

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
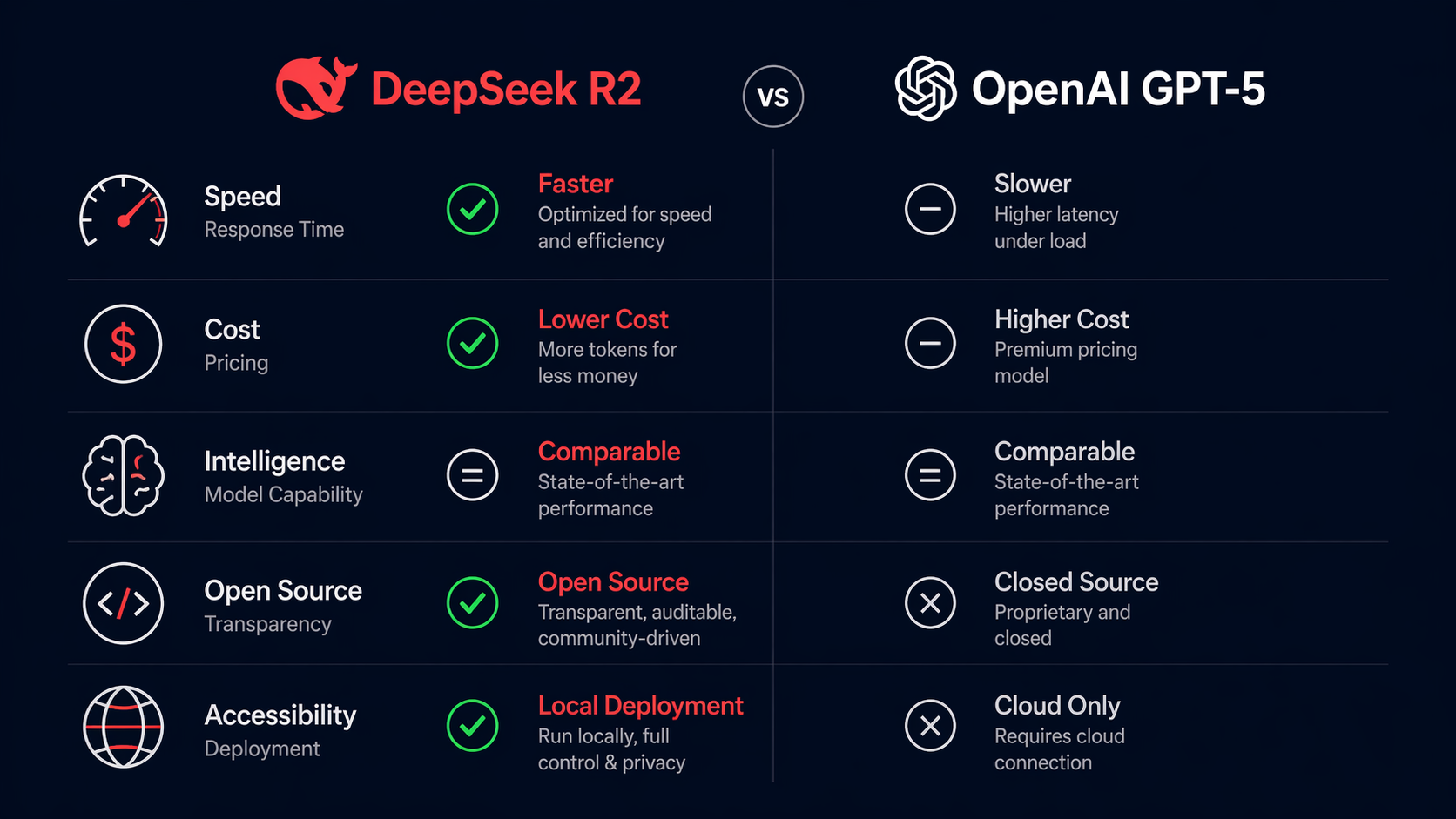
Quiet rumors, louder benchmarks, shifting budgets. That’s the mood when a challenger model shows up with teeth.
