

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Enterprises are pushing ai analytics beyond proofs of concept toward reliable, governed, and cost-effective production systems that drive measurable impact.
TLDR
Moving ai analytics from pilot to production is a disciplined shift from experimentation to engineered systems. It matters because reliability, compliance, and cost control determine real value. It helps large organizations turn scattered wins into repeatable performance at scale.
Executive Summary
Scaling ai analytics requires an enterprise architecture anchored in governance, observability, and MLOps, not just model accuracy. The path is an operational journey: define outcomes, ready data, harden platforms, deploy safely, and measure value continuously. Success depends on aligning risk, cost, and change management with business timelines. The payoff is decision-grade analytics embedded in workflows, improving speed, consistency, and margins.
Introduction
Most large organizations have dozens of pilots that never become products. A bank’s fraud team builds a promising model, a manufacturer’s maintenance pilot shows lift, a retailer’s personalization test increases conversions—yet none survive the jump to production. The gap is not algorithms; it’s systems, controls, and adoption. From Pilot to Production: Scaling AI Analytics for Enterprise matters now because economic pressure, regulatory scrutiny, and platform maturity have converged. Leaders need ai analytics that operates at scale, survives audits, and improves P&L—without spiraling costs or operational risk.
Understanding the Topic
Ai analytics is the engineered practice of transforming data into decision-grade insights using statistical methods and machine learning, delivered through governed platforms into business workflows. In an enterprise, it spans data pipelines, models, deployment, monitoring, and controls—built for reliability, security, and cost discipline.
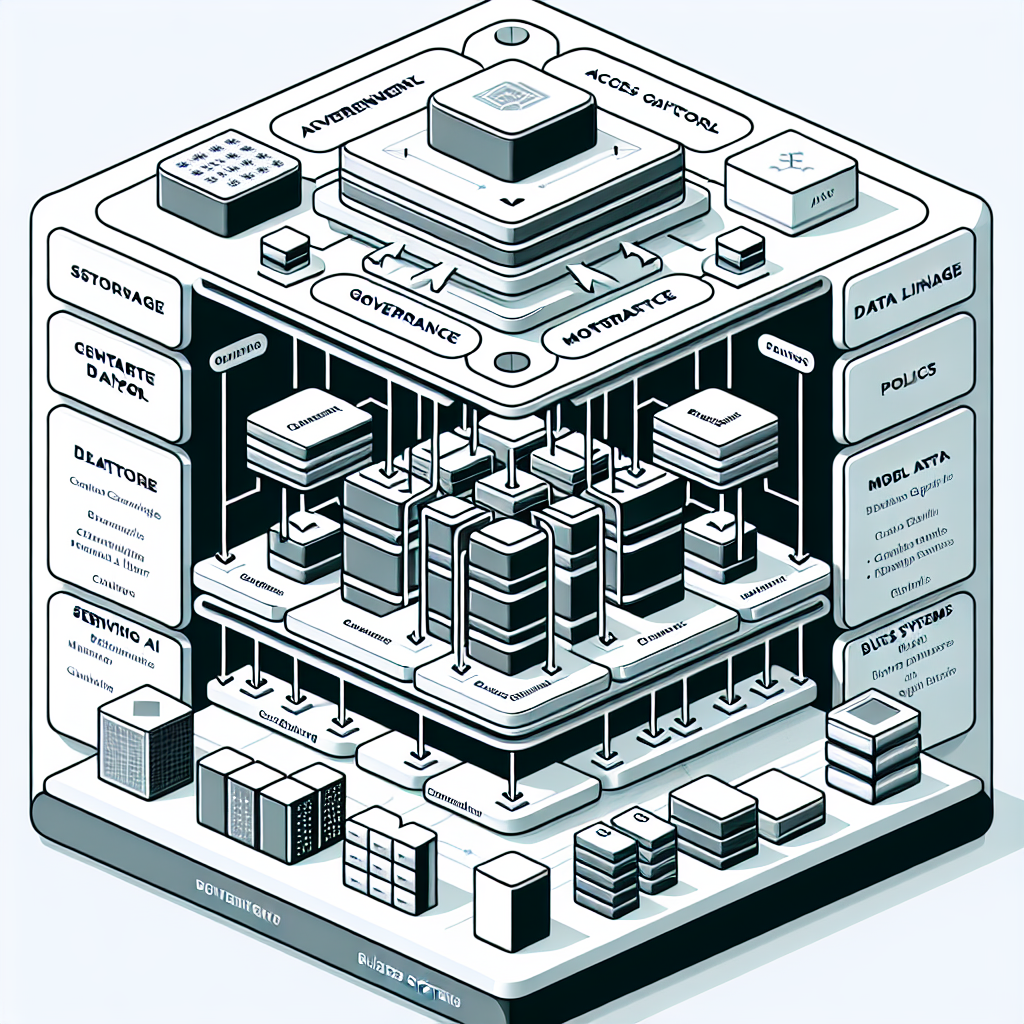
