
Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Model performance degrades quietly and release cycles stall when teams rely on ad‑hoc scripts and manual reviews. This guide shows how ai workflows create a measurable operating rhythm: drift is detected before it becomes a customer issue, deployment gates are enforced consistently, and recovery is predictable. The focus is execution—instrumentation, triggers, gates, and rollbacks—so production stays stable while the model evolves. Expect clearer ownership, faster release cadence, and fewer incidents with the same or lower risk. The outcome is a production system that you can audit, trust, and scale.
Introduction
In most production environments, two failures repeat: models drift until someone notices a metric drop, and deployment stalls behind coordination overhead. Teams need a way to move fast without losing control. Solving Model Drift and Deployment Bottlenecks with AI Workflows: A Technical Guide lays out a pattern that replaces one‑off fixes with end‑to‑end ai workflows. It aligns monitoring, training, validation, and release so operational decisions are data‑driven and traceable.
Understanding the Topic
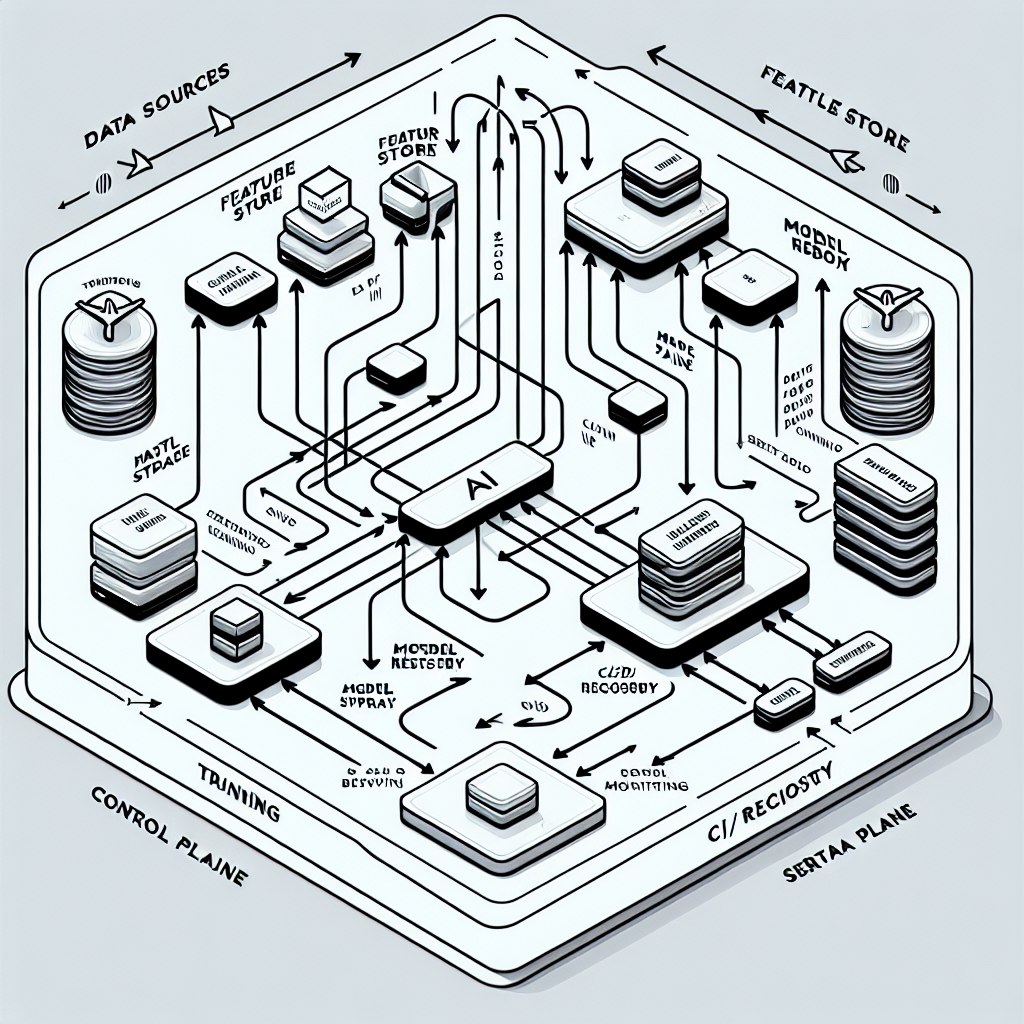
AI workflows are orchestrated, testable pipelines that connect data quality checks, drift monitoring, retraining, evaluation, and deployment under clear policies. They turn model stewardship into a repeatable system with baselines, alerts, approval gates, and safe rollout patterns. In enterprise settings, this means a single source of truth for metrics, explicit service levels for models, and automated controls that match risk posture.
