copies; minimize data sprawl.
Monitor and optimize. Track SLOs (freshness, uptime), MTTR for incidents, and cost per workload. Analyze slow queries and hotspots. Scale resources or adjust retention and caching.
Audit and improve. Review policy coverage, exceptions, and incident patterns. Close the loop: refine contracts, update policies, and retire unused assets.
Tools and Technologies
Storage and compute
Object storage for lakes: Amazon S3, Azure Data Lake Storage, Google Cloud Storage.
Warehouse/lakehouse engines: Snowflake, BigQuery, Redshift, Databricks SQL, Apache Spark.
Open table formats: Apache Iceberg, Delta Lake, Apache Hudi for schema evolution and ACID.
Ingestion and orchestration
Batch connectors: Fivetran, Airbyte, dbt-extractor patterns.
Streaming: Kafka, Amazon MSK, Azure Event Hubs, Apache Flink.
Orchestration: Apache Airflow, Dagster.
Governance and security
Catalog and lineage: Collibra, Alation, Apache Atlas, OpenMetadata.
Access control: Cloud IAM, Lake Formation, Ranger; RBAC/ABAC with policy-as-code using OPA/Rego.
Privacy and classification: data masking, tokenization, column-level security, sensitivity tags.
Quality and observability
Data testing: Great Expectations, Soda, dbt tests.
Observability: Monte Carlo, Databand, built-in warehouse/lakehouse metrics.
Cost monitoring: cloud native budgets, usage tagging, query-level cost analysis.
Modeling and serving
Transformation and semantic layers: dbt, LookML-like semantics, metric stores.
Access patterns: views, materialized views, feature stores for ML, APIs.
Examples and Applications
Regulatory reporting
Policies enforce retention, lineage, and access traceability. A catalog ties reports to datasets and owners. Quality checks guard completeness on filing deadlines. Outcome: fewer manual reconciliations and better audit readiness.
Operational analytics
Streaming ingestion feeds near-real-time metrics. Attribute-based access keeps sensitive fields protected while enabling broad consumption. Outcome: faster incident detection with controlled exposure.
Self-service analytics
Discoverable datasets with clear contracts and freshness signals allow teams to build insights without duplicating data. Outcome: improved time-to-insight and reduced shadow pipelines.
Applied ML features
Versioned transformations and quality checks stabilize feature generation. Lineage links features to source data and model outputs. Outcome: reproducible training and consistent online/offline behavior.
Tables and Comparisons
Option Benefits Trade-offs When to choose Centralized governance Consistent policies, simpler audits, clear ownership Slower local decisions, potential bottlenecks High compliance pressure, small to mid-size teams Federated governance Domain autonomy, faster iteration Policy drift risk, requires strong standards Large organizations with diverse domains Warehouse-centric stack Simpler management, strong SQL performance Less flexible for varied file formats/streaming Primarily batch analytics, standardized schemas Lakehouse with open tables Unified storage, ACID, schema evolution Operational complexity, tuning required Mixed workloads, streaming + batch, cost control Data mesh (domain products) Scalable ownership, domain-aligned delivery Needs strong platform and governance baseline Multiple domains, autonomy with shared standards
FAQ
How do I start governance without slowing delivery?
Begin with a minimal policy set: access tiers, PII handling, data contracts for key datasets, and quality thresholds tied to SLAs. Encode them as tests and IAM rules, then expand coverage iteratively.
Do I need a lake, a warehouse, or both?
Choose based on workloads. Warehouses excel at SQL analytics. Lakes handle diverse data and streaming. A lakehouse with open table formats can unify both, but requires disciplined operations.
What should I measure to know it’s working?
Track freshness, completeness, schema drift incidents, MTTR, request-to-access lead time, and cost per query or pipeline. Tie metrics to policies and publish them.
How do I handle schema changes safely?
Use contracts and registries, test changes in dev, run backward-compatibility checks, and promote via controlled releases. Alert downstream owners automatically.
How do I keep costs predictable?
Tag workloads, set budgets, enforce quotas, use auto-scaling with limits, and optimize storage tiers. Review unused assets and expensive queries regularly.
Conclusion
A modern data analytics stack becomes durable when governance is code and infrastructure is engineered for isolation, observability, and cost control. With clear policies, staged environments, quality checks, and a living catalog, teams deliver faster without trading away trust. The result is stable operations, predictable SLAs, and a platform that scales with demand. Start small, measure, and expand standards as usage grows.


