

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
What gets a v1 out the door is never what carries you at 10x traffic. Google Cloud can help with both if you work with its edges, not against them.
Executive Summary
Fast paths are real on Google Cloud: managed models, serverless serving, elastic data. Speed turns into risk when quotas, latency, and cost thresholds collide under load. This piece maps the trade space.
You’ll see where the stack accelerates early velocity, how friction shows up in real environments, and how teams pivot when usage and scrutiny spike.
Prototype-to-prod flow that keeps optionality open
Cost and latency cliffs to watch from day one
Patterns for scaling without constant rebuilds
What beginners try versus what operators ship
Introduction
Someone on your team just wired a rough demo that works on a subset of data. It answers questions, generates drafts, or flags issues. People get excited. Then the real asks arrive: privacy, uptime, lower latency, lower cost. The gap between demo and dependable service shows fast.
That’s where Google Cloud has become a common path. Not because it’s magic. Because it offers a coherent place to keep data close, experiment with models, and deploy without reinventing infrastructure. How Google Cloud’s AI tech stack powers today’s startups isn’t about picking a single product; it’s the choreography between storage, training, inference, and monitoring that either compounds speed or compounds risk.
It’s trending because generative and predictive features now land inside every product surface. It’s becoming necessary because teams need to move quickly without hard-coding decisions they’ll regret under real traffic and budgets.
Where the stack helps and where it bites under pressure
In practice, the early win is managed everything. Teams lean on Google Cloud for hosted notebooks, ready-to-use models, vector indexing, and serverless endpoints. You ship a thin service fast. The bite shows later: quotas you didn’t notice during demos, latency spikes when data crosses regions, GPU scarcity during training windows, and cost cliffs when a background job becomes user-facing. Concept diagram: Pressure points in a startup’s AI path on Google Cloud.
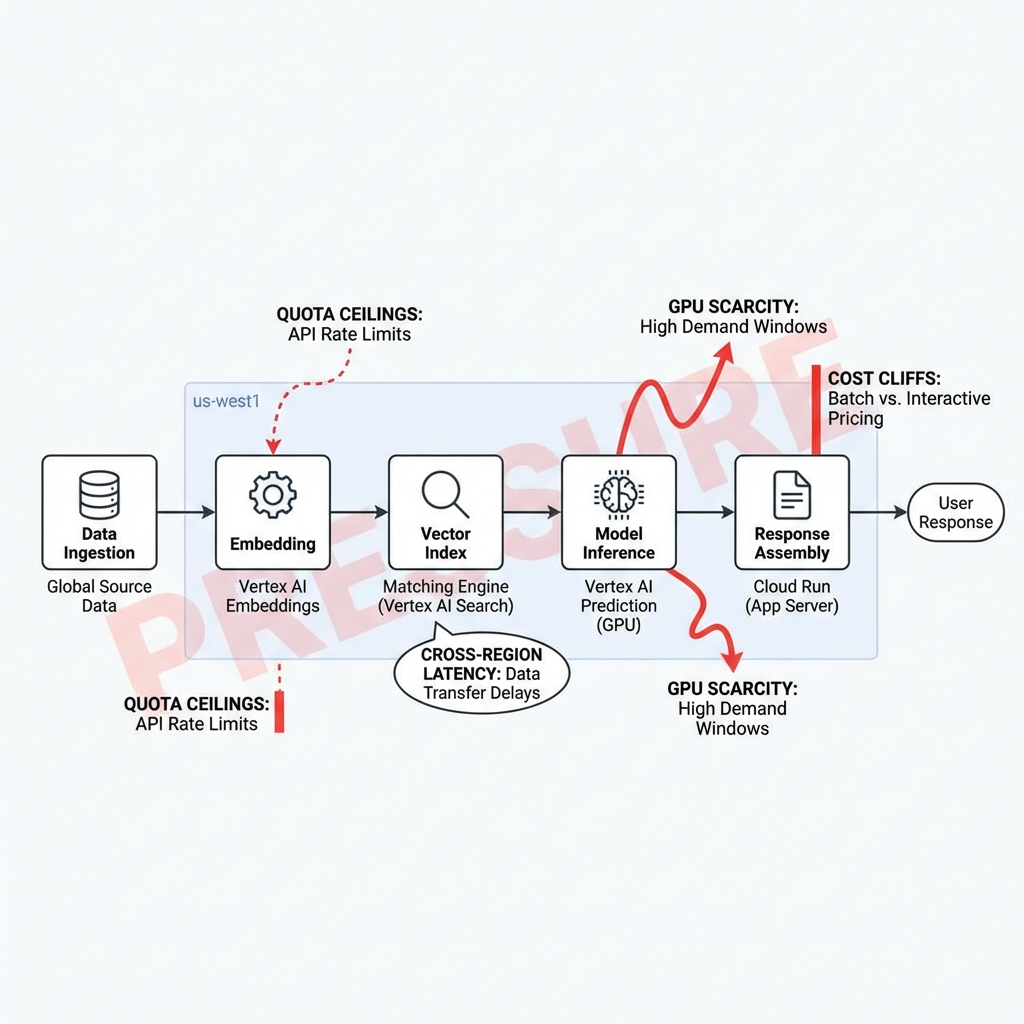
Boundary one: data locality. Keep features and embeddings near inference. Crossing regions adds jitter you can’t smooth with retries. Boundary two: quotas and concurrency. Early defaults are polite; production traffic isn’t. You need to request increases ahead of time or design with fallbacks. Boundary three: model choice drift. Switching from a general model to a smaller tuned model can halve latency and cost, but introduces new monitoring needs and failure modes.
