

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Turning a promising pilot into a durable, compliant, and cost-efficient AI product is where most enterprises get stuck. The difference between a demo and a dependable system is operational discipline: architecture decisions, data contracts, evaluation rigor, guardrails, and steady iteration. This guide outlines a pragmatic path to scale ai products without losing speed, safety, or control.
Scaling introduces new failure modes: latency spikes, prompt drift, dependency sprawl, and hidden costs from chatty components. With the right lifecycle, teams can move beyond experiments and ship AI that meets SLAs, survives audits, and earns sustained adoption.
Moving from concept to production changes incentives. You optimize for reliability and unit economics, not leaderboard scores. You align model choices with data realities, platform constraints, and governance requirements. You measure results with hard signals: defects prevented, minutes saved, risk reduced.
Introduction
In most organizations, the first wins with ai products come from small proofs of concept: a chatbot answering FAQs, a classifier reducing manual triage, a summarizer speeding up reviews. These demos create momentum but rarely survive scale. The moment real users depend on the system, design shortcuts and missing processes show up as downtime, inconsistent outputs, compliance gaps, or runaway costs.
This topic matters now because AI capabilities are moving faster than enterprise operating models. Cloud teams, data teams, and product teams must converge on a shared blueprint for building and operating AI safely. If you get the lifecycle right, you can add use cases without rebuilding foundations, and you can explain impact in the same terms that govern every other critical system: performance, reliability, cost, and risk.
We will focus on the practical work required to make ai products production-grade: how to select use cases, architect the stack, prepare data, evaluate models, implement guardrails, run MLOps and LLMOps, and monitor outcomes that tie directly to business value.
