

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Executive Summary. Business process automation with AI is no longer optional once your workflows cross multiple systems, carry audit requirements, and operate under tight SLAs. The friction shows up as queues backing up, human approvals dragging, and compliance reviews turning linear flows into branching, state-heavy work.
Engineering Business Process Automation with AI Agents becomes the lever when the manual glue between systems is the real bottleneck. Agents don’t replace policy; they carry policy, negotiate states across services, and keep the process moving when a single timeout would otherwise stall a line of work.
The technical challenge isn’t the model. It’s sequencing decisions, maintaining idempotency, and surfacing enough context for humans to trust what happened. Failures aren’t theoretical—they’re silent drops, mismatched records, and half-applied changes that turn into reconciliation sprints.
Adoption stumbles when teams treat agents as free-form automation. Production rewards deliberate boundaries: what the agent can decide, what must escalate, and how to recover without writing a second system to fix the first.
Introduction. Picture a quarter-end close that always squeaks past the deadline. Intake, classification, enrichment, approvals, and settlement stretch across email, ticketing, ERP, and a compliance review queue. Nothing is egregiously broken, but the handoffs leak time. The moment one system runs slow, work piles up behind a person whose calendar becomes the throughput constraint. That’s where Engineering Business Process Automation with AI Agents moved from an idea to a requirement. We had to keep the flow alive without adding yet another dashboard for humans to babysit.
In that environment, business process automation with AI isn’t about finding a perfect model; it’s about turning ambiguous inputs into actionable operations under policy, while keeping the line running despite flaky integrations and shifting data quality. The first agent we shipped didn’t make things faster; it made failure visible. After that, we focused on how the process could absorb volatility and still produce outcomes we could sign off on.
Production pressure exposes where autonomy must stop and process must recover
In production, an AI agent is closer to a choreographer than a wizard. It classifies work, calls tools, gathers context, and proposes actions. The job isn’t to be clever; it’s to be consistent and recoverable when the environment doesn’t cooperate. Rate limits, partial payloads, and out-of-order events are not edge cases. They are the shape of the system.
