
Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Practical decisions for Image-recognition-and-computer-vision under constraints.
Executive Summary
Most teams can get a demo model running in a day. Making it useful, stable, and accountable takes deliberate choices. This piece focuses on those choices, not hype.
You will see how to move from a test image to dependable recognition in production. Where projects stall. How to keep decisions reversible while you learn.
Scope only what your application can observe reliably.
Label for the decision you need, not for textbook categories.
Budget latency and memory before picking a model path.
Plan for drift and feedback before launch, not after.
Track outcomes, not just accuracy.
Introduction
You’re asked to add image recognition to an existing product. No new headcount. A tight schedule. A stream of user complaints waiting if it’s wrong. That’s the room most of us start in.
Image-recognition-and-computer-vision has moved from research novelty to baseline expectation. Users assume your app can spot objects, read scenes, or flag anomalies without fuss. The gap between demo and daily reliability is where teams burn time.
This guide covers How to Implement Image Recognition in Your Applications when the inputs are messy, resources are limited, and requirements change the week before launch. It focuses on how Image-recognition-and-computer-vision behaves under pressure, not just how it should behave on clean data.
It’s trending because cameras are everywhere, storage is cheap, and modern models are accessible. It’s necessary because products now compete on responsiveness, context, and reduced manual work. If your app can see, it can decide faster—and users will feel it.
What actually breaks when vision meets real users
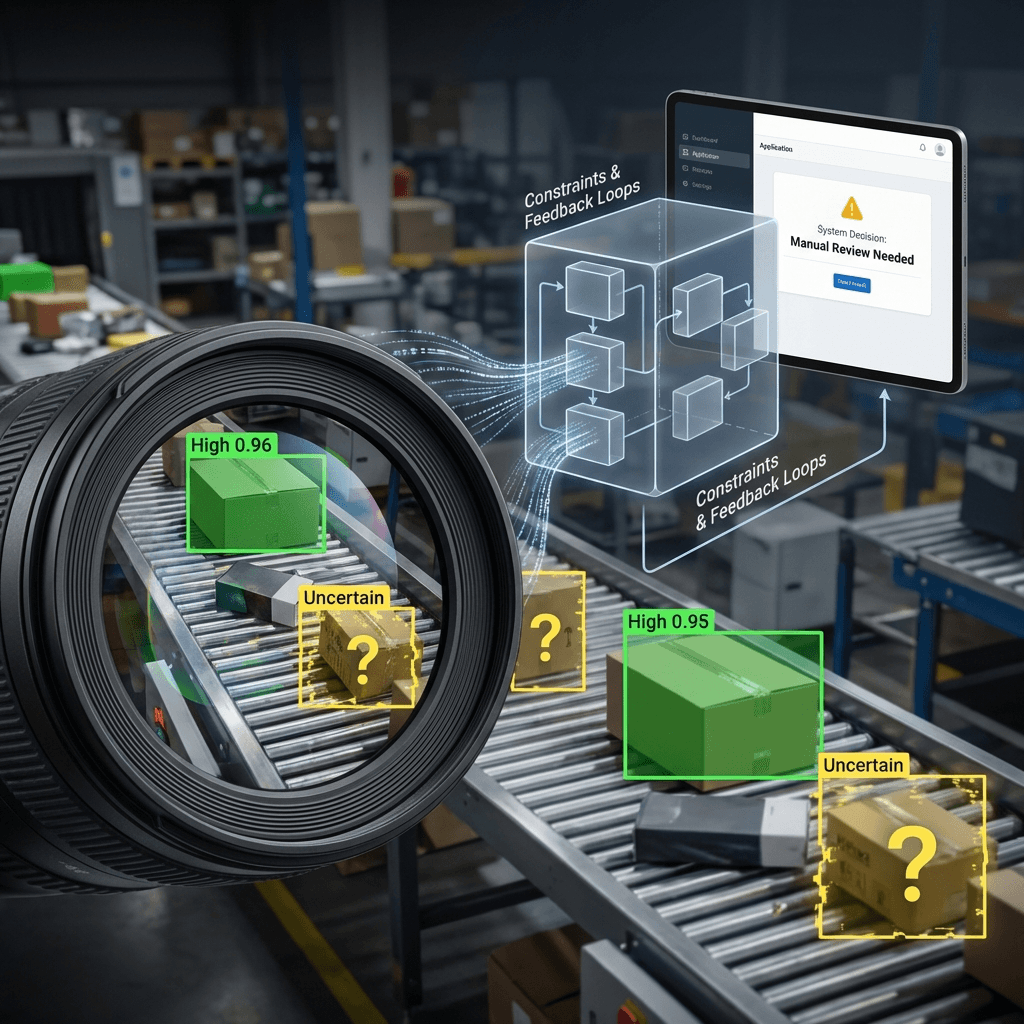
Data shifts faster than you expect. Lighting, camera angle, background clutter, new object styles—each nudges your model off its training distribution. The first week looks great. Week three hurts. Concept: weak points across an Image-recognition-and-computer-vision pipeline.