DeepSeek R2 Is Coming And It Might Be the First AI Model to Genuinely Scare OpenAI
Executive Summary
DeepSeek R2 is entering the conversation not as a novelty, but as a potential reshuffle of cost, quality, and control. If it lands, decisions move from marketing chatter to SLO math.
This piece maps how a switch actually behaves under workload, where it breaks, and what to change before you flip traffic.
Understand the cost-quality-latency triangle when evaluating DeepSeek R2.
See where models commonly fail under real prompts and messy data.
Learn a stepwise rollout that contains risk and shortens time-to-proof.
Compare beginner vs experienced approaches to migrations and guardrails.
Introduction
A familiar scene. Support tickets spike. Product wants sharper answers with fewer escalations. Finance wants the inference bill to stop climbing. Engineering wants fewer brittle patches. Then a headline hits your chat: DeepSeek R2 Is Coming And It Might Be the First AI Model to Genuinely Scare OpenAI.
Under the noise, the topic is simple. A new foundation model promises strong reasoning at a friendlier cost curve. The hype cycle starts. Procurement pokes. Leadership asks for a position. DeepSeek R2 trends because the market is hungry for a model that moves the frontier without forcing teams to rebuild their stack.
It’s becoming necessary because the edge now lives in operational details. If DeepSeek R2 reduces variance on hard prompts, or holds quality under longer context, or improves cost per acceptable output, it shifts how teams budget, route, and guard. The question isn’t who wins a leaderboard. It’s whether your stack wins fewer incidents and achieves tighter SLOs.
Reality check: where DeepSeek R2 bites in production, and where it breaks
In real environments, a model swap is not a toggle. It is a rebalancing of latency budgets, cache hit rates, prompt contracts, tool-call schemas, and safety posture. DeepSeek R2 will slot into those constraints, not rewrite them.
Boundaries show up fast. Long prompts look good in demos, but context windows saturate and attention drifts. Retrieval pipelines that were calibrated to another model’s preferences may overfeed or underfeed. Tool usage that seemed deterministic may get chatty or terse, breaking downstream validators.
Failure patterns are rarely spectacular. They are small and expensive. Slightly higher refusal rates on compliance prompts. Occasional hallucinated citations that pass surface checks. Inconsistent function arguments that remain syntactically valid but semantically wrong. Latency spikes under specific input shapes that don’t appear in synthetic tests.
Cost is nonlinear. A cheaper per-token price does not guarantee lower spend if prompts expand, retries climb, or guardrails add extra hops. Lower variance can reduce retries and net out ahead. Higher variance can erase list price advantages. The only measure that matters is cost per accepted answer under your acceptance thresholds.
Safety shifts too. A model that is more capable at reasoning can also find creative paths around naive redaction and filtering. If DeepSeek R2 is more literal with instructions, you may see fewer jailbreaks. If it is more imaginative, you need stronger policy checks and post-processing.
Finally, routing. You might not replace your incumbent outright. You might route edge cases, long-form tasks, or safety-sensitive prompts to one model and keep the rest on another. The winner is not a model. It is the portfolio that achieves stable outcomes at stable cost.
From demo to duty cycle: how a switch actually rolls out
Start with your own prompts, not public benchmarks. Pull a representative slice that includes ugly inputs, adversarial phrasing, and low-frequency formats. Run blind evals with clear acceptance criteria. Record not just scores, but reasons for rejection. Reasons drive fixes.
Next, build a controlled pilot. Limit user exposure, log everything, and preserve a fallback. Define SLOs that matter to your context: timeouts, refusal rates, citation accuracy, tool-call validity, and downstream impact. Attach budgets to each, not just targets.