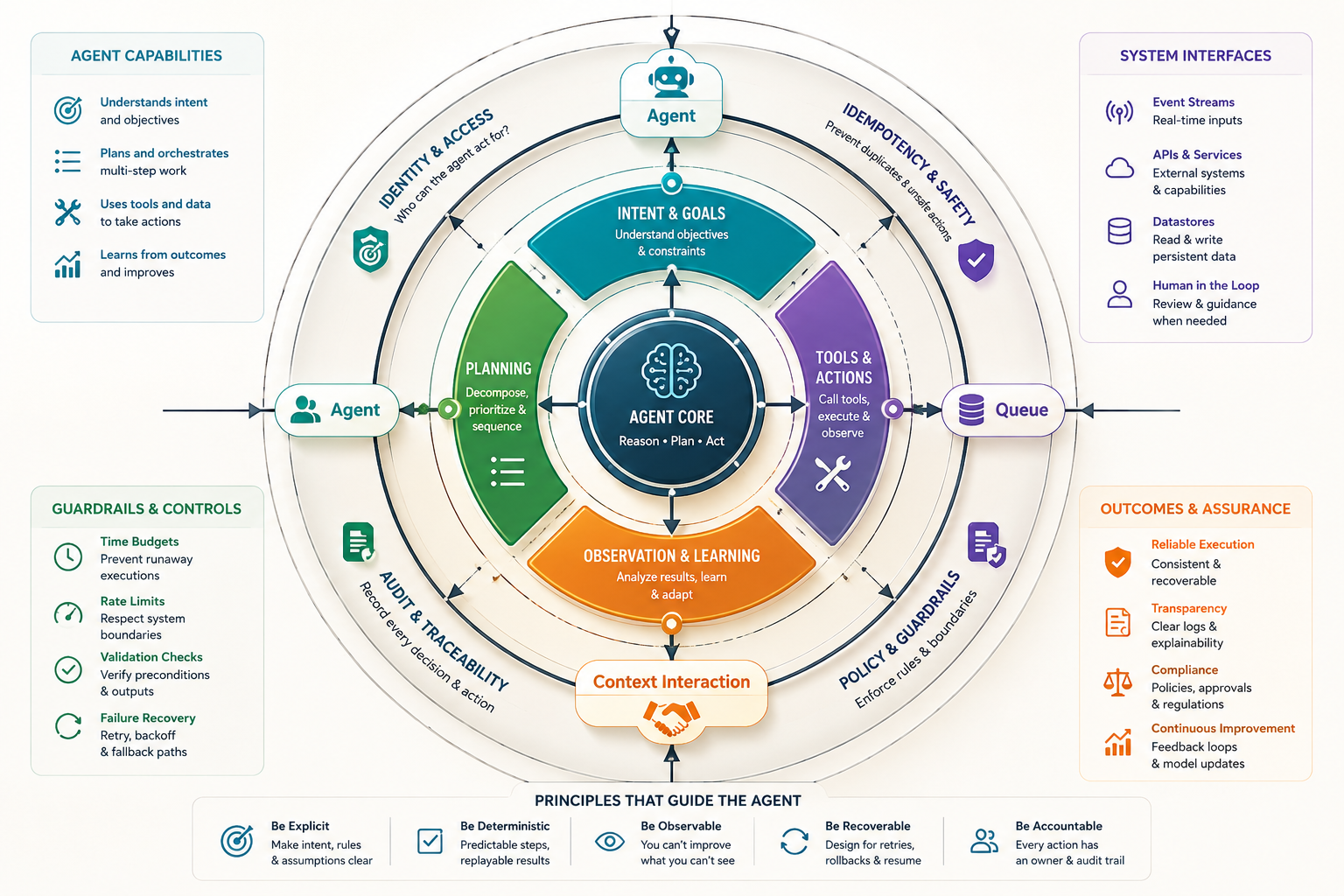
Constraints sit everywhere. Identity and access determine what the agent can touch, not what it wants to touch. Idempotency keys prevent double writes when retries collide. Time budgets keep call stacks from spiraling. Audit requires durable traces of every decision, including the ones that didn’t execute. The failure modes are boring and expensive: duplicate records, missing attachments, lost context, and policy checks that pass in development but fail in production because the data arrived late.
Boundaries matter. If the agent initiates a financial action, its proposal should be separated from execution by a control that can independently validate preconditions. If the agent reconciles records, it should prefer append-only logs and produce a deterministic diff. If it interacts with humans, it should be able to pause, persist state, and resume without recreating the environment from scratch.
Drift lives in prompts and in data. Prompts mutate as you add tools; inputs mutate because upstream systems don’t hold still. We learned to pin behaviors with lightweight policies that outlive a model version and survive an integration upgrade. That policy layer carried more weight than any single capability added to the agent.
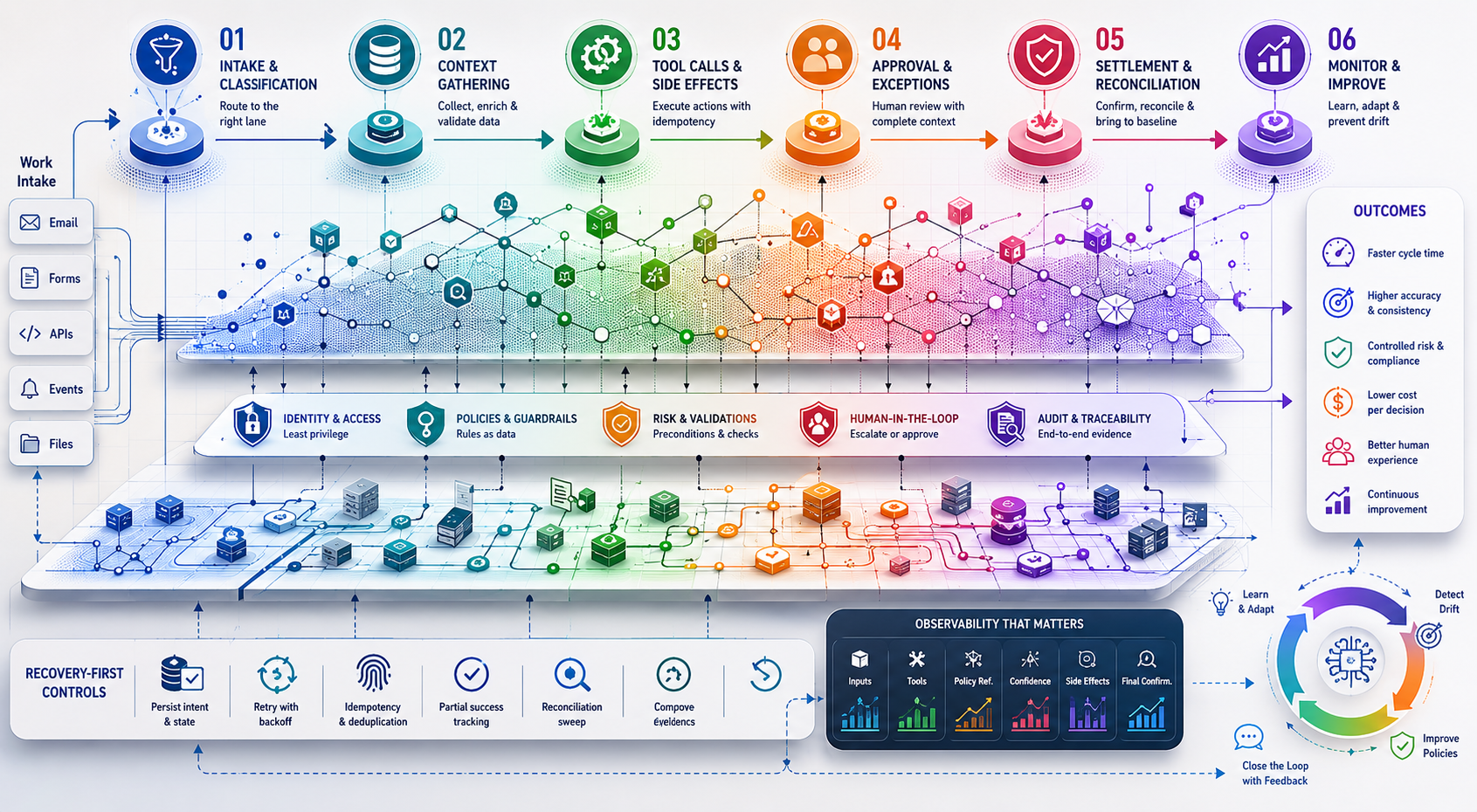
Sequencing the handoffs that create real friction
The flow starts with intake. An agent classifies work and routes it to the right lane, but classification without confidence thresholds creates unstable queues. We set decision gates: low-confidence items get enriched, medium-confidence items get a human nudge, high-confidence items proceed with safeguards.
Next is context gathering. Dependencies balloon here: data sources with varying latency, credentials with different scopes, and schema mismatches across environments. The agent should tolerate missing fields and re-query when downstream validation fails, rather than blocking the entire lane. This is where teams slow down and revisit decisions—especially around how much context is enough to act versus enough to propose an action that a human can accept or reject.