Model drift: what changes and why it breaks production
Drift is the gap between current operating data and the distribution a model learned from. Common forms include data drift (feature distribution shifts), concept drift (label relationship changes), and feature drift (upstream transformations change). Symptoms show up as rising error rates, unstable calibration, or degraded business KPIs. Without baselines and detection logic, drift surfaces late and remediation takes longer than the incident window.
Deployment bottlenecks: where teams get stuck
Bottlenecks often sit at handoffs: inconsistent environments, unclear approval criteria, slow security or compliance checks, and no safe way to test changes in production traffic. Manual gates create variability and delay; emergency fixes bypass process and add risk. A disciplined workflow replaces subjective checkpoints with metrics and policies: if signal meets thresholds, promote; otherwise, triage.
Why workflows beat ad‑hoc scripts
Ad‑hoc code accumulates hidden coupling and uneven quality. Workflows add structure—versioning, reproducibility, dependency isolation, and standardized gates—so failures are localized and recoverable. They support audit trails, cost control, and continuity across teams. The result is fewer late discoveries, smaller blast radius when things go wrong, and faster mean time to recovery.
How This Works in Practice
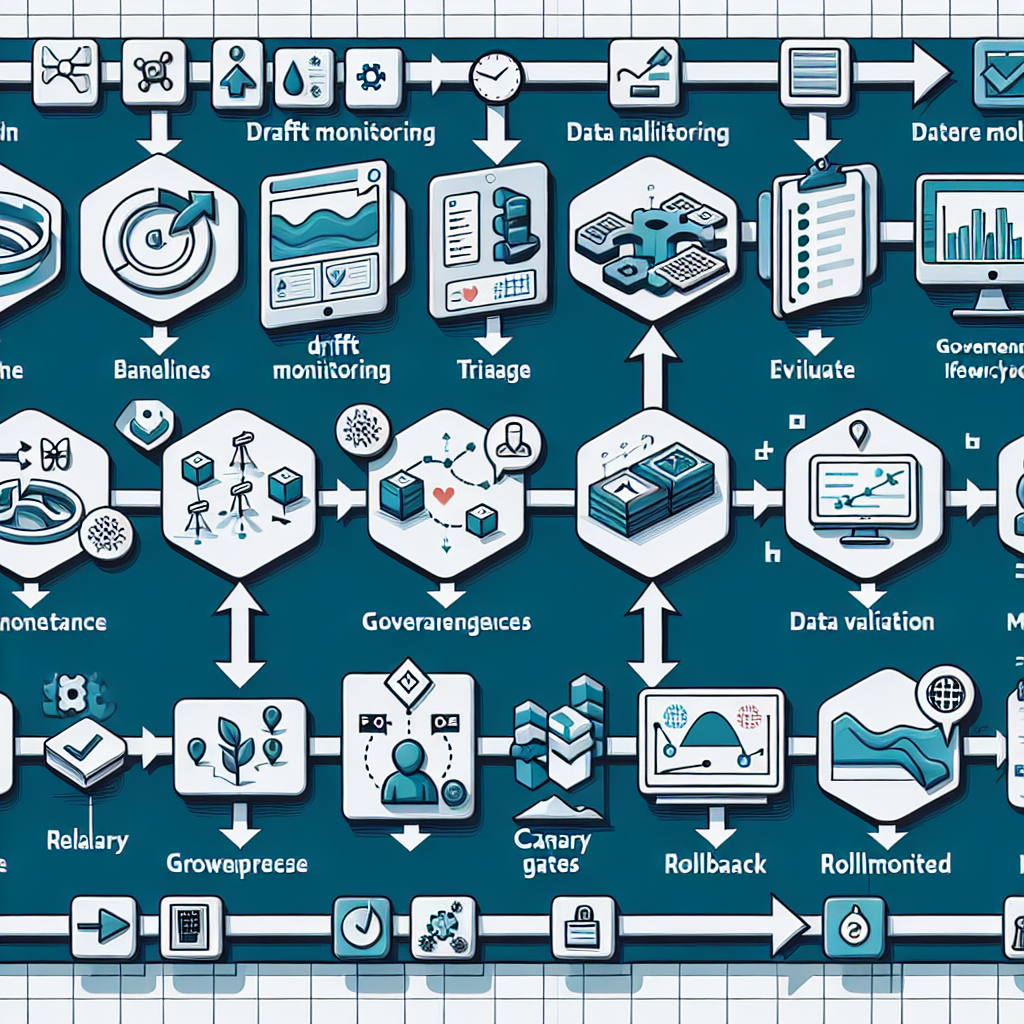
1) Establish baselines and instrumentation
Define reference distributions, business KPIs, and model performance metrics. Log inputs, predictions, and outcomes with trace IDs. Store metrics in a system that supports time windows, slices, and alerts.
2) Monitor for drift continuously
Run scheduled jobs that compare live data to baselines using statistical tests and feature stability checks. Alert on sustained deviations, not single spikes, and include severity tiers to prevent noisy paging.
