
Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
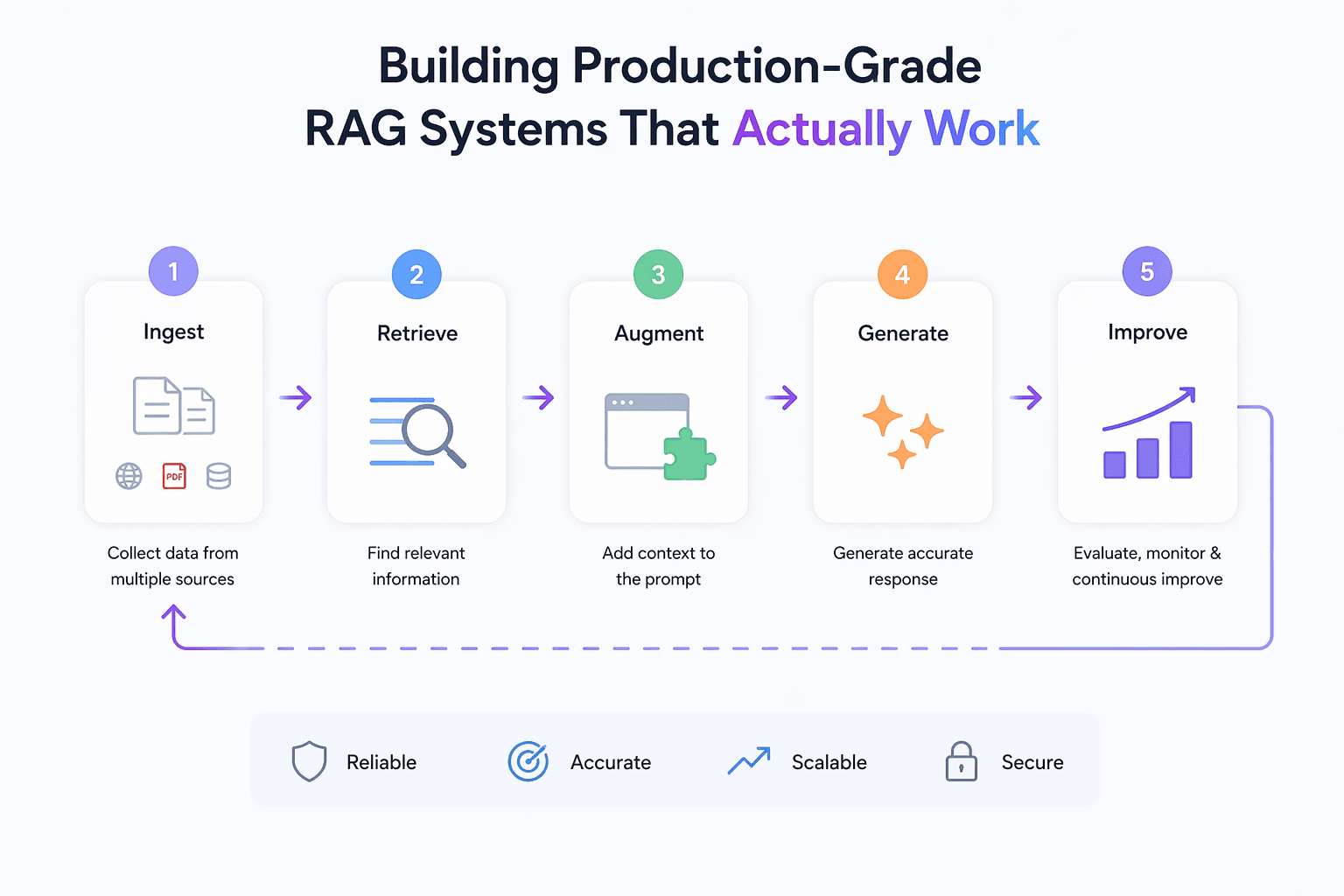
RAG for the Enterprise sounds simple: retrieve, then generate. In production, the quiet parts are the ones that bite permissions, drift, latency, and accountability.