Tool calls and side effects follow. This is where retries and concurrency get painful. We hit race conditions when multiple agents attempted related updates. Idempotency became non-negotiable, and we pushed write operations behind a queue with deduplication. It didn’t feel elegant, but it prevented the double-apply that created audit headaches.
Approval and exception handling introduce human time into the system. If the agent can prepare a decision packet that’s complete and traceable, human reviews compress from 20 minutes to 2. If the packet is missing context or the explanation is opaque, reviewers stall, and the queue amortizes that delay across dozens of items. The hidden dependency is explanation quality. It needs to be factual, tied to policy, and structured so a reviewer can signal accept, reject, or request more context without starting over.
Settlement and reconciliation bring the process back to baseline. Agents will happily say “done” even when the downstream system eventually rejects the write. We added a reconciliation sweep that treats every action as pending until confirmation arrives from the system of record. That sweep became the backbone of trust. Without it, we measured speed; with it, we measured correctness under load.
Recovery-first controls keep AI-driven flows from drifting into guesswork
Agents need to be interruptible and resumable. A long-running task that fails at minute nine shouldn’t throw away the previous eight minutes. We learned to persist intent and partial artifacts, then resume with the smallest unit of work that can be retried independently.
Policy needs to be declared—not buried in prompts. Write the rules as data. Keep them versioned, testable, and observable. When a rule changes, you want to see the distribution of decisions before and after, not just a model accuracy metric. In regulated processes, that differential view is how you avoid rolling back an entire release when one policy shift has outsized effects.
Observability that matters is per-decision, not just per-service. Log inputs, chosen tools, outputs, confidence, policy references, side effects, and final confirmations. If it sounds heavy, it is. But it’s what lets operations answer “what happened” without reverse-engineering the agent’s thought process.
Latency, cost, and error surfaces force unpopular architecture choices
Real-time ambitions hit cost ceilings fast. If the process can tolerate batching, take it. If parts of the decision can be precomputed and cached, do that before a human opens the item. If you must be interactive, accept stricter time budgets and strip the workflow down to essential calls.
