
Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Natural language processing has moved from research to the critical path of everyday systems. It works until it doesn’t. This guide focuses on the decisions in between.
Executive Summary
This is a practical map for navigating NLP under constraints: shifting data, latency budgets, limited labels, and real risk.
Expect trade-offs, not magic. A Comprehensive Guide to Natural Language Processing shows where to lean on models, where to fall back, and how to keep outcomes steady as scope expands.
How natural language processing behaves with messy inputs and domain drift
Where failure patterns emerge and how to bound them
An implementation flow that holds up when requirements change
Examples with imperfect results and quick remediation
Simple comparisons between early and seasoned approaches
Introduction
Picture a queue of mixed requests: brief, vague, multilingual, sometimes sensitive. Deadlines are tight. You need routing, extraction, and summarization that won’t collapse under edge cases.
That is why natural language processing is trending again. Not because models suddenly became perfect, but because workflows now depend on them. The bottleneck moved from model accuracy to operational stability.
In real teams, success looks like fewer escalations, faster triage, and predictable failure modes. A Comprehensive Guide to Natural Language Processing aims at this center of gravity: specific decisions that keep quality consistent while capacity grows.
The theme is simple: ship value early, guard the boundaries, and invest where error hurts most. Everything else is optional.
How NLP behaves under pressure: signal, noise, and edges
In controlled demos, text is tidy. In production, inputs are fragmented, coded, sarcastic, or full of domain slang. Natural language processing copes until distribution shifts. Then small assumptions break in big ways.
Concept map of NLP decisions under constraint
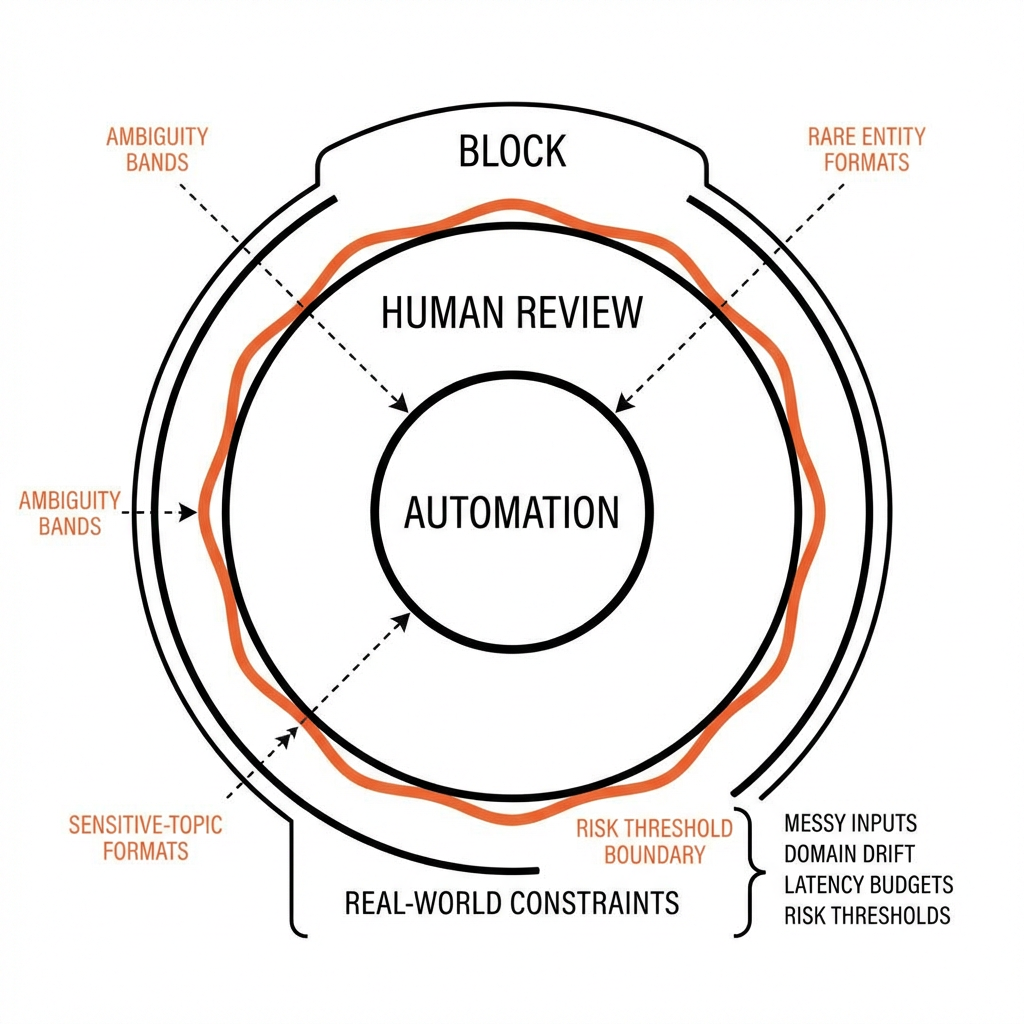
Typical boundaries show up fast:
Ambiguity bands: Multiple interpretations are equally plausible. Forcing a single label increases silent error. If confidence and consensus disagree, defer or request clarification.