Understanding the Topic
An enterprise AI product is a software system that exposes AI capabilities as a reliable service with clear SLAs, controls, and accountability. It combines models, data pipelines, retrieval, orchestration, governance, and observability into a cohesive product that solves a defined operational problem and can be audited, scaled, and iterated.
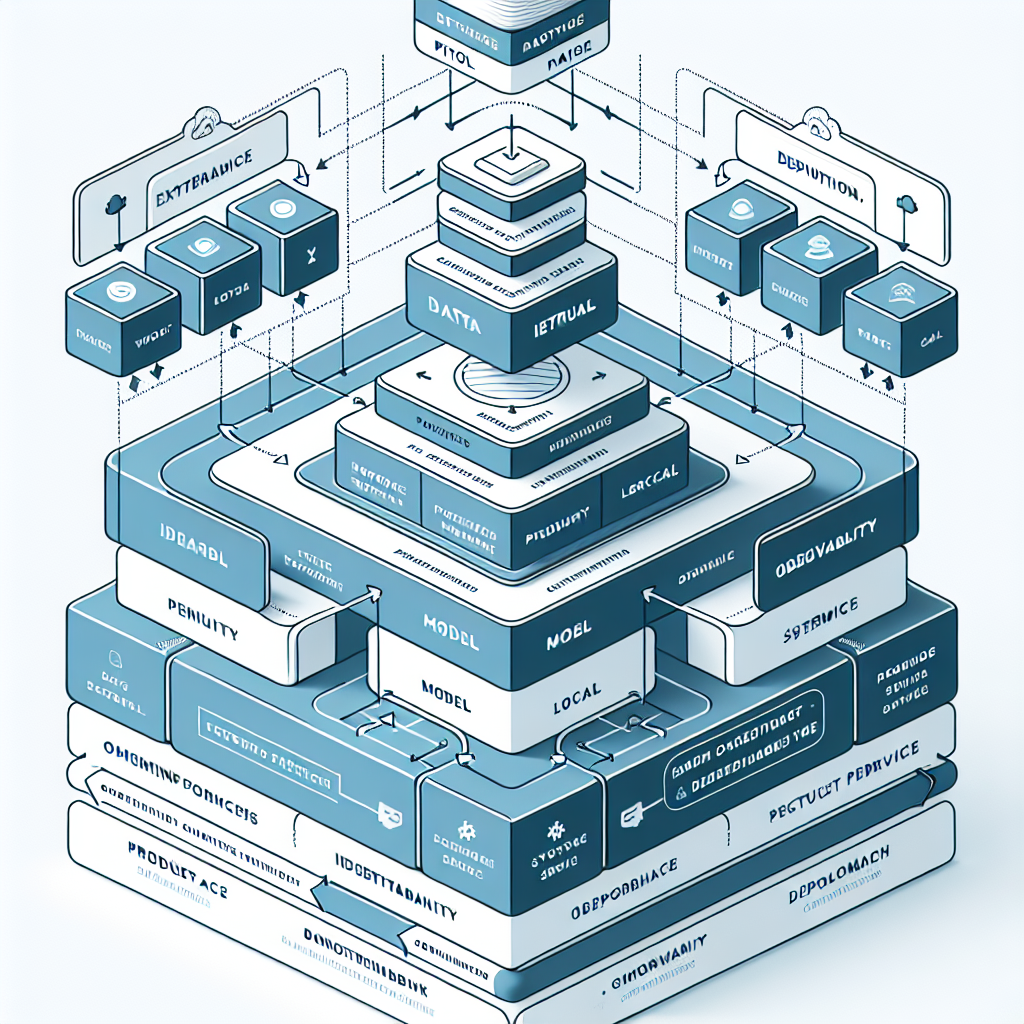
In an enterprise context, the product must operate within boundaries: data residency, access controls, change management, vendor risk, and cost ceilings. This changes how you choose architectures and models. A model that performs well in a benchmark may be wrong for a workflow with strict latency or traceability needs. A library that simplifies prototyping may not fit platform policies. Production choices are shaped by non-functional requirements as much as accuracy.
Beginner-friendly framing helps: think in layers. The product layer defines the user value and workflow. The platform layer abstracts common services like identity, secrets, observability, and deployment. The governance layer enforces standards—evaluation gates, policy checks, and approval workflows. When these layers are explicit, teams can iterate on features without breaking compliance or redoing infrastructure.
How This Works in Practice
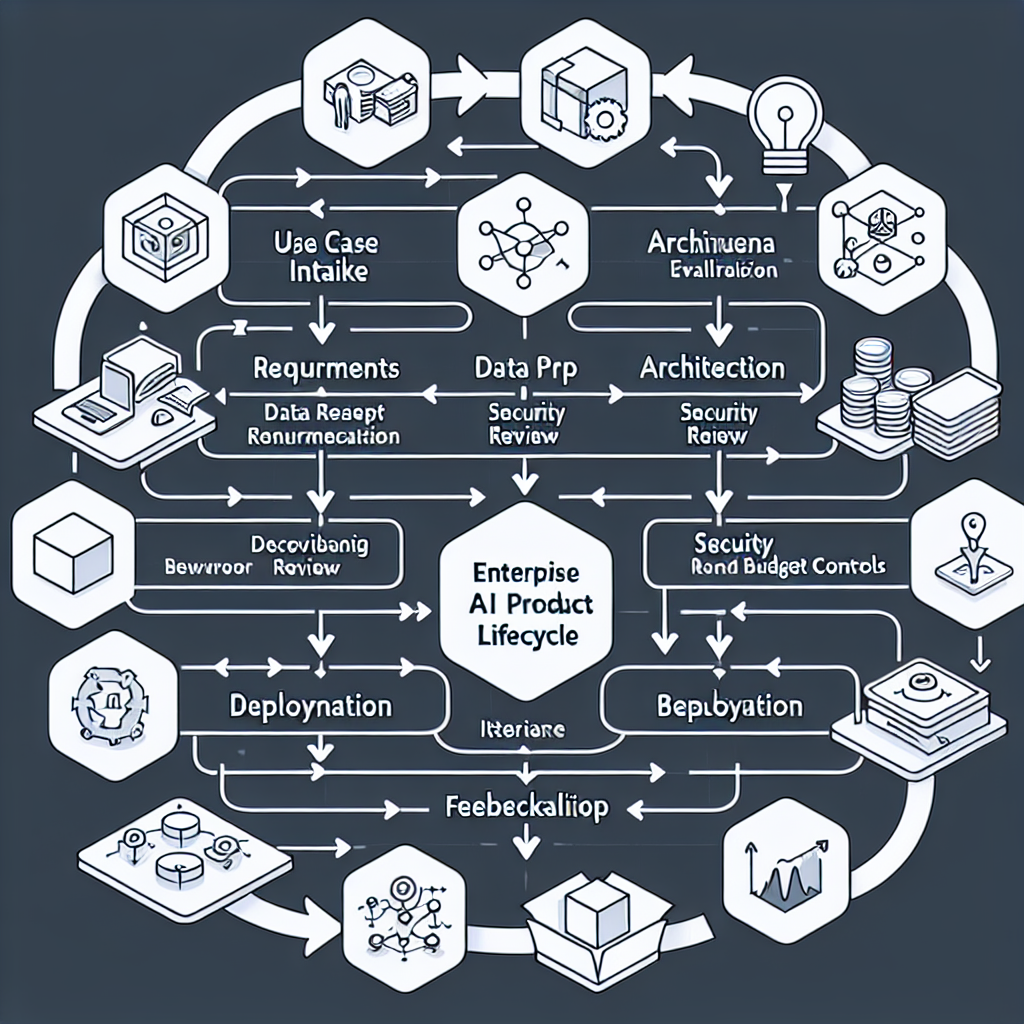
The path from pilot to production is a sequential, testable workflow. Each step adds evidence that the system will perform under real constraints.
1) Use Case Intake and Success Criteria
Start with a narrow, high-friction task. Define measurable outcomes: reduced handling time, fewer escalations, higher first-pass accuracy. Write acceptance tests in business terms and convert them into evaluation cases and canaries.
2) Architecture and System Boundaries