Failure patterns repeat. A team proof-tests a search+gen answer flow with a small vector index. It’s snappy. Then indexing scales, and latency creeps because the index and the API run in different zones. Caches hide it for a while, then a cold-start storm arrives during a release. Another team fine-tunes a model for a niche domain. It sings on a held-out set, then degrades in production because the input distribution is messier. They add guardrails, then costs climb due to additional checks.
There’s also the quiet complexity: IAM that’s too permissive in a rush, then locked down after an incident, breaking pipelines. Observability added late, making it hard to tell if a spike came from the model, the index, or the network. Google Cloud gives you the pieces, but the assembly under pressure is where real engineering happens.
A pragmatic build path from prototype to production on Google Cloud
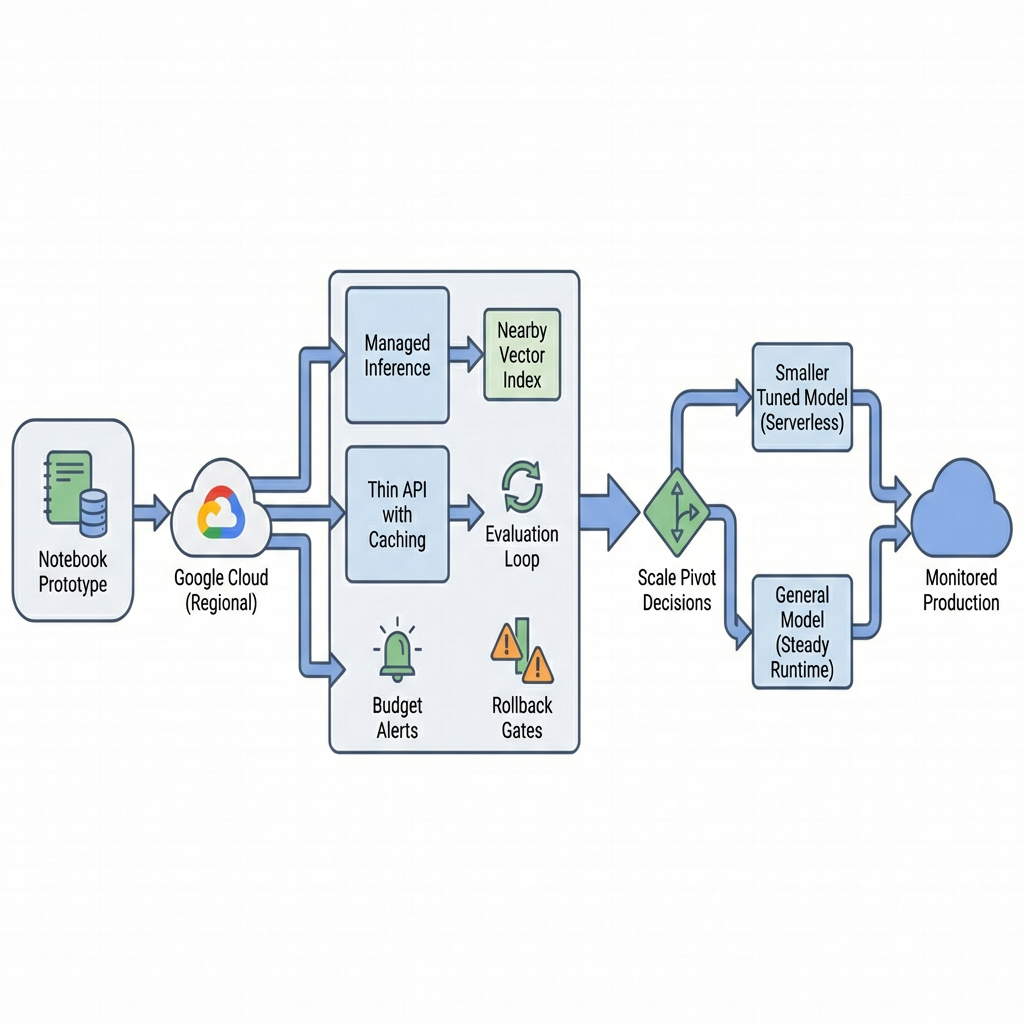
Start narrow. Use a small, representative dataset and a managed notebook to test retrieval and prompting. Keep data in one region. Measure response times at p50 and p95 with tiny concurrency. If you can’t get low double-digit milliseconds on retrieval and sub-second on end-to-end for your target, don’t move on.