Domain drift: Terms change meaning across contexts. Yesterday’s entity list no longer fits. Without targeted refresh, recall sinks and precision looks stable until it suddenly isn’t.
Long-tail inputs: Most cases are easy. A few rare forms cause most incidents. Optimizing for the average hides the risk. Error analysis must weight impact, not frequency.
Multilingual and code-mixed text: Models handle common languages well, but rare scripts or mixed tokens degrade quickly. Detection and routing often beat monolithic coverage.
Numbers, units, and structure in text: Free text carries structured facts. Extraction works until one-off formats appear. Templated fallbacks and pattern checks reduce surprise variance.
Generative tasks under constraints: Summaries that read well may miss a key decision. Hallucinations sneak in when prompts or context windows are misaligned with the task’s boundary conditions.
Latency vs. accuracy: Larger models or deeper pipelines help on hard cases but strain budgets. Split the traffic: fast path for easy inputs, slow path for risky ones.
From prototype to production: the pragmatic NLP path
Field-tested NLP rollout flow
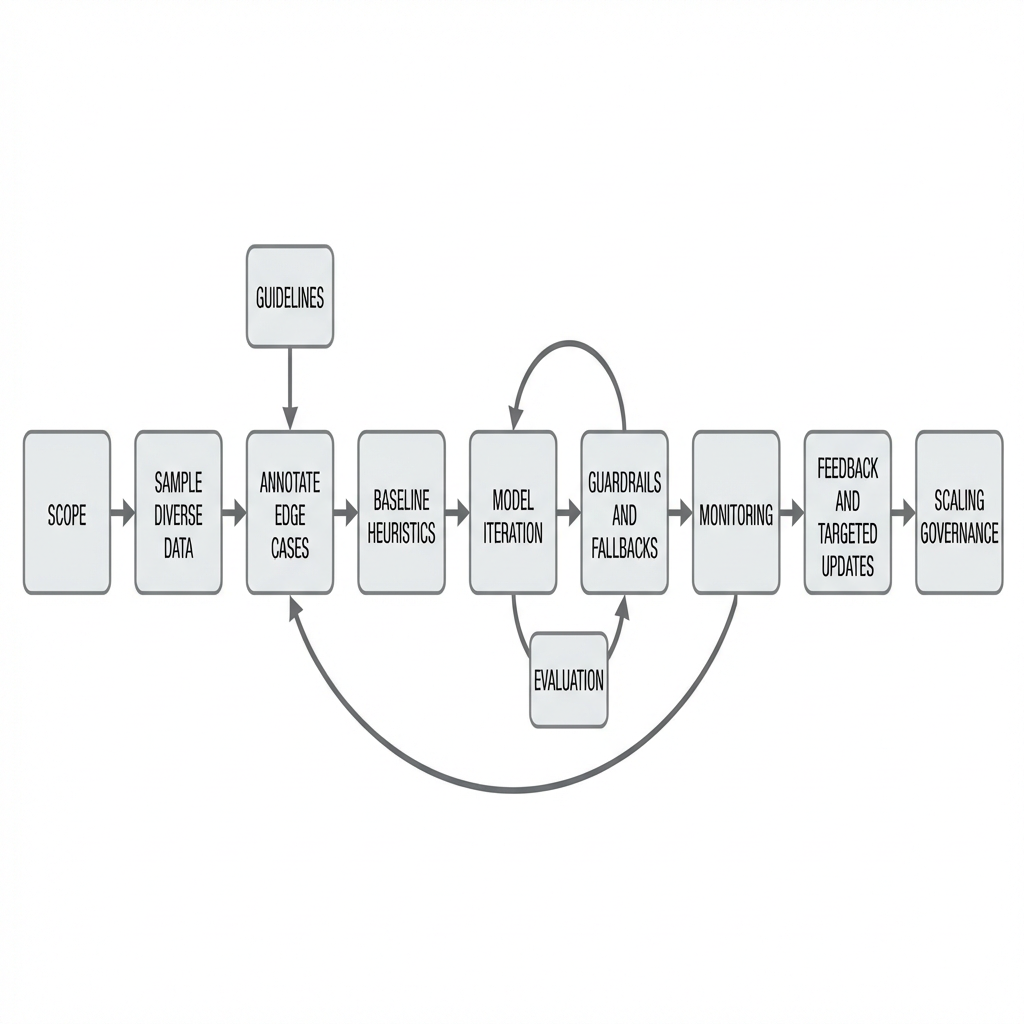
Start with scope and risk. Define what must be right and where a mistake is tolerable. Tie evaluation to consequences, not abstract metrics.
