

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Customers don’t remember channels; they remember how a brand treats them. Generative AI is now the layer stitching those moments together.
Executive Summary
Lexus is leveraging generative AI to align real customer intent with what teams can deliver in the moment. This isn’t a single feature. It’s a set of decisions under pressure.
What matters: how the system handles ambiguity, escalations, and the handoff to people. The gains show up when those edges are managed well.
Understand where generative AI slots into Lexus’ service and sales journey, without overpromising.
See failure patterns: hallucination, policy drift, brittle prompts, slow handoffs.
Learn a flow for scaling: capture intent, compose response, commit safely, track outcomes.
Compare beginner vs seasoned practices for building reliable experiences.
Introduction: the morning rush and the hidden queue
Walk into a busy showroom just before lunch. Phones ringing. A service advisor juggling three appointments. A customer wants a quick status update; another needs a last‑minute test drive. The human queue is invisible. That’s where generative systems now sit—triaging, drafting, nudging, and sometimes stepping aside.
Lexus is leveraging generative AI to reshape customer experience by making each interaction feel personal without creating chaos behind the counter. It’s trending because raw automation isn’t enough anymore; customers expect context and continuity across chat, phone, and in‑person. It’s becoming necessary because precision and empathy won’t scale on schedules alone. Lexus is leveraging generative AI to connect front‑stage conversations with back‑stage realities.
Where AI helps—and where it breaks under pressure
In real environments, the model’s best output is often not the final answer; it’s the right next step. A prompt can assemble a service update, but policy and inventory constraints decide whether that update is safe to send. The system has to detect intent, check boundaries, and pick a path that won’t set up the team for an apology later. Concept sketch: intent routing under policy and human override.
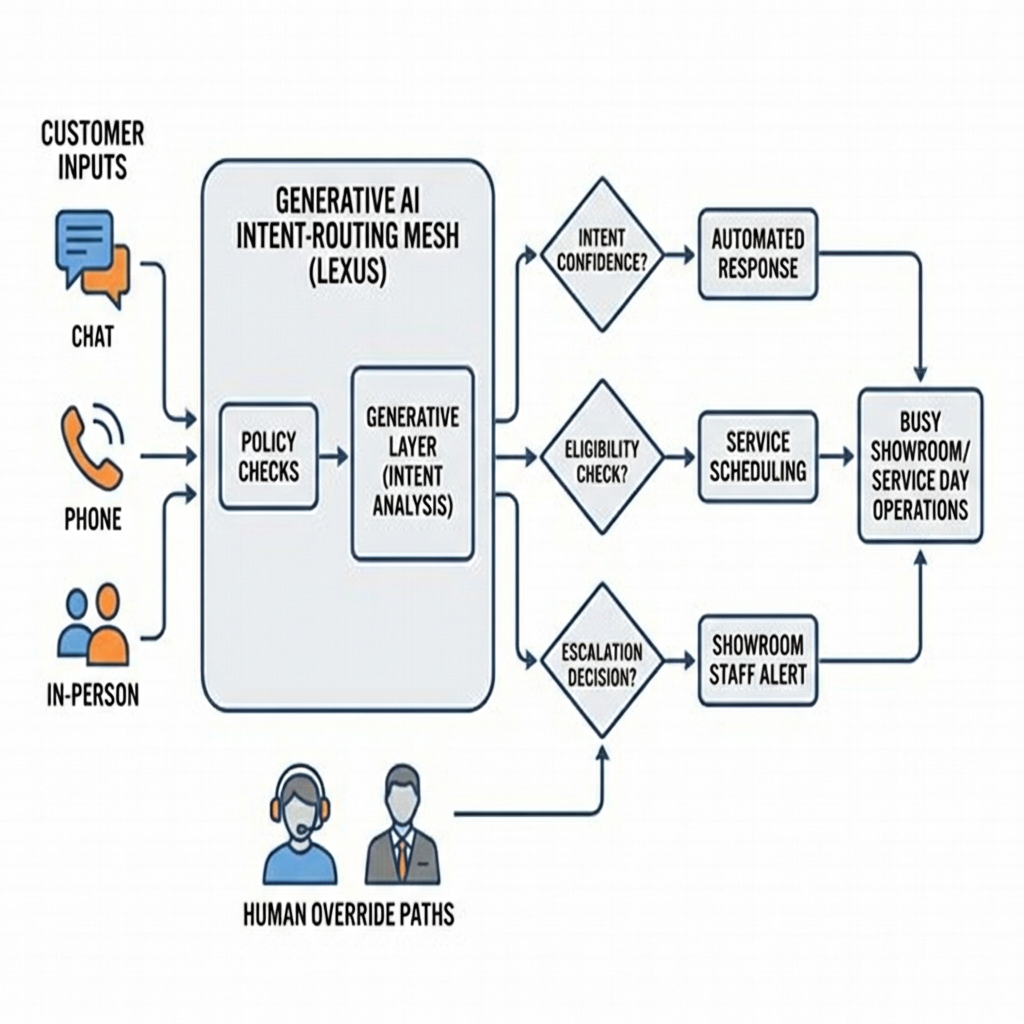
Boundaries show up fast. A model might infer a tone—frustrated, time‑boxed—and suggest a goodwill gesture. If the policy doesn’t allow it, the system needs a graceful deflect: offer options, schedule, escalate. Failure patterns look like this:
Policy drift: the model invents eligibility or overcommits timelines.