Executive Summary
This guide focuses on how RAG behaves once real users, real data, and real risk show up. It is a field manual more than a primer.
You will see how to move from an impressive prototype to a dependable system by managing retrieval quality, latency budgets, guardrails, and iterative evaluation. Expect trade-offs, not magic switches.
Scope first: narrow use case, measurable outcomes, explicit failure modes.
Design retrieval for permissioned data and drift, not just relevance.
Treat latency, token limits, and cost as fixed constraints, not afterthoughts.
Build an evaluation loop tied to business impact and regression safety.
Scale with observability, caching, and fallback paths you actually test.
Introduction
A team ships a promising assistant. Demos land. The first week in production, page loads climb, and the system starts missing obvious answers. User sessions dip. Support tickets include screenshots of hallucinated policy text. Compliance asks who approved access to a private folder that suddenly shaped responses. The prototype didn’t predict any of this.
That’s the gap this article closes. How to Build Production-Grade Retrieval-Augmented Generation Systems That Actually Work is less about clever prompts and more about controlled retrieval, predictable latency, and guardrails that hold during outages. RAG for the Enterprise is trending because organizations can’t accept hallucinations, can’t leak data, and can’t pay unbounded inference costs for routine queries. Retrieval is the cheapest and most auditable way to inject facts, but only if the pipeline holds together under pressure.
RAG behaves differently once real traffic hits
Most failures arrive from the edges: mismatched permissions, stale indexes, and context overflow. You can pass a pilot with perfect relevance and still fail production when workloads vary, embeddings age, or token pressure squeezes reasoning.
Where the boundaries show up:
Latency budgets collide with recall. Aggressive retrieval improves grounding but pushes responses past user tolerance. Pagination helps, until users bounce. Pre-compute and cache what you can,but know what can safely be cached.
Index drift is quiet then sudden. Content updates, formats shift, schemas evolve. Retrieval quality degrades without obvious errors. Stale chunks become authoritative to the model. Set rebuild cadences and diff checks. Monitor recall against a fixed test set across index versions.
Permissions are the hardest constraint. Enterprise RAG breaks when retrieval ignores access control. The fastest path is often inefficient filtering at query time. The safer path binds permissions into the index or feature store. Both have failure modes. Choose and document the risk.
Context is not a suitcase with infinite space. Token limits force pruning. Naive top-k leads to near-duplicate chunks crowding out the critical paragraph. Favor diversity, not just similarity. Track how much context is actually read by the model with ablations.
Prompt assembly scales poorly if it grows by exceptions. Every hotfix adds another branch. When bugs surface, you can’t explain which variant ran. Keep prompt templates versioned and diffable. Tie them to evaluation sets.
Guardrails fail open under load if they aren’t staged. If you plan to block risky outputs, test with adversarial prompts at scale. Log refusals as success, not failures, where refusal is the correct behavior.
Costs don’t just creep. They spike when a new retrieval path adds long contexts and a larger model tier. Track cost per successful task, not per request. Budget by outcome.
From prototype to production: a workable path
Start with a thin slice and ground truth
Resist broad scope. Pick one task with measurable outcomes: answer a type of question, draft a specific artifact, parse a narrow document family. Collect representative questions and the sources you would accept as ground truth. This is your evaluation seed.
Design the schema before the chunks
Chunking follows how users ask questions. If questions reference sections, keep section headers. If they reference entities, store normalized entity IDs. Without a schema that reflects user queries, you will over-retrieve and under-ground.
Choose embeddings and retrieval that fit the risk
High-sensitivity answers deserve conservative retrieval: hybrid lexical plus dense vectors, then reranking. Low-risk tasks can favor speed. Start with a baseline, then ablate features to see what truly moves the needle.
