
Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Executive Summary
AI intelligence agents don’t fail like traditional services. They drift, hallucinate, overfit to yesterday’s data, and degrade quietly under different traffic mixes. The hardening work lives around the agent: contracts, orchestration, and guardrails that translate fuzzy reasoning into predictable release behavior.
Rollouts become unavoidable because the model’s behavior is an externalized dependency. If upstream changes or context shifts, your production surface changes without a deploy. You need mechanisms that dampen variance, constrain outputs, and protect downstream systems while still letting the agent learn and adapt.
The practical framing: define what the agent may do, how its decisions are observed, and how exposure increases in controlled slices. Build “deterministic scaffolding” around a non-deterministic core. Expect imperfect outcomes and rehearse exits, not just entries.
When production goes sideways, it’s rarely one big failure. It’s the chain: an agent takes a slightly different path, a tool returns a partial payload, a cache injects stale context, a policy lets an edge case through. Hardening is about putting tension in the right places so those edges bend instead of snap.
Introduction
A rollout was green until Monday traffic arrived. The agent that drafts resolutions for support tickets started escalating harmless issues because a small prompt change shifted how it interprets “financial risk.” Queues surged, human review lagged, and average time-to-resolution doubled. No code deploy caused it; the upstream model refresh landed, and our context selection picked different snippets under load. That’s when Hardening AI intelligence agents for predictable production rollouts stopped being a roadmap item and became an operational requirement.
We didn’t have a clean rollback. The agent’s instructions weren’t versioned with contracts, and the evaluation set was too narrow for the week’s variant traffic. It wasn’t catastrophic, but it burned credibility. This surfaced a simple truth about ai intelligence in production: if exposure isn’t sequenced and guarded, variability becomes a user-facing feature. The fix wasn’t a bigger model; it was control on where, when, and how the agent can act.
Non-determinism meets uptime: where variability escapes into user outcomes
In production, an agent is an orchestration problem with a probabilistic core. What looks clever in a demo becomes brittle when token limits compress context, external tools rate-limit, and partial failures force the agent to improvise. You feel it as latency spikes, inconsistent outputs, and downstream systems treating the agent like an unreliable colleague.
Constraints are not optional—they’re guardrails on blast radius. Bound the agent’s authority: define which actions require human-in-the-loop, which are auto-approved, and which are denied by default. Tie outputs to schemas with strict validation; a well-defined contract converts vague reasoning into machine-checkable payloads. The first time you block a clever but non-compliant response, you’ll know you set the right boundary.
Failure modes show up as quiet drifts: the agent starts over-using a tool because latency incentives changed; memory accumulates irrelevant details and steers decisions; an upstream model update changes tokenization and breaks prompt segmentation; the data feed adds new fields that the agent interprets as policy signals. Each is a production incident in slow motion. Hardening means instrumenting for these drifts and shaping the agent’s decision surface so the system fails bounded, not blind.
Cost is a constraint with real teeth. Under burst traffic, your ai intelligence surface can blow through quotas and degrade either quality or throughput. If you don’t price your flows with guardrails—max tokens per path, cutover to fallback behavior when budgets are consumed—you’ll either eat margin or stall queues. The predictable system isn’t the cheapest or the most sophisticated; it’s the one that refuses to do expensive, flaky things when they matter least.