Introduce a managed inference endpoint for your chosen base model. Wire a lightweight API with minimal dependencies. Add two things early: caching for frequent prompts or retrieved chunks, and structured logging that captures input shape, model version, and latency. This doesn’t slow you down; it prevents blind rebuilds.
Next, add a vector index close to your data store. If you keep embeddings with operational data, your blast radius shrinks and your consistency story is simpler. Load only what the product uses, not the entire warehouse. Evaluate top-k accuracy with live-ish queries not lab queries.
Wire basic evaluation. A small feedback loop with human checks beats a sprawling benchmark you never run. Track a few metrics that capture product risk: resolution rate, hallucination rate, timeouts. Make alerts cheap to add and easy to silence when tuned.
Friction shows up here. Quotas for concurrent requests, indexing limits, and cold starts test your assumptions. Egress surfaces when you call models or tools across projects. Budget alarms get noisy if you don’t tag costs to features. People start asking about on-call because the “demo” now handles real user flows.
At early scale, you’ll face a pivot. Do you keep using a general model, or move to a smaller domain-tuned one? Do you keep serverless, or move a steady service to a more predictable runtime? The right call depends on traffic shape and latency sensitivity. On Google Cloud, the path of least regret keeps both options open: keep your abstraction thin so you can swap model endpoints, and don’t anchor your storage to an index you can’t re-shard.
When scale arrives, the changes are less glamorous. You’ll add request shaping and backpressure. You’ll move heavy transformations to batch jobs and reserve online paths for lean work. You’ll use canaries for model updates, not just code. And you’ll revise your data contracts so upstream schema changes don’t topple your embeddings.
Examples and applications under real constraints
Support assistant with retrieval
A small team builds a support assistant pulling from internal docs. Early wins: fast prototyping with managed models and a compact index. Friction: updates churn the index nightly and cause brief latency spikes. A patch adds a staging index and swap-over window, but cost rises because both indices exist for a period. Over time, they shrink chunk sizes and improve metadata filters to cut prompt length and cost.
Content quality gate
A pipeline classifies and lightly rewrites user submissions. It runs great in batch, then a product manager wants near-real-time feedback. Routing the same logic online exposes a hidden dependency: a third-party checker across regions. Latency jumps. The team caches frequent checks and creates a fallback threshold where a cheaper heuristic handles borderline cases. Quality dips slightly; throughput stabilizes.
Forecasting with a human-in-the-loop
Finance asks for weekly projections with explanations. The team starts with a general model that summarizes drivers. It impresses on calm weeks. When seasonality hits, narratives look plausible but off. They add a lightweight time-series model for the base signal and keep the generative layer for explanation synthesis. Costs hold, explanations improve, and the team documents when to distrust the summaries.
What beginners try vs what operators ship on Google Cloud
TopicStudents/BeginnersExperienced PractitionersData localityMix regions to use defaultsPin storage, index, and inference to one region; revisit only when neededModel choicePick the largest model for safetyStart with a capable baseline, test a smaller tuned model behind a switchLatencyRely on autoscaling to “handle it”Design for p95 with warm capacity and caching; shape trafficCostsWatch totals monthlyTag by feature, alert on unit economics, rate-limit earlySecurity/IAMOver-broad roles to move fastScoped roles with break-glass policies; audit trails from day oneObservabilityLogs later “when stable”Structured logs, tracing, and eval harness before the first alpha
FAQ
How quickly can we move from notebook to prod on Google Cloud?
Days if scope is tight and data is local. Weeks if you need approvals, evals, and alerts. Speed comes from saying no to extras.
Do we need GPUs to start?
Not for many use cases. Start with managed inference. Add training capacity only when evaluation proves a gap.
How do we avoid surprise bills?
Tag resources, set budget alerts, cap concurrency on endpoints, and cache aggressively. Measure cost per request, not just totals.
What breaks first at scale?
Cold starts, cross-region calls, and unbounded prompt sizes. Fix with warm pools, co-location, and strict prompt budgets.
When do we consider a smaller tuned model?
When latency or cost is blocking adoption and you have stable data. Guard with canaries and rollback switches.
Rising pressure shifts from model picks to operational literacy
The more AI features land in core paths, the less the hard part is “which model.” The hard part is owning latency, cost, and failure domains with the same discipline as any production system.
On Google Cloud, advantage goes to teams who keep their stack swappable, keep data close, and treat evaluation and observability as product features—not chores to do later.