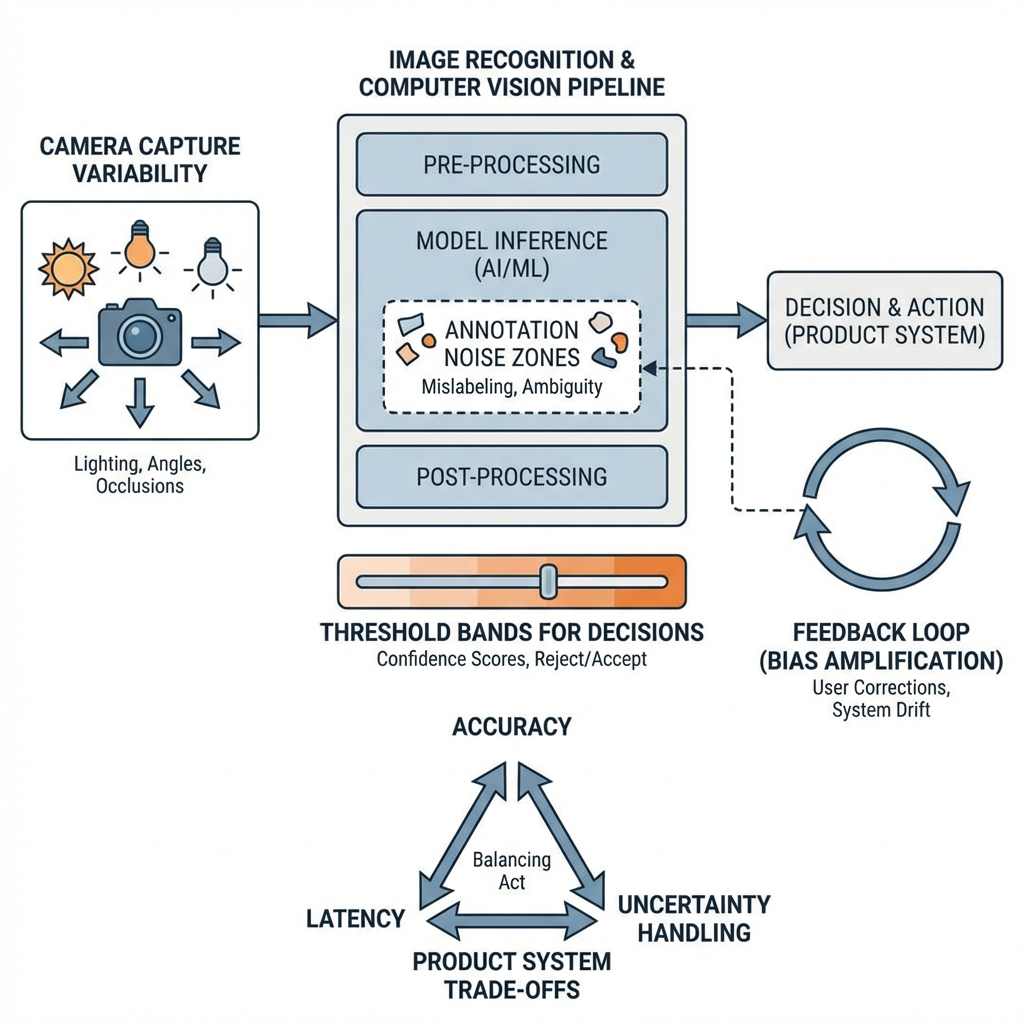
Boundaries show up as false confidence. The model is 99% sure a reflection is a valid object. Or it misses rare classes entirely because they never showed up in early labeling. You’ll feel this as support tickets or silent misroutes in downstream logic.