Sample first, then label what matters
Pull a small, diverse slice of real inputs. Annotate edge cases before spending on the long tail of easy items. Write short, unambiguous guidelines. Revise after the first disagreement.
Ship a simple baseline on day one
Rules, small models, or keyword heuristics can stabilize the pipeline. Measure with outcome-oriented slices: critical vs noncritical errors, not just overall accuracy.
Iterate where error hurts
Cluster failures by impact. Fix one class at a time: add features, adjust prompts, enrich context, or create lightweight classifiers to gate generation. Add guardrails and fallbacks early.
Control the blast radius
Implement confidence-aware routing. Low risk goes auto. High risk moves to review or asks for clarification. Log overrides. Make rollbacks cheap.
Monitor reality, not just dashboards
Deploy counters for drift signals: new tokens, longer inputs, unseen entity formats. Sample for manual review. Add feedback loops that retrain, reweight, or revise prompts sparingly.
Scale without breaking shape
As volume grows, caching, batching, and asynchronous steps help. But the real scaling work is governance: versioned guidelines, change logs, clear ownership of categories and exceptions.
Examples and applications with honest edges
Routing mixed requests
A triage model works well on clear asks but stumbles on brief or sarcastic notes. Introducing a “needs more info” class reduces misroutes, though throughput dips. Adding a short clarification template recovers speed.
Extracting fields from irregular documents
Most layouts parse cleanly. Atypical formats cause missing fields. A hybrid approach—light template checks plus model-based extraction—catches more, but introduces false positives on totals. A simple cross-check against computed sums reduces that error.
Summarizing long notes
Summaries read fluent yet omit a critical decision. Enforcing a checklist of must-have items and verifying presence with a secondary check reduces omissions. The trade-off is longer processing on those cases.
Screening sensitive content
The classifier overflags edge humor. Calibrating with context windows and adding a defer-to-review band cuts false positives. Some borderline content slips through, so audit sampling remains mandatory.
Beginners vs experienced practitioners: where approaches diverge
AreaBeginnersExperiencedData prepLabel many easy casesLabel edge cases firstModel choicePick largest by defaultChoose per slice and riskEvaluationChase a single metricTie metrics to consequencesError handlingTrust averagesRoute by confidence and impactDeploymentOne path for allFast path + review pathScalingAdd computeStabilize guidelines and fallbacksEthics & riskAfterthoughtBaked into gates and audits
FAQ
Do I need a huge dataset to start?
No. A small, diverse slice with clear guidelines beats a large set of easy examples.
When do rules beat models?
For invariant patterns, guardrails, and sanity checks. They also make failures legible.
How should I evaluate beyond accuracy?
Measure critical errors, near-miss rates, and performance on high-impact slices.
What about multilingual inputs?
Detect and route early. Separate paths often outperform a single universal model.
How do I keep models fresh without constant retraining?
Use drift signals, targeted relabeling, and small updates focused on error clusters.
Ownership is shifting from models to outcomes
The pressure is moving away from proving a model is smart toward proving the system is safe, steady, and legible when inputs change.
Natural language processing succeeds when teams own the boundary: clear scopes, graceful fallbacks, and monitoring that sees trouble early. That’s the work that lasts.