Hallucination under sparse data: filling gaps with confident fiction.
Brittle prompts: minor phrasing changes swing outcomes wildly.
Slow handoffs: AI holds the conversation too long, human picks it up too late.
The fix isn’t more model horsepower. It’s guardrails that feel invisible to the customer: eligibility checks, safe fallback phrasing, escalation signals that move fast, and a way to track promises back to the team doing the work.
From prompt to handover: how Lexus’ flow actually works
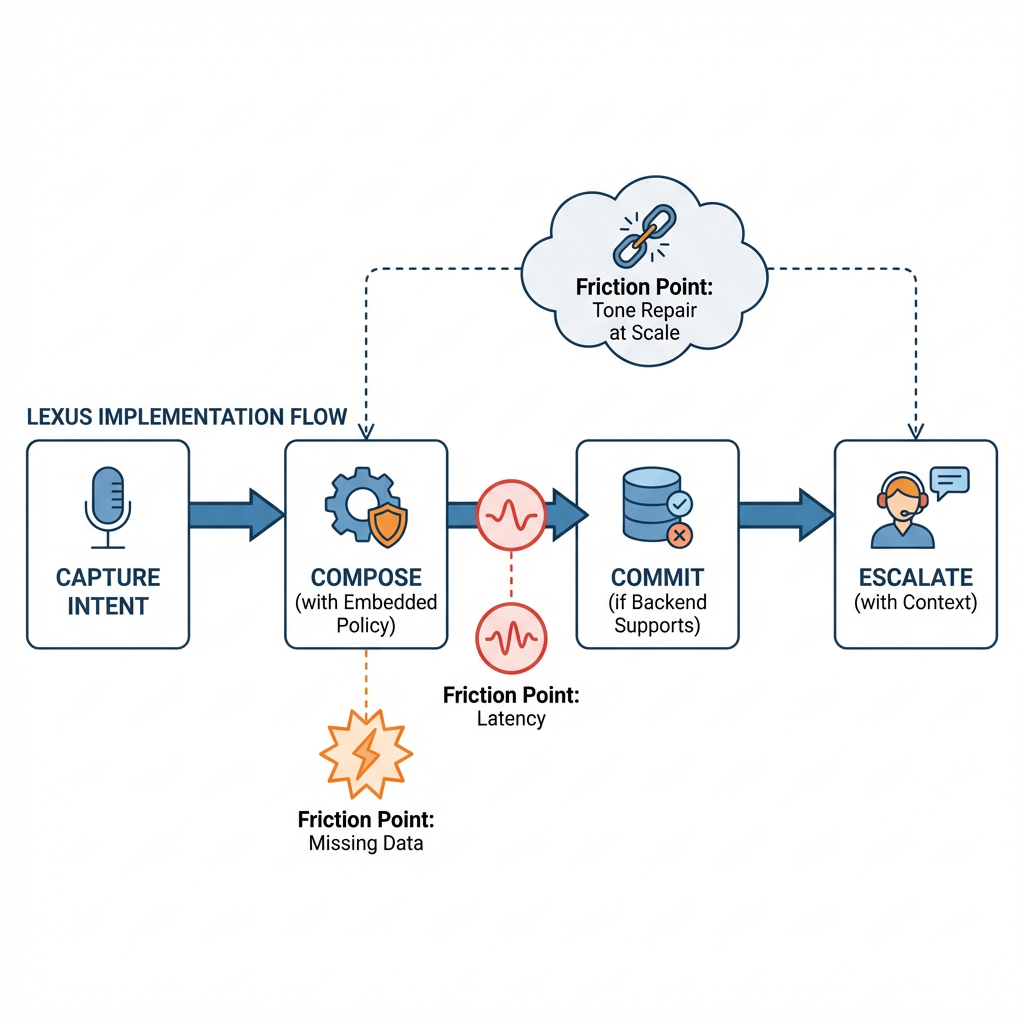
Implementation isn’t a neat diagram. It unfolds like this:
Capture intent without overfitting
Start with the customer’s words and context: recent visits, open tasks, constraints they mentioned. The system needs to know when it knows enough. If intent confidence is low, ask a tight clarifying question—one line, not a survey.