Performance pressure exposes latency trade-offs. A heavier model boosts accuracy on a benchmark, then blows up your response time on battery-limited or low-cost devices. Quantization or pruning helps until it breaks a fragile class boundary.
Privacy and compliance constraints reduce your labeling options. You’ll drop some data sources or blur sensitive regions. That changes what the model can learn. The decision becomes: accept a simpler target or accept slower iteration.
Annotation noise compounds. Inconsistent guidelines and rushed labeling create class confusion that no amount of tuning can fix. You’ll chase losses in training that should have been resolved in instructions and review.
Feedback loops can destabilize the model. If predictions influence what gets labeled next, the dataset can overfit to easy cases. You’ll need to inject hard negatives and actively sample edge cases or the system gets brittle.
From prototype to dependable behavior in stages (Flow: iterative rollout in Image-recognition-and-computer-vision)
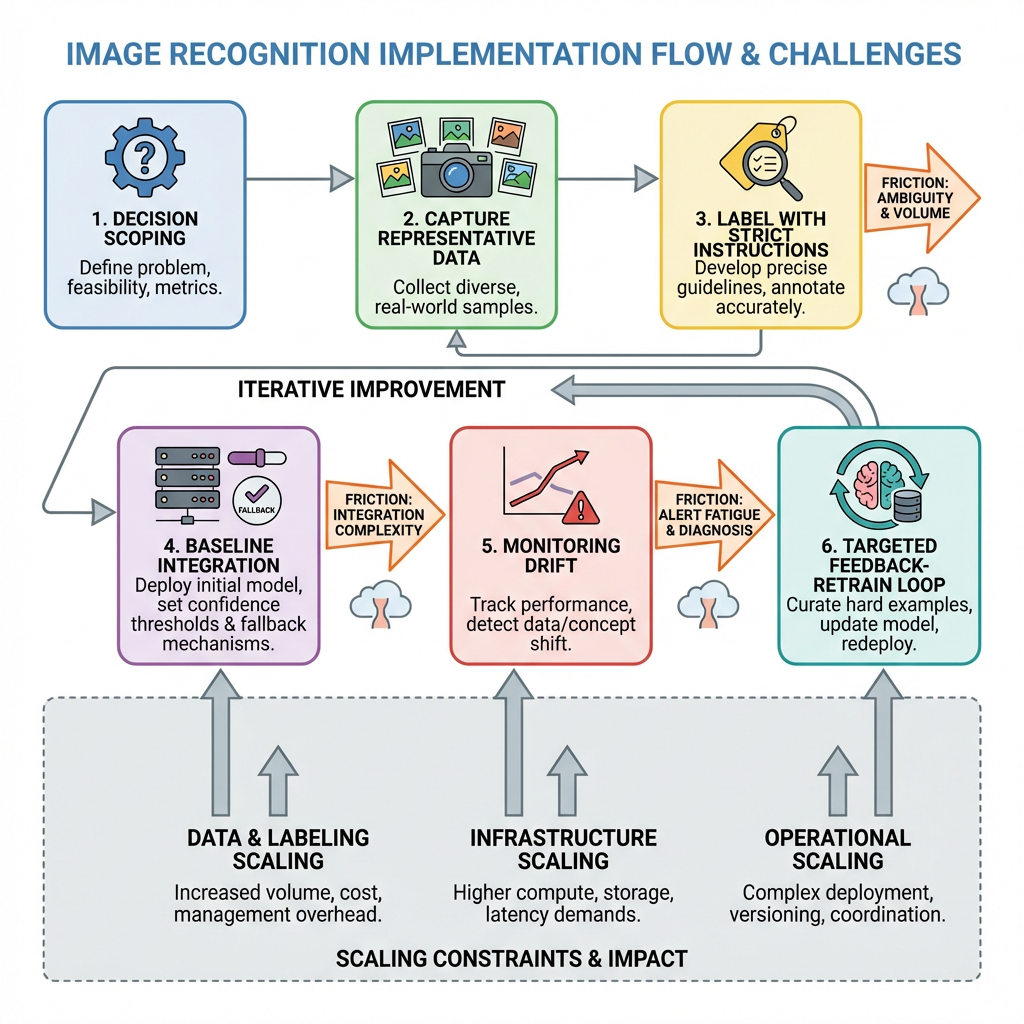
Start with the decision, not the class list. What will your application do differently when it sees X versus Y? Reduce the taxonomy to the minimum that changes behavior. If the product treats three categories the same, merge them now. This keeps annotation focused and reduces class imbalance.