3) Triage and root cause
Classify incidents: data pipeline issue, feature change, labeling shift, or genuine concept drift. Attach evidence—slices, features, time ranges—to a ticket. Route ownership automatically to the right team.
4) Protect data quality before training
Gate training on schema validation, null thresholds, and transformation checks. Version feature definitions so training and serving stay aligned. Block promotion when feature parity cannot be proven.
5) Retrain with controlled triggers
Use policy to trigger retraining: drift severity, KPI degradation, or scheduled refresh. Keep training deterministic with fixed seeds, environment pins, and reproducible datasets. Track experiments and artifacts.
6) Evaluate against baselines and production slices
Test the candidate model across global and critical slices. Check calibration, stability, robustness, and cost. Compare against the current production model with shadow evaluations.
7) Enforce governance gates
Apply explicit criteria: performance delta thresholds, fairness constraints, and security checks. Require approvals where regulation dictates; log decisions with context. Automate what can be automated.
8) Release safely with progressive strategies
Start with shadow or canary deployments. Limit traffic, monitor live metrics, and define rollback conditions upfront. Promote in steps when signals stay within bounds.
9) Monitor post‑deployment and close the loop
Track leading indicators (input drift, latency, cost) and lagging outcomes (conversions, fraud hits, forecast error). When thresholds breach, trigger rollback or retraining automatically.
10) Learn and improve the workflow
Record incidents, false positives, and operational frictions. Update thresholds, tests, and gates based on evidence. Over time, reduce manual steps and strengthen guarantees.
Tools and Technologies
Orchestration
Airflow, Prefect, Dagster for scheduling, retries, and dependency management.
Experiment tracking and registry
MLflow, Weights & Biases for runs, metrics, and model artifact versioning.
Feature store
Feast, Tecton for feature definitions, online/offline parity, and lineage.
Model serving
KServe, Seldon, TorchServe, managed platforms (SageMaker, Vertex AI) for scalable inference and rollout controls.
Monitoring
Evidently, Arize, WhyLabs for drift and performance; Prometheus/Grafana and OpenTelemetry for system metrics and traces.
Data validation
Great Expectations, Soda for schema checks and quality policies.
CI/CD and environments
GitHub Actions, GitLab CI, Argo CD for build, test, and release pipelines with environment parity.
Policy and governance
Open Policy Agent, metadata catalogs (DataHub, Amundsen) for enforcing gates and auditability.
Examples and Applications
Seasonal pricing: Input distributions shift with promotions, causing over‑discounting. A workflow detects the change early, triggers retraining with recent windows, and rolls out a canary that stabilizes margin.
Fraud detection: Attack patterns evolve, degrading recall on specific segments. Slice‑aware monitoring flags the drift, shadow tests confirm improvement, and a canary release reduces false negatives while containing risk.
Search relevance: New content types alter term frequencies; ranking quality drops. Feature parity checks prevent misaligned embeddings, and progressive rollout recovers click‑through without full downtime.
Inventory forecasting: Supplier variability introduces concept drift. Policy‑driven retraining with cost and service‑level gates improves stock accuracy and reduces expedited shipping spend.
If you are building your first workflow, expect clearer baselines, fewer surprises, and safer releases. If your stack is mature, expect stronger slice performance, faster incident triage, and tighter cost control.
Tables and Comparisons
ApproachBenefitTrade‑offWhen to UseScheduled retrainingPredictable cadenceMay miss fast driftStable domains with slow changeDrift‑triggered retrainingResponsive to changeRisk of retrain churnDynamic environments with clear signalsContinuous trainingAlways currentComplex ops and monitoringHigh‑volume data, strong automationShadow deploymentLow risk evaluationNo user impact dataEarly validation of candidate modelsCanary deploymentControlled real trafficRequires precise rollbackModerate risk changes with good monitoringBlue/green deploymentFast switch, easy rollbackDuplicate resourcesCritical services needing minimal downtime
FAQ
How do I choose drift thresholds?
Start with baselines from historical data and align thresholds to business risk. Use tiered alerts and require persistence over time windows to reduce noise.
How do I prevent retraining loops?
Enforce cool‑down periods, require meaningful performance deltas, and include cost or stability constraints in gates before promotion.
What keeps training and serving features consistent?
Version feature definitions, test parity in CI, and block deployment if online/offline checks fail. Treat feature changes like code releases.
How do I roll back safely?
Define rollback criteria upfront, keep the previous model hot, and automate traffic switch with health checks. Log the event and trigger post‑mortem.
Where should governance live?
Centralize policies in the workflow: metrics, approvals, and compliance checks as code. Keep audit trails tied to releases and decisions.
Conclusion
Structured ai workflows turn model operations from reactive firefighting into a dependable system. You get earlier drift detection, predictable releases, and safer recovery when things change. The payoff is measurable: shorter lead times, fewer incidents, and clearer accountability. Use this guide to implement the minimum controls now and evolve them as your models and risk profile grow.