Sequencing rollouts to constrain blast radius and feedback loops
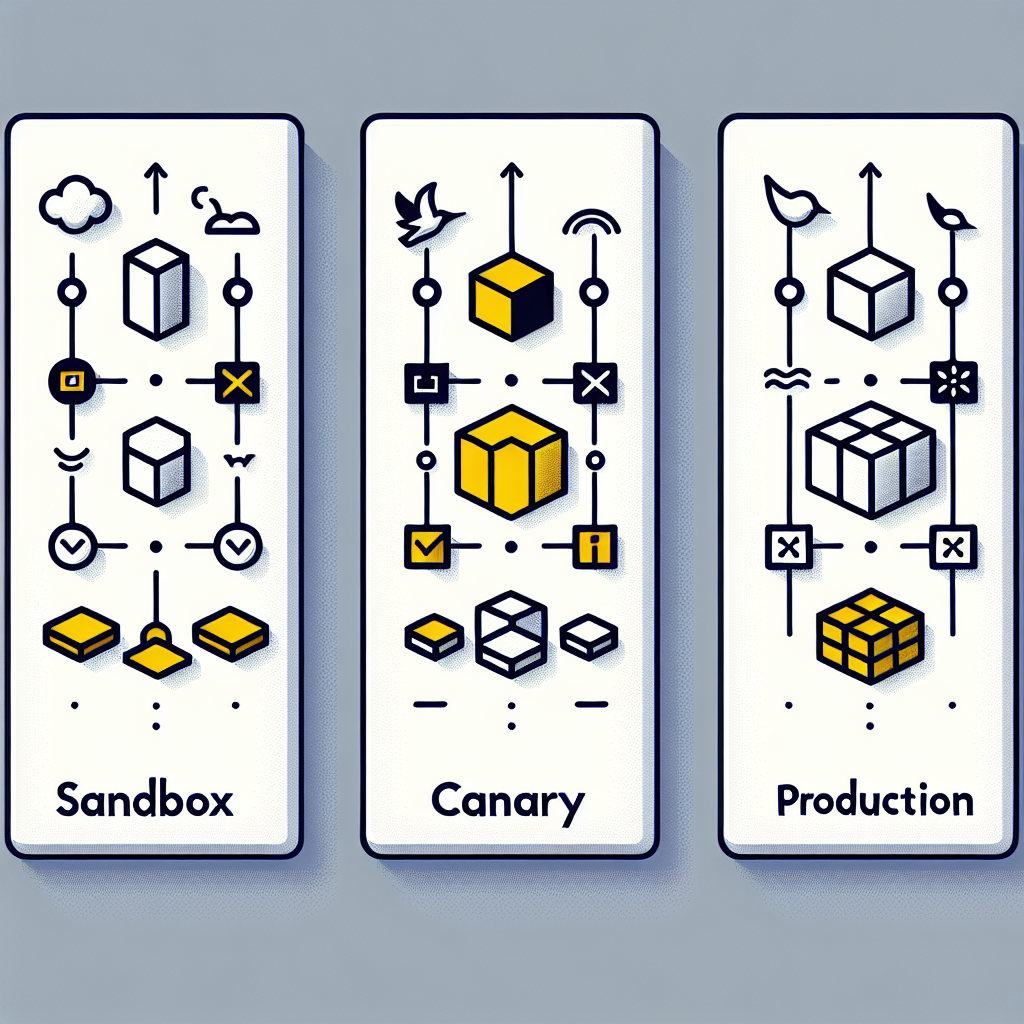
Rollouts touch multiple surfaces: offline evaluation, shadow traffic, canaries, and live exposure. The order matters because each stage reveals a different failure mode. Offline tests catch schema and policy violations against a curated set; shadow mode exposes distribution shifts; canaries measure impact where humans can intervene; full rollout happens only when automated runtime checks and manual reviews align.
Handoffs and friction live in the seams. Data teams gate updates to the evaluation corpus; ML teams version prompts and routing logic; platform teams enforce quotas and circuit breakers; compliance reviews policy adherence. Each delay happens for a reason: the cost or risk of a misstep exceeds the benefit of speed. Accept the slowdown—instrument it. Track where approvals stall, and ask if you can reduce the decision surface with clearer contracts or smaller blast radius.
Dependencies force revisits. A new external API adds latency and intermittent errors; the agent compensates by skipping a tool and guessing. You’ll tighten policies for that path, then loosen them after cache improvements. Expect this pendulum. Sequencing becomes a loop: expose narrowly, observe, patch contracts, expand, repeat. The pressure to move fast never goes away; hardening means you move fast inside guardrails that default to safe.
Teams slow down where evidence is thin. If you can’t show side-by-side outcomes under shadow traffic, canaries halt. If you can’t tie a metric to a user-facing contract, platform can’t set alerts. Give reviewers concrete anchors: schemas for outputs, policies for actions, and differential reports that highlight where the agent deviates from expected decisions. When the debate moves from taste to consequence, decisions unstick.
Tooling choices that constrain behavior and cost
Tools only matter insofar as they enforce decisions. An inference gateway that supports prompt versioning and routing is valuable because it makes a rollback real, not theoretical. A feature flag system is useful when flags can segment exposure by tenant, geography, or traffic class, not just percentage. Observability earns its keep when it traces agent decisions from inputs through tools to outputs, linking errors to contracts rather than raw logs.
