
The Allure of Generative AI in Advertising Meets Brand Reality
The Allure of Generative AI in Advertising is obvious: faster assets, more variants, lower cost per iteration. The reality is less photogenic. Brand memory is slow to build and easy to dent.
Executive Summary
Generative AI shortens creative cycles and multiplies concepts. Brands need guardrails that keep speed from mutating voice, claims, and compliance.
This piece examines how teams actually adopt, where the friction hides, and why The Allure of Generative AI in Advertising Meets Brand Reality at the moments that matter most: review, policy, and measurement.
- What accelerates and what breaks when AI enters creative workflows
- How to design gates without killing momentum
- Where scale creates unseen costs and brand drift
- Practical patterns for campaigns, not theory
Introduction
Picture a launch week. Brief lands Monday. By lunch, a model has spun dozens of headlines, images, and scripts. By afternoon, you’re chasing approvals while placements open tomorrow. The Allure of Generative AI in Advertising is right there in the timeline—compression that once felt impossible.
It’s trending because channels reward freshness and quantity, while budgets ask for less. Teams need a way to express concepts fast without hiring armies. The Allure of Generative AI in Advertising Meets Brand Reality when that speed runs into positioning, substantiation, and the hard edge of platform policies.
Necessary isn’t the same as simple. If you work inside constraints, you’re weighing throughput against brand memory. You know that one off-tone ad can waste weeks of careful market-making.
Speed runs into brand memory and platform rules
In real environments, generative systems behave like interns with infinite stamina and decent taste—until they don’t. Unchecked, they produce near-miss content that reads fine out of context and wrong in your brand’s context. The early wins are visible; the fractures show up in the backlog of rework and the quiet erosion of trust. Creative speed vs brand gravity
Boundaries appear fast. Voice collapses into generic tropes if prompts overfit to high-level guidelines. Specific claims creep into scripts when the model fills gaps. Imagery drifts into clichés. None of this is dramatic in isolation. Cumulatively, it pushes campaigns toward sameness or risk.
Failure patterns repeat. Teams chase novelty with prompts that ignore constraints. Review queues pile up. Ad platforms reject a fraction of assets, often for the same reasons. The team stops trusting the system or swings too far into manual. Either path cancels the point of automation.
