

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Agents are leaving the lab. GPT 5.5 makes it obvious. Autonomy is usable now, but only if you respect the boundaries that keep systems stable.
Executive Summary
The Agentic Era and GPT 5.5 isn’t about bigger prompts. It’s about handing tasks to systems that plan, call tools, and negotiate uncertainty. That unlocks leverage, but also new failure modes.
This guide walks through how agentic systems behave under pressure, the sequencing that prevents blowups, and what changes the minute you scale past a demo.
See where GPT 5.5 agents thrive and where they stall
Map a rollout path that contains cost, latency, and surprise
Adopt guardrails and signals that keep autonomy aligned
Compare how beginners and seasoned operators make trade-offs
Introduction
You hand an agent a ticket queue at 5 p.m. It clears half by 5:07, then locks itself on three edge cases, pings an API out of quota, and leaves two items half-finished. Everyone wants the speed. No one wants the mess.
The Agentic Era and GPT 5.5 changes the texture of work. Models plan, call functions, maintain short-lived memories, and coordinate steps without constant prompting. That’s why it’s trending. The results look like skilled assistance, not autocomplete.
Harnessing GPT 5.5: Your Guide to Thriving in the Agentic Era is about operating under constraints. It’s becoming necessary because the gap between a clever demo and a dependable system is, frankly, where most projects die. The teams that win treat autonomy as an operational property, not a feature flag.
Autonomy that behaves in the real world
In production, GPT 5.5 agents act like junior teammates with excellent recall and uneven judgment. They move fast on routine steps, stall on ambiguity, and misprice risk when the context is stale or incentives are unclear.
Boundaries first. The agent’s world must be smaller than your blast radius. Constrain tools, set time budgets per task, and cap recursive depth. When agents over-plan, they burn tokens and time. When they under-plan, they miss prerequisites and ship partial work.
Failure patterns are consistent. Loops disguised as diligence. Tool thrashing when responses conflict. Silent partials where the agent stops after an apparently successful call and leaves work in a limbo state. Fragile memory that confuses tasks across threads if you let context bleed.
Latency is a systems issue, not just a model issue. Every tool call adds overhead. GPT 5.5 improves planning, but planning is still expensive if the agent insists on reevaluating with every micro-step. Cache obvious decisions. Precompute schema. Keep the stack tight.
On accuracy, expect varied terrain. With structured APIs, the agent is reliable. With long unstructured context, drift increases after two or three hops without anchor points. Without fresh data, it confidently reasons to the wrong place. The fix isn’t a bigger context window. It’s strong retrieval policies and explicit stop conditions.
Cost control is governance. Track spend per task, not per call. Cap maximum actions. Reward fewer, higher-quality tool invocations. If an agent cannot justify a call, it waits or asks. That small dynamic changes outcomes more than most prompt tweaks.

A resilient path from demo to dependable agent
Start with a bounded job, not a category of work. “Prepare a draft handoff” beats “own the queue.” Tie success to a crisp artifact or state change that’s easy to evaluate.
Define affordances before intelligence
List what the agent can touch. Tools, data scopes, external systems. Nothing else. Give it the verbs, then the goal. Bake in deny-by-default. Assume the agent will try clever routes. It will.
Establish signals that matter
Set a small set of reinforcement signals that reflect reality. Completion checks, side-effect validation, human acceptance rate, time-to-first-correct. Avoid vanity metrics like raw token usage alone. Tie rewards to outcomes you’d defend in a postmortem.
Bake in friction where it saves you
Add confirmations on high-impact actions. Rate-limit tools that can cause churn. Use drafting and propose-then-apply for irreversible changes. Let the agent ask for help rather than guess when it detects ambiguity above a threshold.
Instrument the run, not just the result
Log the chain of thought substitutes you are allowed to capture, function arguments, and decision branches. You’re not collecting for curiosity. You’re looking for repeated bad paths to prune and good paths to accelerate with templates.
Shadow, then gate
Run the agent in parallel with humans. Compare decisions. When deltas shrink and trend favorable, move to supervised execution with rollbacks. Full autonomy comes last, and even then, constrain by policy. Reversibility is your safety net.
Scaling changes the problem
At scale, the variance matters more than the mean. Rare failures become daily. Tool quotas become ceilings. Latency tail grows. You’ll need queues, backpressure, and decay of stale tasks. Caching becomes a first-class feature. Evaluation becomes continuous.
Examples and applications that survive contact
Ops triage. An agent reads incoming issues, classifies them, and drafts remediation steps. It shines on repetitive cases, but flags degrade when logs are noisy. Add a step that asks for one missing datum instead of guessing. Throughput climbs, rework drops.
Data hygiene. The agent proposes schema mappings and validation rules. Works well with clear targets, but misfires on edge cases with legacy fields. Snap in a rule that requires confirmation on any destructive alteration and a sandbox to test proposed transforms.
Content-to-action workflows. The agent drafts summaries, generates follow-up tasks, and schedules reviews. It sometimes over-creates tasks when confidence is low. Solve it by capping task fan-out and requiring consolidation before scheduling.
Customer follow-ups. The agent composes tailored messages based on history. It can adopt the wrong tone if sentiment is misread. Insert a quick-look prompt asking the agent to state the inferred tone and confidence. If low, it requests a sample response from a library.
Internal knowledge. The agent drafts answers with citations from internal documents. Works until documents go stale. Add freshness checks on sources and penalize answers without citations. It will prefer current, linked content over stale memory.
