
Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
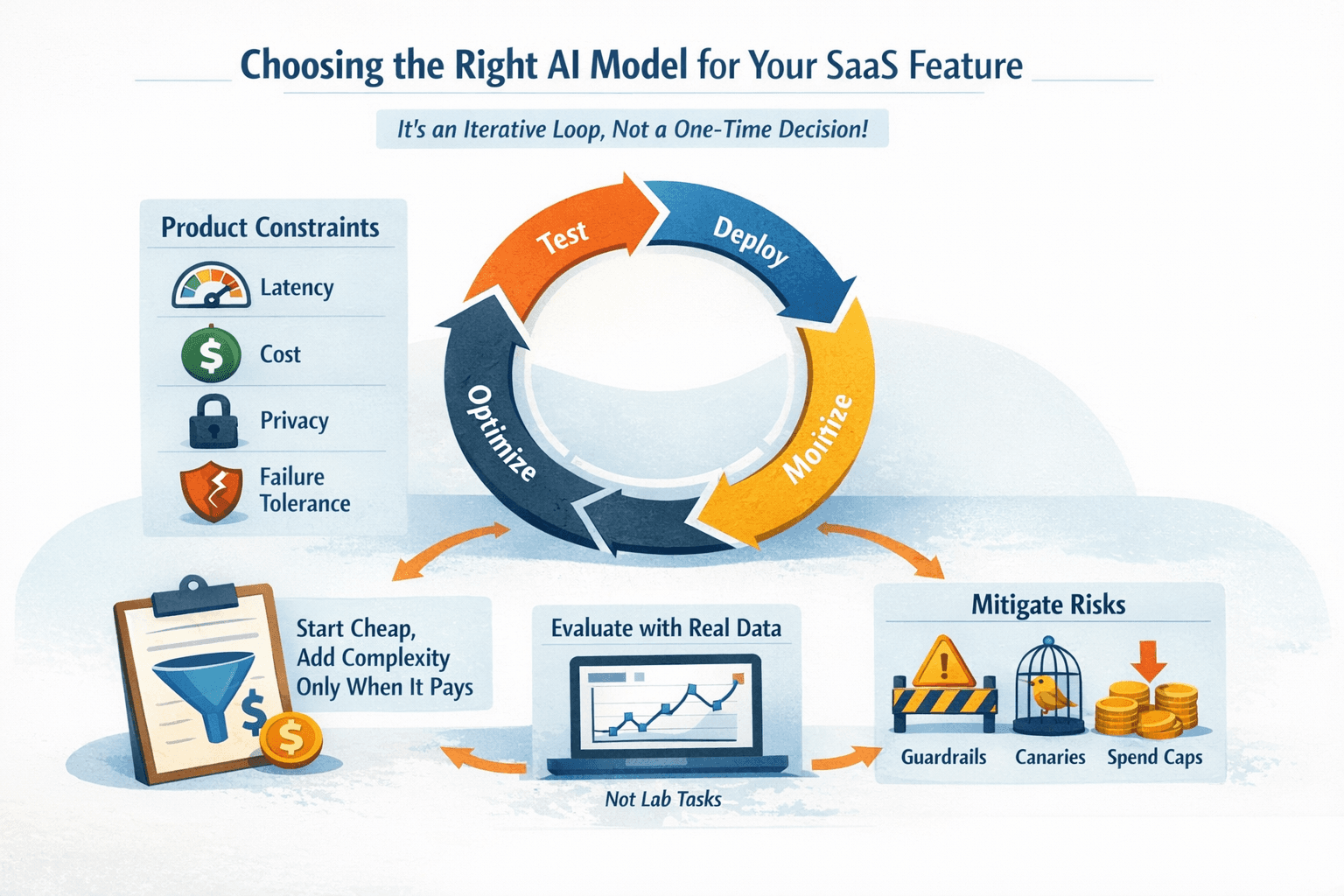
Picking AI Models used to feel like buying a single tool. Now it’s a rolling set of bets that impact latency, support load, and runway. Done well, it compounds. Done poorly, it leaks money and user trust.
Executive Summary
Most teams overspend by treating model choice as a one-time decision. In reality, it’s an operational loop. This piece shows how to choose AI Models that fit your SaaS feature, budget, and support burden without falling for benchmarks that don’t hold up in production.
You’ll walk away able to:
Frame model selection around product constraints: latency, cost, privacy, failure tolerance
Start with cheap baselines, then add complexity only where it pays back
Run a lean evaluation loop with your real data, not lab tasks
Contain risk with guardrails, canaries, and spend caps
Not a framework. A set of moves that hold up under shifting requirements and tight budgets.
Introduction
You ship a new assistive feature. Early users love it. Then usage doubles and your bill follows. The model that felt safe in dev turns into a tax. Support tickets climb when edge cases hit. Finance asks for a plan.
This is the gap between demo able and durable. How to Pick the Right AI Model for Your SaaS Product Without Wasting Money isn’t about the fanciest spec. It’s about aligning AI Models with the job your product needs to do, at a price and speed the rest of your system can support.
It’s trending because two things are true at once. Foundation models keep improving. And customers now expect AI features in everyday tools. The result: model choice has moved from research to product operations. If you don’t build a selection process that respects constraints, you’ll chase benchmarks while your margin erodes.

What model choice looks like when money and users are real
In production, the right model is the one that makes your feature reliable today and cheaper tomorrow. That usually means a small baseline for the common path and a stronger fallback for the rare, costly cases. The failure patterns live in the seams: rate limits at peak, token explosions on messy inputs, prompt drift after a UI tweak, and silent regressions after a vendor update. Spend-pressure model map
Boundaries show up fast:
Latency budget: If your UI needs sub-second response, a heavy model becomes support debt.