There’s also the time tax. Every new variant is another unit to check for policy, tone, and legal language. At small scale, that’s thrilling. At larger scale, it’s a tide. The Allure of Generative AI in Advertising can outpace the capacity to care for what it creates.
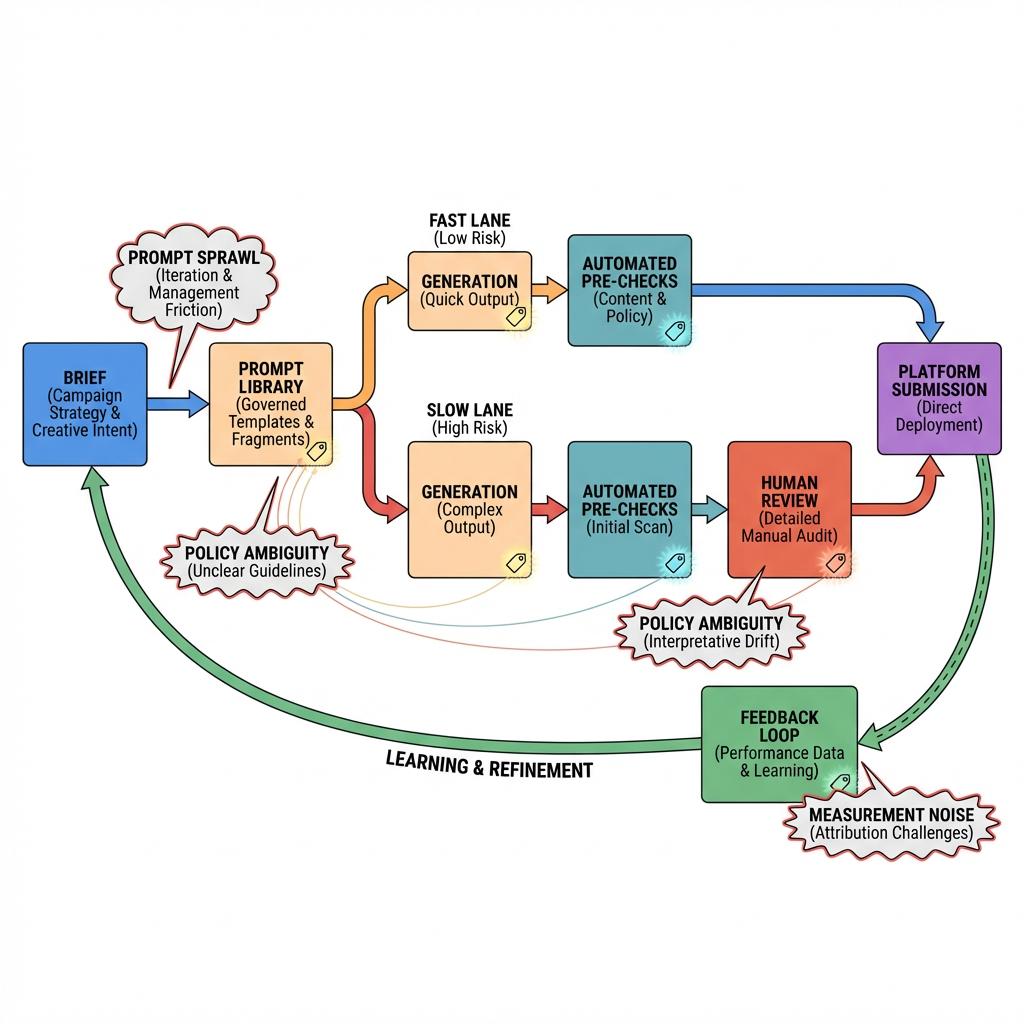
From prompt to governed output: where the wheels wobble
Visual title: From brief to gate to feedback
Implementation usually unfolds in short bursts. You start with a pilot on a contained campaign. A few prompts. A few assets. Quick approvals. It feels good. Then the second order effects arrive.
How the first mile actually works
- A brief becomes a handful of canonical prompts.
- The model generates options across formats.
- A light filter weeds out obvious off-brand outputs.
- A human review tags keepers, fixes tone, and trims claims.
- Assets move into placements and you watch early performance.
Friction shows up at the gates. Filters catch tone but miss implication. Human reviewers see issues late because they’re reviewing too much. The first mile ends with a shaky handoff into production.
What changes when you scale
- The prompt library grows faster than the team’s memory. Conflicts appear.
- “Approved phrasing” lives in scattered places. Drift returns.
- Measurement doesn’t keep up with variant volume. You don’t know what actually made the difference.
- Ad platform rules evolve mid-campaign. A batch flips from approved to rejected without warning.
- Latency and cost quietly rise. More generations plus more checks equals more budget, even if unit cost looked cheap.
At this point, the question isn’t “Can AI generate good creative?” It’s “Can we govern the path from brief to live unit without making speed pointless?”
Required Section A: How this behaves in the wild
Inside a campaign calendar, the model’s advantage is coverage. It can explore angles you wouldn’t have time to try. But exploration without boundaries leaks into production. That’s where brand memory takes the hit.
Boundary one: voice. If your brand stays conversational but not chummy, the model needs examples that show the line. Without them, it slides toward whatever it has seen most. You get content that sounds “almost right,” which is the most expensive kind of wrong.
Boundary two: claims. Generators invent connective tissue. A benign product benefit becomes a promise. If substantiation isn’t embedded in guidance, that invention will find its way into an ad unit and into a rejection queue—or worse, into the wild.
Boundary three: policy and context. Platforms penalize ambiguity. Models generate ambiguity. Safe by design beats safe by cleanup.
Failure pattern one: prompt sprawl. Everyone saves their own best prompts. No one owns the deprecation of bad ones. Quality regresses to the mean.