In production, the target is not a model score; it is a dependable service that meets latency, throughput, availability, and compliance requirements. This shifts focus from experimentation to architecture: data quality, lineage, access control, feature management, deployment patterns, observability, rollback, and lifecycle governance.
Pilots emphasize discovery. Production emphasizes durability. Scaling means your analytics can onboard new use cases, handle variable loads, survive failures, and deliver repeatable outcomes across regions, lines of business, and regulatory contexts.
What production-grade actually means
Production-grade ai analytics integrates standardized datasets and features, automated tests, reproducible builds, controlled deployments, continuous monitoring, and documented risk controls. It delivers service-level objectives (SLOs) and cost guardrails while maintaining model performance and compliance.
Where pilots stall
Common stall points include unclear business outcomes, ungoverned data, brittle pipelines, ad-hoc environments, manual deployments, and missing monitoring. Without lifecycle ownership and a platform strategy, pilots remain local successes that cannot be trusted enterprise-wide.
The enterprise lens
The enterprise lens adds requirements: identity and access management, encryption, audit trails, policy enforcement, change management, vendor oversight, and financial accountability. The outcome is a portfolio of analytics capabilities that are safe to scale.
How This Works in Practice
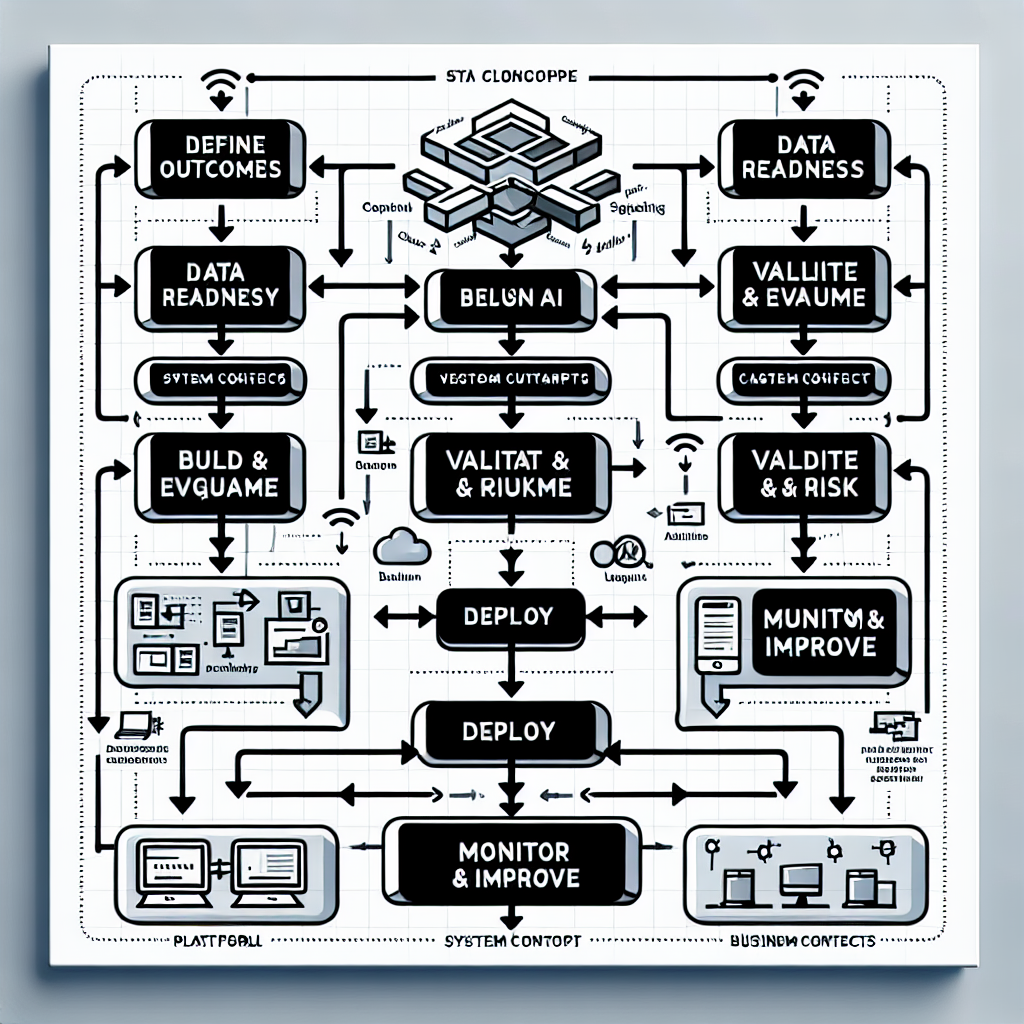
Scaling is a repeatable, end-to-end workflow that turns ideas into operating services with measurable value.
1. Define outcomes and constraints
Start with business objectives, measurable KPIs, and non-functional requirements (latency, availability, geography, data residency). Document policy constraints, approval paths, and service boundaries. This creates the contract between business, risk, and engineering.
2. Data readiness and governance
Inventory sources, establish lineage, and remediate quality. Implement access controls, encryption, PII handling, and retention. Standardize features with versioning and provenance so multiple models can reuse trusted building blocks.