Choose a pattern that fits the problem and constraints: direct model calls for simple tasks, retrieval-augmented generation (RAG) for knowledge-heavy workflows, or fine-tuned models where style or structure must be consistent. Define boundaries up front: what runs in your VPC, what data leaves, and which components are shared services.
3) Data Readiness and Contracts
Catalog sources, define data quality rules, and formalize contracts: schemas, freshness, lineage, and access. For RAG, treat your index as a product—versioned, tested, and monitored. Put PII handling, consent, and retention policies in writing before you load anything.
4) Model Selection and Configuration
Evaluate models against your task and constraints: latency budgets, cost per call, determinism needs, and token limits. Consider hybrid patterns: smaller local models for filtering and routing, large hosted models for generation. Stabilize prompts and templates as code, with versioning.
5) Evaluation: Offline, Online, and Human-in-the-Loop
Build a test set that reflects real edge cases. Use automatic checks (factuality, structure, policy adherence) plus targeted human review for high-risk outputs. Run A/B tests under load and track both quality and system metrics: p95 latency, error rates, and cost per successful task.
6) Security, Compliance, and Risk Controls
Implement input validation, output filters, and policy checks. Gate deployments with approvals for data flows, model vendors, and third-party components. Log all decisions with trace IDs; make audits routine, not exceptional.
7) FinOps and Cost Controls
Set unit economics targets (e.g., dollars per completed task). Enforce quotas, caching, and request consolidation. Instrument token and compute usage at the feature level so cost anomalies are caught quickly and tied to owners.
8) MLOps and LLMOps Pipeline
Automate builds, evaluations, and rollouts. Version prompts, indexes, and models. Use staged environments with canaries and feature flags. Treat regeneration or index refreshes as deployments with change records.