Assemble prompts with constraints in mind
Budget tokens first. Decide the maximum context size you can afford and stick to it. Include source attributions in the prompt contract. If the model ignores attributions, modify the format or retrieval to supply cleaner spans.
Cache what repeats, not what shouldn’t
Cache embeddings and frequent retrievals for public or stable content. Avoid caching where permissions or freshness are in play. Treat cache misses and invalidations as first-class paths. Test them.
Build an evaluation harness before launch
Offline tests: relevance at the retrieval layer, faithfulness at the generation layer, and exactness where structure matters. Online tests: small canary cohorts with guardrails that hard-stop on critical errors. Carry a small set of red-team prompts into every release.
Ship with observability, not optimism
Log the retrieval set, the chosen context, and the output against an anonymous request ID. Track latency percentile, refusal rates where expected, and citation coverage. Correlate user edits with retrieval misses, not just model errors.
Plan for failure paths before usage spikes
Define fallbacks when retrieval returns nothing or when generation is unavailable. Fail gracefully with citations or human escalation. Test outage drills like any production system.
Scale changes the friction
As queries grow, long-tail questions dominate. Your carefully tuned top-k turns brittle. Introduce dynamic retrieval depth based on query type or confidence. Revisit embedding updates and index rebuild cadence based on usage, not a calendar.
Examples and applications that aren’t clean on the first try
Policy assistant for internal teams. Early success on common questions. Failure when a single team stores draft policies in an unindexed folder. Users get outdated answers with perfect tone. Fix required indexing the draft space with a strict label filter and a higher refusal threshold when drafts dominate the context.
Developer knowledge bot. Latency stays under target until launch week. A surge in code-base queries blows token budgets and timeouts climb. Adding a thin pre-filter on file types plus per-language embedding spaces restores relevance and cuts context size without re-architecting.
Customer support helper. Retrieval nails top articles but generates steps that don’t match a specific device version. Granular metadata for versioning was missing. Backfill labels, add a reranker biased to matching versions, and retrain evaluation to mark mismatched-version answers as hard failures.
Risk and compliance Q&A. Hallucination rate is already low, but leadership still rejects un-cited answers. The change is procedural: enforce citations and refuse when sources are weak. Acceptance improves despite more refusals because traceability beats optimism.
What changes with experience
Area Beginners Experienced Practitioners Use case Broad assistant, unclear KPI Narrow task, measurable outcome Data selection Index everything Index only curated, labeled sets Chunking Fixed size chunks Schema-aware, query-shaped spans Retrieval Top-k dense vectors Hybrid + reranking + diversity Prompting Grow templates by exceptions Versioned templates with constraints Evaluation Manual spot checks Offline sets + canary gates Monitoring Request/latency totals Retrieval quality and citations Security Filter after retrieval Permissions embedded in retrieval Scaling Add hardware Cache, precompute, degrade gracefully
FAQ
Where should I start if I have mixed-quality documents?
Pilot with the cleanest, highest-impact set. Establish labels and structure there. Expand only when retrieval quality holds.
How do I know if retrieval or generation is the problem?
Run generation on gold sources and compare. If answers improve, fix retrieval. If not, adjust prompts, model choice, or refusal policy.
How often should I rebuild the index?
Tie rebuilds to changes in source data and retrieval performance, not a calendar. Monitor recall on a fixed test set to trigger rebuilds.
Do I need a larger model to improve accuracy?
Not always. Better chunking, reranking, and stricter context often beat larger models for enterprise tasks with clear sources.
How do I enforce citations without hurting UX?
Format answers compactly with source anchors and refuse when sources are weak. Users prefer honest refusals overconfident guesses.
The pressure shifts from novelty to reliability
RAG for the Enterprise graduates from demos when its failure modes are cheaper than its successes are impressive. That means controlled retrieval, predictable latency, and traceable answers.
The next step isn’t more features. It’s tightening evaluation, pruning scope, and owning the trade-offs you can actually support under load. That’s how production-grade systems survive contact with real use.