3. Reference architecture and platform hardening
Select a deployment target (containers, serverless, or managed services) with clear boundaries for data, compute, and serving. Define environments (dev, test, prod), CI/CD pipelines, secrets management, and cost attribution. Adopt patterns for batch, stream, and real-time inference.
4. Model development and evaluation
Build with reproducible experiments, baseline against simple models, and capture metadata. Evaluate not just accuracy, but stability, bias, robustness, and performance under load. Prepare fallback strategies and human-in-the-loop when required.
5. Validation, approvals, and risk
Run validation against policies and stress scenarios. Document intended use, limitations, monitoring plan, and escalation procedures. Obtain risk, compliance, and security approvals before deployment.
6. Deployment patterns
Choose strategies (blue/green, canary) with automated rollback. Package models with dependency isolation and immutable artifacts. Publish versioned APIs or batch outputs with service contracts.
7. MLOps and AIOps
Implement continuous training where justified, monitor drift, data changes, and performance. Collect logs, metrics, traces, and feedback signals. Automate alerting, incident response, and capacity scaling.
8. Adoption and change management
Embed ai analytics into workflows, decision rights, and incentives. Provide user training, explainability tools, and clear operating procedures. Align governance to enable learning without paralysis.
9. Value measurement and portfolio management
Track impact against KPIs, attribute value to business units, and retire underperforming assets. Maintain a portfolio roadmap that balances quick wins with foundational capabilities.
Tools and Technologies
Data platforms: cloud data warehouses, lakehouses, and object storage for scalable ingestion, transformation, and retrieval; streaming platforms for real-time signals; vector stores for semantic retrieval when applicable.