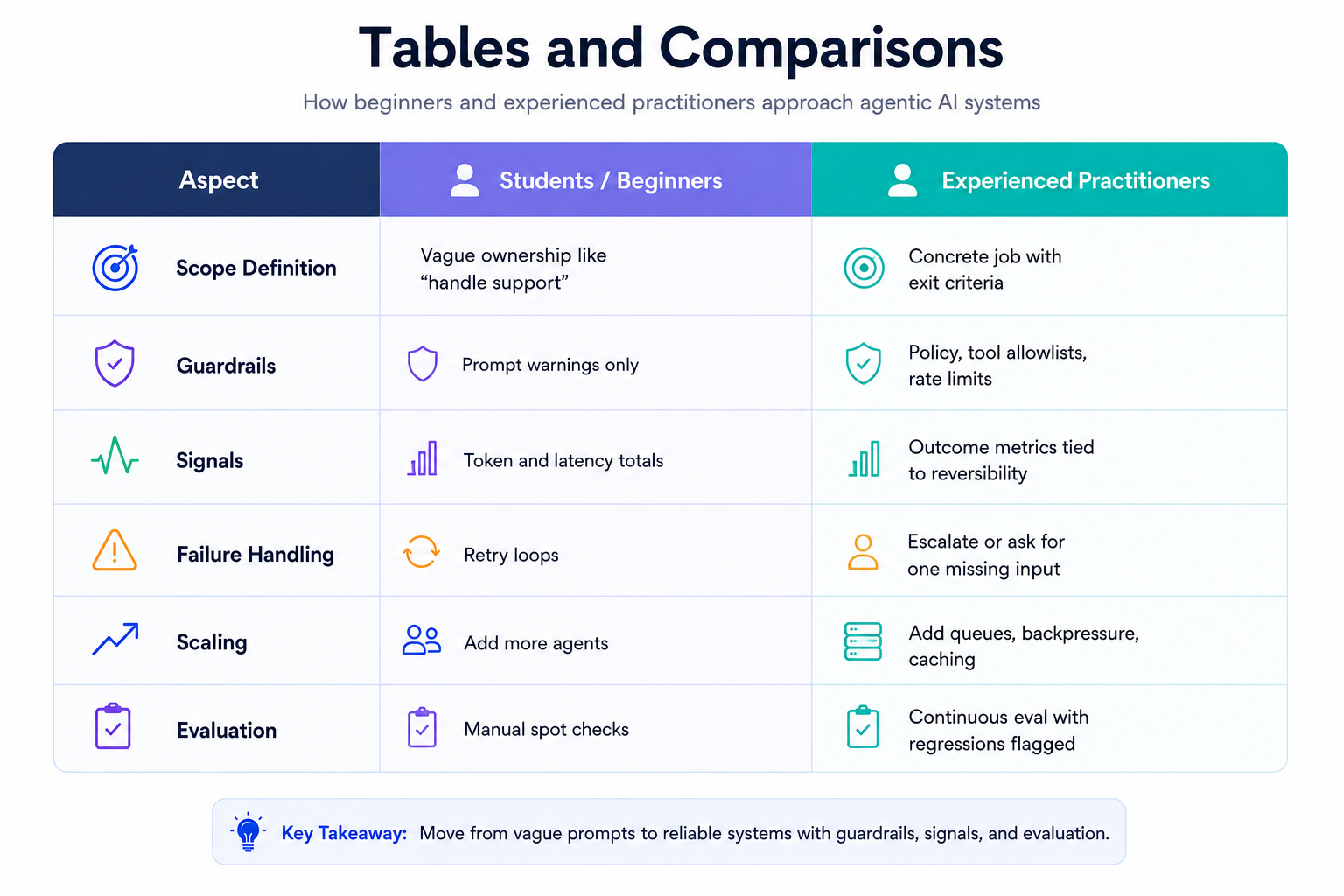
Tables and comparisons
Aspect Students/Beginners Experienced Practitioners Scope Definition Vague ownership like “handle support” Concrete job with exit criteria Guardrails Prompt warnings only Policy, tool allowlists, rate limits Signals Token and latency totals Outcome metrics tied to reversibility Failure Handling Retry loops Escalate or ask for one missing input Scaling Add more agents Add queues, backpressure, caching Evaluation Manual spot checks Continuous eval with regressions flagged
FAQ
How do I pick the first use case?
Choose a bounded task with clear outputs and cheap rollbacks. Avoid edge-case heavy work until you have guardrails.
How do I control cost without neutering the agent?
Cap actions per task, price tool calls, and reward fewer high-value steps. Cache stable decisions. Monitor spend per outcome, not per call.
What metrics catch silent failures?
Track partial completion rates, tool-call justification presence, and post-action state validation. If state didn’t change as expected, treat it as a failure.
What if the model is confidently wrong?
Require citations for claims, add freshness checks, and route low-confidence or no-citation cases to review. Penalize unsupported answers.
How do I handle sensitive data?
Minimize exposure by scoping tools and data access. Mask inputs where possible and log only what you must for audit and debugging.
Responsibility shifts from clever prompts to durable policies
As GPT 5.5 agents take on real work, the pressure moves from crafting one perfect prompt to designing constraints, signals, and recovery. The wins come from policy and instrumentation more than novelty.
That’s the real Agentic Era and GPT 5.5 shift. We stop proving that autonomy can work and start proving it can fail safely, learn fast, and stay within bounds when the unexpected shows up.