Failure pattern two: review bottlenecks. Speed at generation shifts pressure to approvals. When timing compresses, reviewers default to over-caution or rubber-stamping. Both hide risk.
Failure pattern three: measurement noise. Variant volume outpaces the ability to isolate drivers. Teams report lifts they can’t reproduce and cut lines that actually worked.
Required Section B: The boring parts that make or break it
Visual title: Gates, not walls
Designing gates that preserve speed
- Treat prompts like code. Version them. Deprecate aggressively.
- Convert guidelines into examples. Don’t tell the model “be authoritative”; show it five short samples that are.
- Add a lightweight pre-check for policy and claims. Toss anything suspicious before human time touches it.
- Route high-risk categories to slower lanes by default. Let low-risk, evergreen content flow faster.
- Close the loop. Tag every approved output with the prompt lineage and keep performance tied to that lineage.
Where friction really lives
- Data hygiene: brief inputs are inconsistent, so outputs are too.
- Legal nuance: it’s not just what you say; it’s how it’s likely to be read. Models don’t feel that nuance unless you teach it carefully.
- Platform feedback: rejections arrive without clear reasons. Teams reverse-engineer rules mid-flight.
- Ops fatigue: the system adds work that looks small in isolation but stacks up: naming, tracking, archiving, learning capture.
Examples and applications
Local lift with a soft slip
A team uses generative copy to tailor ads for neighborhoods. Clicks improve, but one line leans into a local stereotype. It wasn’t malicious. It was plausible. The brand steps back from the campaign for a week to regroup. The net effect: lost momentum and a reluctant return to automation with tighter gates.
Evergreen product, seasonal risk
Creative variants for a seasonal push land fast. A handful of phrases stray into limited-time claims. Half the batch gets rejected on one platform. The other half performs but now you have tracking gaps. The lesson: pre-checks tied to policy language would have saved time.
Language expansion without voice erosion
Translations look fluent. They don’t sound like you. The model followed words, not intent. Adding parallel examples that show rhythm and sentence length fixes half the problem. The other half requires human passes until the examples mature.
Regulated edges
A regulated category attempts templated generation with tight scaffolding. The system behaves in tests, then drifts under deadline. The team reroutes sensitive themes to manual while keeping AI for innocuous elements. Mixed-mode isn’t elegant, but it holds the line.
Tables and comparisons
| Area | Students/Beginners | Experienced Practitioners |
|---|---|---|
| Prompt strategy | Describe tone in adjectives | Show tone with approved micro-samples |
| Guardrails | Manual review only | Layered gates: auto pre-checks, tiered human passes |
| Variant volume | Maximize outputs | Constrain to testable sets tied to hypotheses |
| Measurement | Look at top-line lifts | Track lineage from prompt to performance |
| Failure handling | Patch prompts ad hoc | Version, deprecate, and communicate changes |
| Brand risk | Trust policy to catch it | Prevent at source with examples and forbidden patterns |
FAQ
Do we need a bespoke model to keep brand voice?
Not necessarily. Start with strong examples and clear negatives. If drift persists at scale, consider lightweight adaptation before heavier moves.
How do we stop invented claims?
Embed allowed and disallowed phrases into prompts and pre-checks. Route anything claim-adjacent to a slower lane by default.
What should we measure first?
Tie each asset to the prompt lineage and track approval rate, rejection reasons, and outcome. Without lineage, results blur.
How fast should we scale?
Increase volume only when approval time is predictable and rejection reasons are trending down. Speed without control isn’t speed.
Who owns prompt quality?
Assign ownership. Treat prompts as living assets with version history and clear deprecation paths.
When speed becomes stewardship
The Allure of Generative AI in Advertising Meets Brand Reality when teams accept that velocity creates an obligation to govern. Not heavy governance—just enough to keep creativity aligned with memory and policy.
The progression is simple: explore wide, gate light, learn fast, then narrow to what you can sustain. Creativity scales when stewardship scales with it.