Compose responses with policy embedded
Draft the message using generative AI but wire it through rules that matter. If a part isn’t confirmed, don’t promise a time. If a test drive needs license validation, lead with the requirement early. Every sentence should reduce future back‑and‑forth.
Commit only when the backend can carry the weight
Before sending, check the operational state. A slot can’t be booked if the slot isn’t real. When friction appears—double booking, mismatched expectations—the system chooses: soft commit (offer a window), or escalate with suggested scripts for the advisor.
Handover and accountability
When escalating, include the full context: the customer’s last three messages, the proposed resolution, the reason for handoff. Don’t make the human re‑interview the customer. Tie the AI’s draft to a trackable task so nothing floats.
What changes at scale
Small pilots are forgiving. At scale, edge cases pile up: multilingual requests, partial histories, off‑hours promises. Latency starts to matter. The system needs a way to degrade gracefully—shorter responses, clearer options, more frequent human routing—without feeling robotic. Measured ambition beats maximal automation.
Examples and applications: real scenarios, imperfect outcomes
Service status with missing data
A customer asks for an update, but the repair note hasn’t synced. The AI drafts a response with two options: wait for confirmation or switch to a quick call. It avoids guessing the finish time. The customer picks the call. The advisor sees the context and closes it in under a minute. Imperfect, but clean.
Test drive with shifting availability
Two customers request the same slot. The AI offers the second customer a nearby window and a hold. If the hold expires, it sends a polite follow‑up with new options rather than a silent drop. Slight friction, contained.
Cross‑channel continuity
A chat starts with a trim question and shifts to financing. The AI keeps the thread together but doesn’t answer beyond its safe range. It cues a specialist with a concise summary and a suggested opening line. The specialist picks it up without rehashing basics.
Tone repair after a misread
The model interprets the customer as casual and drafts playful copy. The person replies bluntly. The AI pivots: neutral language, fewer adjectives, specific steps. Tone correction is part of the flow, not an afterthought.
Tables and comparisons: how approaches differ
Beginners and experienced practitioners make different trade‑offs. Here’s a simple view:
ApproachBeginnersExperienced practitionersIntent handlingOne prompt per taskIntent + confidence + fallback questionPolicy integrationRules after generationRules inside generation and pre‑send checksHandoffsManual, often lateTimed, with full context packageFailure recoveryApologize and restartDegrade gracefully, maintain continuityMeasurementMessage length, sentimentPromise accuracy, resolution speed, recontact rate
FAQ
How does generative AI avoid overpromising?
It runs policy and availability checks before sending and prefers soft commits when certainty is low.
What happens when the model is unsure?
It asks a brief clarifying question or routes to a human with context, instead of guessing.
Can this work without full customer history?
Yes, but responses stay conservative and request the minimum needed to move forward.
How are advisors supported, not replaced?
AI drafts, detects edge cases, and packages context so advisors spend time resolving, not retyping.
Where does Lexus see the biggest lift?
In smoother handoffs and fewer broken promises across channels—small improvements, compounding.
Pressure moves to the edges: owning the handoff and the promise
Lexus is leveraging generative AI to reshape customer experience, but the responsibility shifts to the seams: what the system promises, what humans accept, and how the two stay in sync. The more automation helps, the more those seams matter.
The next step isn’t trend chasing. It’s tightening intent signals, sharpening guardrails, and measuring outcomes that customers feel—kept promises, clear options, faster closures. That’s where trust compounds.