9) Observability and Feedback
Log inputs, retrieved context, model outputs, and decisions. Track signal quality: how often context is relevant, how often outputs pass policy checks. Build simple feedback mechanisms that capture corrections and convert them into new test cases.
10) Guardrails and Failure Planning
Define fallbacks: switch models when latency or quality drops, degrade gracefully to deterministic flows for critical paths, or escalate to humans. Document failure modes and rehearse them.
11) Change Management and Enablement
Publish runbooks and playbooks. Train support and operations. Communicate what the system can and cannot do; set expectations early to avoid misuse.
12) Post-Deployment Iteration
Review metrics weekly: business outcomes, quality, reliability, and cost. Prioritize improvements by impact on unit economics and risk. Keep a steady cadence that compounds value rather than chasing novelty.
Tools and Technologies
Core Platform
Identity and access management, secrets management, service mesh, container orchestration, feature flags, and CI/CD pipelines.
Data and Retrieval
Data catalogs, transformation frameworks, vector databases, document stores, and index builders with versioning and quality checks.
Models and Orchestration
Hosted foundation models, domain-specific models, local inference runtimes, prompt templating libraries, and workflow orchestrators.
Evaluation and Observability
Evaluation suites for structure and factuality, offline test harnesses, A/B testing tools, tracing, metrics, and log analytics.
Security and Compliance
Policy engines, content filters, DLP scanners, audit logging, data residency controls, vendor risk management, and approval workflows.
FinOps
Usage metering, cost attribution per feature, budget alerts, and optimization tools for caching, batching, and model routing.
Examples and Applications
Document Intelligence
Automated extraction from contracts or reports with RAG for policy references. Early teams can start with structured templates and a small index. In production, add validation rules, lineage tracking, and human oversight for high-risk fields.
Customer Assistance
Guided assistants that cite approved knowledge and enforce policy tone. Start with narrow topics and guardrails. At scale, integrate identity, entitlements, and session memory; measure resolution time and escalation rates.
Risk Reviews
Summarize findings and highlight anomalies. Begin with deterministic checks plus model-generated summaries. In mature environments, combine scoring models with retrieval, require citations, and log every decision for audit.
Operational Analytics
Natural language querying over warehouse schemas. Prototype with safe sandboxes. Productionize with query whitelists, cost caps, and schema-aware rewriting; track queries answered and errors prevented.
Tables and Comparisons
Approach Strengths Trade-offs Best When Key Metrics Build Control, custom fit, compliance alignment Higher engineering investment, longer timelines Strict data boundaries, unique workflows p95 latency, unit cost, defect rate Buy Speed, vendor support, quick iteration Less transparency, vendor lock-in risks Common patterns, moderate risk Adoption rate, uptime, vendor SLA Hybrid Balance speed and control Integration complexity, dual governance Multiple use cases, shared services Coverage, change lead time, cost per task
FAQ
How do I know a pilot is ready for production?
When it meets defined acceptance tests under load, stays within latency and cost budgets, passes security and compliance reviews, and has a clear runbook with owners.
Do I need RAG for every use case?
No. Use RAG when answers must be grounded in your content and traceable. For simple classification or structured generation, direct models or fine-tunes may be better.
How should I evaluate outputs reliably?
Combine automated checks for structure and policy adherence with a curated set of human-reviewed cases. Track coverage and update tests as new edge cases appear.
What keeps costs predictable?
Token metering, quotas, caching, batching, and routing to the smallest capable model. Make unit economics visible per feature and enforce budgets.
How do I avoid model drift or prompt decay?
Version prompts and indexes, monitor quality signals, run canaries, and treat content refreshes as controlled deployments with evaluations.
Conclusion
Scaling ai products is a systems problem, not a demo problem. The teams that succeed define clear boundaries, measure the right signals, and iterate with discipline. With a lifecycle that covers architecture, data, evaluation, governance, and cost control, you can ship AI that earns trust and delivers measurable outcomes over time. The payoff is compounding: each new use case builds on a stable foundation instead of starting from scratch.