Cost per action: If you can’t trace cost per request, you’ll over-serve trivial cases.
Data constraints: If data can’t leave your region or VPC, hosted models may be a non-starter.
Failure tolerance: If a wrong answer is worse than no answer, you need deterministic fallbacks.
Common failure patterns:
Benchmark traps: The “best” model on a public leaderboard underperforms on your messy input.
Prompt bloat: Each patch adds tokens; queries get slower and pricier without visible gain.
Unbounded retries: Transient errors trigger recursive retries that quietly spike spend.
Vendor inertia: You glue product decisions to one provider, then eat the cost when pricing shifts.
Reality check: the cheapest model that meets your acceptance threshold is usually right if you can detect when it stops being right.
The path that avoids burn: a pragmatic model selection flow
Here’s a flow that teams use when runway and reputation matter:
1) Define acceptance, not ambition
Write the smallest test that would make you comfortable rolling out. Examples matter more than metrics here. Five to ten representative cases, including edge cases users actually hit. If you can’t define acceptance, you’ll overspend chasing a vibe.
2) Establish a cheap baseline
Start with a small model or trimmed prompt. Measure on your examples. If it’s passable for 70 to 80 percent of cases and failure modes are safe, keep it. Don’t upgrade until failure cost exceeds cost savings.
3) Layer a “smart fallback” path
Route ambiguous or high-stakes requests to a stronger model. Keep the paths explicit. Most products don’t need heavy compute on every request; they need it on the right requests.
4) Evaluate offline, then in shadow
Offline with your data first. Then shadow live traffic without user impact to catch token spikes, latency cliffs, and weird inputs. Logging and sampling beat theoretical confidence.
5) Cap spend and watch drifts
Set per-feature budgets and hard caps early. Track prompt versions and inputs because drift often comes from UI or upstream data, not the model itself.
6) Canary and rollback
Roll out to a sliver. Watch quality and spend. If costs jump or errors climb, fall back automatically. Make this boring and you’ll save days later.
Where friction appears:
Throughput vs. accuracy: Batch endpoints save money until queues hurt UX.
Context limits: Long contexts tempt you to stuff everything, then latency doubles.
Rate limits: Peak usage aligns with your SLAs. Provision for that hour, not the average.
What changes when you scale:
Routing pays off: Specialized paths let you cut average cost while boosting reliability.
Observability matters: Without per-request cost and outcome logging, you’re flying blind.
Ownership shifts: Model selection becomes a product responsibility, not a research project.
Deciding what “good enough” means for your feature
Tie quality to user impact
Map mistakes to consequences. If a wrong suggestion annoys but doesn’t break anything, bias to speed and cost. If errors trigger compliance risk or churn, bias to precision and guardrails.
Budget by unit of value
Express cost per request relative to the value of the action. If a conversion is worth dollars, you can justify heavier inference on that path. If it’s a navigation hint, keep it light.
Prefer observability over sophistication
A simple, observable stack beats a clever one you can’t debug. If you can’t trace why a response changed, you can’t manage it under pressure.
Examples and applications
Scenario: in-app writing help. Baseline small model gives quick grammar fixes. Fallback kicks in for long-form rewrites. Imperfection: users paste mixed languages and emojis; token count jumps, latency spikes. Fix: compress context and detect language earlier. Result: 40 percent lower median latency, fewer timeouts.
Scenario: ticket triage. Baseline classifier groups common tickets. Fallback model handles ambiguous cases. Imperfection: new issue types appear after a release; classifier drifts. Fix: retrain weekly on fresh samples and widen confidence thresholds. Result: fewer misroutes, stable spend.
Scenario: analytics summarization. Baseline template pulls metrics. Fallback model interprets vague prompts. Imperfection: prompt tweaks by another team change output style, breaking downstream parsing. Fix: lock prompt versions and add schema checks. Result: no silent regressions.
Tables and comparisons
Decision AreaBeginnersExperienced PractitionersModel choicePick the strongest model by reputationStart small, add targeted fallback for hard casesEvaluationUse public benchmarksUse product examples with failure-cost weightingLatencyHope users tolerate delaysSet budgets per interaction and enforceCost controlTrack monthly totalsTrack per-request spend and cap by featurePromptingTune endlesslyVersion prompts, limit tokens, test diffsRolloutBig switchCanary, shadow, rollback triggersOwnershipAd hocClear product ownership with SLOs
FAQ
How do I know if I should use a smaller model?
If it meets your acceptance tests for the majority path and failures are safe, use it with a targeted fallback.
What’s the fastest way to avoid surprise bills?
Set per-feature caps, log per-request tokens, and block retries beyond a limit.
Do I need offline evaluation?
Yes. Use your own examples to filter options before paying for live tests.
When do I fine-tune?
When prompts hit a wall on consistent, narrow tasks and the unit economics justify setup and maintenance.
How often should I recheck models?
On prompt changes, upstream data changes, provider updates, and at a regular cadence tied to usage.
Rising pressure to justify inference spend at the feature level
Model selection is turning into a budgeting exercise that product teams own. The question isn’t “what’s the best model,” it’s “what model mix keeps quality stable under growth without eroding margin.”
Expect a shift from single-model bets to deliberate routing, clearer acceptance thresholds, and tighter observability. The teams that treat AI as an operational loop will ship faster and spend less.