Guardrails come third. Don’t import a generic policy set. Base it on the failure reasons you observed. If DeepSeek R2 tends to shorten answers too aggressively, you’ll need prompt contracts that enforce structure and depth. If it tends to speculate, you’ll need grounded retrieval checks before outputs move downstream.
Then align tool schemas. Many production failures trace back to misaligned function signatures. Tighten argument names, add required fields, and create deterministic prompts for function choice. If the model supports tool confidence, log it. It’s a useful routing signal.
Observability isn’t optional. Capture input shape, token counts, latency percentiles, retry loops, and post-processing edits. Build dashboards you actually read. When DeepSeek R2 performs better, know by how much. When it regresses, know exactly where.
At scale, friction changes. Caching strategies that worked at small volume may degrade if prompts become more personalized. Rate limits become a bottleneck during traffic bursts. Cost anomalies emerge from a handful of pathological inputs. Plan a kill switch per route, not per service, so you can isolate and iterate without freezing everything.
Examples and applications that expose the edges
Document QA with retrieval. On paper, DeepSeek R2 might handle long context well. In practice, retrieval rankers can flood the model with near-duplicates. You see confident but stale answers because the freshest chunk fell below the fold. Fixes include tighter filters, shorter but denser chunks, or instructing the model to cite only recent spans.
Agent-style orchestration. A model switch may change how often the agent decides to call tools. If DeepSeek R2 is more decisive, it may reduce back-and-forth and cut latency. If it is more exploratory, it may try multiple tools, increasing cost and the chance of conflicting writes. The remedy is clearer termination criteria and stricter function selection prompts.
Classification with high stakes. Seemingly simple labels hide tricky edge cases. A new model may improve overall accuracy but misclassify a rare, sensitive category more often. If you only look at averages, you’ll ship regressions. Weighted evals and per-class thresholds prevent that blind spot.
Summarization under constraints. When asked to preserve specific fields or formats, some models compress too aggressively and drop required elements. If DeepSeek R2 respects structure better, you can simplify post-processors. If not, enforce schema with template-anchored prompts and hard validators.
What changes with experience
The gap between beginners and experienced practitioners shows up in where they spend attention. Here’s a quick comparison to stress the operational differences.
TopicBeginnersExperienced PractitionersModel selectionPick the best leaderboard scoreOptimize for cost per accepted output under real promptsEvalsOne benchmark suiteTask-specific, adversarial, and failure-reason taggedPromptingVerbose instructionsContracts with explicit structure and constraintsSafetyGeneric filtersPolicies mapped to observed failure modesCost controlTrack list priceBudget per route with retry and guardrail overheadLatencyAverage latency focusP95 targets with fallbacks and cache strategyRollbacksGlobal switchPer-path kill switches and staged exposureObservabilitySuccess rate onlyInput shape, token counts, variance, and edit distanceContractsLoose assumptionsVersioned schemas for tools and outputs
FAQ
Will DeepSeek R2 lower my costs immediately?
Only if your prompts and retries don’t expand. Measure cost per accepted output, not list price.
How do I know if quality really improved?
Run blind evals on your data with clear acceptance rules and tag failure reasons. Look beyond averages.
Can I replace my incumbent model outright?
Maybe. Many teams route by task type, risk level, or context length instead. Portfolio beats monoculture.
What breaks most often during migrations?
Tool-call schemas, safety posture, and edge-case prompts. Fixes usually involve clearer contracts and better observability.
How should I handle safety and compliance?
Base policies on observed failures, add post-processing checks, and keep auditable logs of decisions.
Rising pressure moves from the model to the runbook
If DeepSeek R2 lands as promised, the strategic edge won’t be picking the right logo. It will be the discipline to operate under constraints, capture variance, and react fast when reality drifts.
That shift is healthy. It rewards teams that build clear contracts, honest evals, and boring rollbacks. The scary part isn’t a new model. It’s whether your runbook is ready for one that changes the math.