Capture representative data early. Don’t wait for volume; aim for variety. Collect under the lighting, angles, and device optics your users will actually have. Include failure cases on purpose. If you can’t capture safely, synthesize carefully and test on a small real slice before committing.
Write labeling instructions that mirror the decision. Show borderline cases. Define what to ignore. Add a short review loop for early batches to fix drift in guidelines. Most teams lose more accuracy here than in modeling.
Establish a baseline fast. Use a straightforward approach first to expose problems in data and labels. Measure on a held-out set that includes rare cases. Keep the baseline running in a branch so you can compare future changes.
Integrate before you optimize. Wire the baseline into your application path with guardrails. Route predictions through a threshold and a fallback. Log inputs, scores, and final outcomes separately. The first week of integration will reveal interface and latency issues that no offline metric shows.
Set thresholds to minimize bad decisions, not to maximize a single metric. Define two bands: confident positive, confident negative. Add a small uncertain band where the system asks for help or defers to existing logic. This reduces user-visible errors while you learn.
Monitor real-world drift. Compare daily or weekly distributions of inputs to the training set. Track outcome rates, not just confidence means. A spike in uncertain cases or an uptick in false escalations is your retraining trigger.
Scale deliberately. If inference cost or latency climbs, explore model compression, batching, or moving some logic closer to capture. Test these changes against edge cases, not only against average accuracy. Compression often distorts the very classes you care about.
Close the loop without flooding. Sample uncertain predictions and mistakes for annotation. Avoid letting the model pick only easy examples. Maintain a small fixed “known hard” set that must improve with every iteration or you don’t ship.
Examples and applications with friction included
A gate detection feature flags authorized items as they pass a checkpoint. Under fluorescent glare, reflective surfaces mimic valid markers and slip through at low angles. Adding a simple angle constraint and an uncertain band reduces obvious misses, but throughput drops. You trade some speed for fewer escalations until you improve examples for low-angle cases.
An on-device classifier sorts images into three action paths. It works well near power, then fails in the field when devices throttle. A smaller model fixes latency but confuses two similar classes. You merge those classes and move the subtle distinction into a follow-up step that runs only when resources allow.
A quality review tool looks for small defects. Early success fades as suppliers change materials. The distribution shift isn’t visible to metrics until reviewers complain. You add a simple weekly snapshot audit and discover the new texture pattern was never in training. Targeted data capture and a few hard negatives recover performance faster than another architecture change.
A content triage workflow uses recognition to route items. Confidence is high on day one, then users report mismatches in a new context. You realize the camera pipeline introduced compression that blurs fine details. Switching to a slightly higher capture quality for a subset of frames, and caching those for review, cuts misroutes without raising system-wide cost.
Beginners and experienced operators: where choices diverge
Area Beginners Experienced practitioners Problem scoping Start with many classes Collapse to the smallest set that changes behavior Data collection Chase volume Chase variety and failure cases Labeling Loose guidelines Tight instructions with review on early batches Model choice Pick the biggest available Pick the simplest that meets latency and memory Evaluation Single metric focus Per-class checks, hard set tracking, outcome-based thresholds Integration Optimize before wiring Integrate early with thresholds and fallbacks Monitoring Watch average confidence Watch drift, uncertainty bands, and downstream outcomes Iteration Retrain on everything Retrain on targeted slices and keep a fixed hard set
FAQ
How much data do I need to start?
Enough to cover real variation and a handful of hard negatives. Prove value with a small, well-labeled set before scaling.
Should I build or use a pretrained model?
Start from something pretrained when possible, then adapt. Only go custom when the target differs materially or constraints demand it.
How do I set a good threshold?
Define two clear bands plus a small uncertain zone. Tune against real outcomes, not just offline scores.
What causes most failures?
Shifts in capture conditions and inconsistent labels. Fix collection and instructions before changing architecture.
How do I monitor in production?
Log inputs, scores, decisions, and user-visible outcomes. Track drift and sample uncertain or wrong cases for review.
Responsibility shifts from model accuracy to system behavior
Once your app depends on vision, the question stops being “Is the model good?” and becomes “Does the system make the right call under pressure?” That shift changes your priorities toward thresholds, fallbacks, logging, and feedback.
Capability will keep improving, but the hard work stays the same: scoping decisions tightly, exposing uncertainty, and designing loops that learn without breaking user trust.