Error surfaces multiply with more tools. A smaller tool set with clear contracts is often better than a larger set with brittle integrations. We cut tools when the recovery story was unclear, even when a tool performed well in isolation. Fewer places to fail beats more cleverness.
Human in the loop isn’t a concession—it’s a control. Put humans at the boundary where consequences change category (financial commit, policy exception, customer-facing communication). Design the agent to make humans faster at those boundaries, not to bypass the boundaries.
Tooling pressure: choose what keeps decisions observable
Tool choices should explain a constraint, not decorate the architecture. A workflow engine earns its place if it enforces idempotency and compensations. A message queue is justified when retries need backoff and deduplication. A policy layer is necessary when rules must be versioned and traced independent of the model.
For business process automation with AI, the model provider matters less than the surrounding contracts: streaming vs batch, token limits vs timeouts, function calling that returns structured errors, and hooks for content moderation or classification fallback. Data stores that support append-only logs and easy diffing beat ones that save you a millisecond and cost you an audit trail.
Secrets and identity deserve their own gravity. Agents touching multiple systems will need scoped credentials and rotation. If your tool stack makes rotation painful, that friction will appear as weekend outages and emergency rollbacks.
Scenarios where agents help—and where they bite back
Finance operations that mirror policy rather than improvise it
An agent that assembles documentation, validates line items against declared rules, and proposes settlement will speed up the close only if the rules are externalized. Hide the rules in prompts and you’ll ship a helpful assistant that invents exceptions. Externalize rules and you’ll ship a clerk that never forgets a step and can explain why each decision was made.
Procurement approvals under variable data quality
When requisitions arrive incomplete, the agent can chase missing fields, but each fetch adds latency. If the downstream cutoff is tight, the agent should switch modes: move incomplete items to a lane that gets human attention with a clear list of missing data. This trades speed for correctness. The unintended consequence is a growing queue of “almost ready” items that need focused review. It’s manageable if the review interface is fast; it’s disastrous if reviewers have to reconstruct context.
Customer support triage that can’t afford false escalation
Agents classify intent and route work, but the cost of a false escalation is high when it wakes up on-call or triggers refunds. We introduced conservative thresholds and a second pass that tries to de-escalate by collecting one more signal. It improved trust but added latency. Operations had to decide when the extra minute was acceptable and when a direct handoff to an experienced agent was more honest.
Back-office reconciliation with mismatched identifiers
Agents can reconcile records across systems, but identifier mismatches create ambiguous joins. The fix wasn’t smarter models; it was a canonical mapping service with audit logs. Once that existed, the agent stopped guessing and started producing clean diffs. The trade-off was a new system to operate. It paid off by turning reconciliation from guesswork into repeatable work.
Where newcomers stumble and veterans adjust
This comparison isn’t about sophistication; it’s about where attention lands under pressure.
Decision AreaNewcomer PitfallExperienced AdjustmentConsequenceHandoffsAssume linear progressionDesign for pauses and resumesFewer restarts, clearer auditPolicyEmbed rules in promptsExternalize rules as dataTraceable changes, quicker rollbackRetriesRetry blindlyUse idempotency and dedupNo double writes, simpler recoveryObservabilityAggregate metricsPer-decision tracesFaster incident triageHuman ReviewGeneric approvalsDecision packets with contextLower latency, higher trust
Questions that surface once pilots hit production
How do we stop agents from “doing too much”? Declare scopes per process stage. Proposals and validations can be autonomous; commits pass through controls. If a scope expands, change the policy file, not the prompt.
What happens when upstream data quality tanks? Switch lanes: from full automation to enrichment + human review. Persist state so partial work isn’t wasted. Track this shift explicitly for reporting.
How do we measure success without vanity metrics? Count recoveries and corrected actions, not just throughput. Measure time-to-acceptable-outcome, not time-to-first-action.
How do we debug decisions we don’t agree with? Log inputs, tools selected, policies referenced, confidence, and side effects. Make it possible to replay the decision with a different policy snapshot.
What’s the smallest viable rollout? One lane, one scope, clear controls, and a reconciliation sweep. Anything larger hides failures you’ll have to pay for later.
Responsibility shifts from models to operating policy
Given how things behave today, this is what quietly changes next: teams stop arguing about which model is smartest and start maintaining policies, controls, and recovery paths that keep business process automation with AI honest under stress.
Manual handoffs → hybrid orchestration → agent-mediated controls → policy-driven autonomy