Storage layers influence failure modes. If your memory store retains unbounded context, you’ll see subtle steering over time; bounded, task-scoped memory reduces that drift. A policy engine helps when it can evaluate structured outputs against rules before they hit downstream systems. Synthetic evaluation harnesses matter when they can simulate traffic mixes you’ll actually see, not just idealized test cases. None of these are “nice to have” when your goal is predictable rollouts; they are the handles you pull when things wobble.
Workflow orchestration decides whether agents become services or experiments. If the orchestrator can degrade a path—switch to retrieval-only, disable a tool, enforce a simpler prompt—under budget or reliability stress, the agent becomes governable. If not, the model’s behavior leaks directly into production with no pressure relief. Choose anything that gives you control under stress; ignore anything that looks slick but leaves you powerless when traffic hits.
Scenarios that expose hidden coupling and cost spikes
Collections agent tripping on partial payments
An agent negotiating payment plans starts offering discounts because it misreads a partial payment as hardship. The issue isn’t model quality; it’s missing policy context. We added a pre-decision check that requires two signals: verified hardship flag and payment history pattern. Trade-off: stricter policies reduce positive surprises for customers but stabilize outcomes and legal exposure.
E-commerce ranking agent overfitting to promotion tags
Under a weekend promo, the agent boosts items with aggressive tags beyond reasonable relevance. We inserted a contract: the output must remain within a relevance score range anchored to historical click-through, with promotion as a soft influence. Side effect: short-term promo ROI dipped. Gain: consistent user experience, fewer abandoned carts from irrelevant boosts.
Support triage ballooning latency under long threads
Multi-turn memory grew until context windows truncated crucial signals. The agent started asking users to repeat information. We bounded memory by task and introduced a summarization step that produces a structured case file. Unintended consequence: occasionally the summary missed nuance, causing escalations. Mitigation: add a confidence threshold tied to summary completeness before auto-resolve.
Compliance slip from verbose logging
Debug logging captured sensitive fragments from the agent’s reasoning path. We switched to contract-level tracing where only structured fields pass through, with hashes for free text. Trade-off: reduced debuggability. Counterweight: shadow mode traces for a safe subset, replayable offline with elevated access.
Where newcomers and veterans diverge under rollout pressure
The table below isn’t a checklist; it’s a view of how decisions land differently depending on experience under production constraints.
Decision SurfaceNewcomer ImpactExperienced ImpactTrade-off SignalRollout strategySkip shadowing; fast canary to usersShadow until drift patterns emergeSpeed vs. unseen distribution shiftsEvaluation cadenceOne-time offline testsContinuous diffing with golden setsSetup cost vs. detection fidelityFailure handlingRetry and hopeDegrade to deterministic fallbackQuality variance vs. uptimeCost guardrailsBudget as afterthoughtToken and tool caps per pathPeak performance vs. margin controlContractsLoose schemas; free text outputsStrict validation before downstreamFlexibility vs. predictabilityIncident responseModel swap as first moveOrchestration and policy firstPerceived fix vs. systemic fix
Questions teams ask when the agent meets production pressure
How do we monitor quality without labeling everything?
Track contracts and diffs. Use small golden sets for high-risk decisions and aggregate signals (rejections, fallbacks, escalations) as proxies for drift. You won’t measure understanding; you’ll measure consequences.
What if the upstream model changes under us?
Treat the model as an external service. Version prompts and policies, run shadow traffic on candidate routes, and keep a rollback route alive. If behavior shifts beyond tolerance, degrade authority before swapping models.
When do we block versus degrade gracefully?
Block when the contract breaks or policy is violated. Degrade when cost, latency, or tool reliability slips. The distinction keeps risk contained without halting useful work.
How do we handle tool API drift?
Wrap tools with schemas and capability flags. Validate responses before the agent sees them, and kill-switch tools that exceed error budgets. Retrain prompts to prefer robust tools, not the newest ones.
How do we test long-running agent tasks?
Checkpoint state as structured artifacts and evaluate at each boundary. Don’t test the entire monolith; test the decisions the system commits to along the way.
Responsibility shifts to orchestration and contracts
Given how things behave today, this is what quietly changes next: the locus of reliability moves from model choice to the layers that gate, route, and validate agent decisions. The pressure shifts to defining action boundaries, building dependable fallbacks, and sizing exposure so incidents don’t become narratives.
MODEL-CENTRIC -> ORCHESTRATION-CENTRIC -> CONTRACT-CENTRIC -> OUTCOME-CENTRIC