Compute and orchestration: container platforms, serverless runtimes, workflow schedulers, and event-driven pipelines to run training, batch jobs, and inference with reproducibility and isolation.
ML and analytics frameworks: classical models (regression, tree ensembles), deep learning for perception and sequence data, and retrieval-augmented techniques for knowledge-rich use cases; feature stores to standardize and reuse engineered features.
Serving and APIs: model servers, function endpoints, batch exporters, and message queues; caching for low-latency inference; schema contracts to keep producers and consumers aligned.
Observability: monitoring for performance, drift, data integrity, and cost; tracing across data pipelines, model calls, and downstream actions; audit logs for access and changes.
Governance and security: identity and access management, encryption at rest and in transit, policy enforcement, consent tracking, data minimization, and reproducibility controls with model registries.
Cost and platform operations: resource quotas, autoscaling, rightsizing, storage lifecycle policies, and per-use-case cost attribution to keep ai analytics sustainable.
Examples and Applications
Forecasting and replenishment: integrate sales, supply, and external signals to reduce stockouts and carrying cost. Start with batch predictions and move to near-real-time updates as data latency improves.
Customer insights and next-best-action: unify behavioral and transactional data to personalize offers. Pilot in one channel, then scale across web, app, and contact center with consistent governance and explainability.
Risk scoring and fraud detection: combine rules with models for layered defense. Use canary deployments and human-in-the-loop review to balance risk reduction and false positives before widening coverage.
Claims and ticket triage: classify, route, and summarize at intake. Measure cycle-time reduction and quality outcomes, then expand to broader case types with controlled automation thresholds.
For learners, these use cases demonstrate patterns—ingest, feature, predict, serve, monitor—showing how each step contributes to reliability. For experienced readers, the emphasis is on multi-market scaling, policy variance, and portfolio-level governance that sustains performance over time.
Tables and Comparisons
Approach When It Fits Benefits Trade-offs Pilot sandbox Exploration with limited scope Speed, low ceremony Fragile, hard to audit, not scalable Managed production platform Multiple use cases and teams Reliability, governance, reuse Setup investment, process discipline Centralized model serving Shared features and common patterns Consistency, cost efficiency Potential bottlenecks, slower local autonomy Federated domain deployment Varied regional or product needs Flexibility, domain ownership Coordination overhead, governance complexity Build-first Differentiated capabilities Control, customization Time to value, maintenance burden Buy-first Commodity capabilities Speed, vendor support Lock-in, limited extensibility Batch inference Non-urgent decisions Simpler ops, lower cost Latency, stale signals Real-time streaming Time-sensitive actions Freshness, responsiveness Complexity, higher operational cost
FAQ
How is ai analytics different from BI?
BI summarizes historical data for reporting. Ai analytics builds predictive or prescriptive models that drive decisions in workflows, with engineered pipelines, serving, and monitoring to meet operational requirements.
What is the minimum architecture to move from pilot to production?
A governed data source, reproducible build pipeline, model registry, controlled deployment target, monitoring for performance and drift, and documented rollback. Even small stacks need these building blocks.
How do we quantify ROI beyond model accuracy?
Tie models to business KPIs: revenue lift, cost reduction, cycle-time, error rate, and risk exposure. Track adoption, automation rate, and decision latency. Measure unit economics, not just offline metrics.
How do we manage model risk and compliance?
Define intended use, implement access controls, audit trails, explainability where required, bias checks, and operating thresholds. Establish approvals and ongoing monitoring with clear escalation paths.
What causes cost overruns and how do we control them?
Unbounded data movement, oversized clusters, redundant pipelines, and unmanaged retraining. Control with quotas, autoscaling, caching, efficient features, and per-use-case cost attribution.
CTA
If you are ready to operationalize ai analytics across your enterprise, align on outcomes, harden your platform, and scale safely. Let’s discuss a pragmatic roadmap and reference architectures tailored to your constraints.


