

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Building an n8n workflow for email lead follow-ups sounds straightforward until it touches production volume, real inboxes, and shifting priorities. This is not theory. It’s the glue work that keeps lead intake from stalling and sales from chasing ghosts.
Executive Summary
Most teams treat follow-ups as a linear drip. In production, that model breaks at lead deduplication, email deliverability, and timing. The workflow needs to reflect those pressures or it will burn reputation and waste leads.
n8n gives you the scaffolding, but you still own state, idempotence, and handoffs. Expect friction around who is the source of truth, how suppression lists are enforced, and what happens after a bounce or no response.
The core shape is consistent, intake, validate, decide, send, observe, and react. The shape holds, but the internals change with provider limits, timezone data, and messy data entry. The decisions here are not abstract, they are pragmatic compromises shaped by what failed last time.
If you came for a neat template, you will leave with a blueprint that survives pressure. This covers why we make certain choices, what breaks if we don’t, and where to tighten first when volume spikes.
Introduction
A quarter closes. Marketing launches a landing page, leads trickle in, sales expects replies the same day, and the first wave looks decent. By day three, the inbox is full of auto-replies, soft bounces, and duplicate signups from the same company testing pricing. Follow-ups slowed, reps ask for status, and leadership starts a spreadsheet. That’s the point where "Mastering Email Lead Follow-Ups: A Comprehensive Guide to Building n8n Workflows" stops being a nice idea and becomes a requirement.
The system needs to decide who gets an email, when, and how to recover if the lead bounces or replies with a contact change. You can assemble an n8n workflow for email lead follow-ups quickly, but the moment you hit real volume and compliance, the workflow must carry more logic than you expected. This guide focuses on the operational shape that holds when the environment pushes back.
Production pressure shapes the workflow’s boundaries
A follow-up system is stateful, even if you try to pretend it’s stateless. Intake is noisy, email providers enforce rate limits, and compliance rules change silently. In production you design around deduplication, suppression, personalization, scheduling windows, and error handling. If any one of those is weak, the whole pipeline drifts, either into spam or into silence.
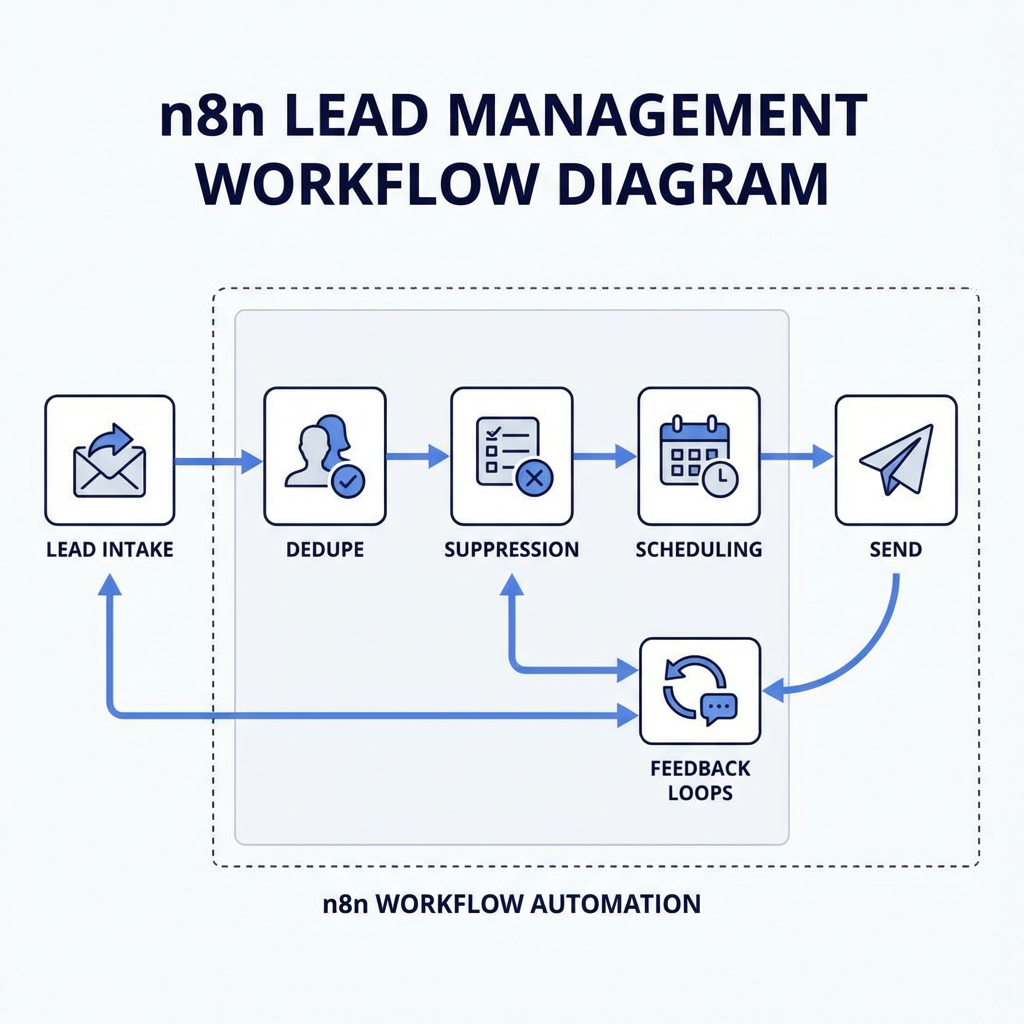
Deduplication sits right after intake. Two signups from the same domain and similar names should not trigger two parallel sequences. Hashing on email plus normalized company domain helps, but catch the near duplicates too, typos, plus aliases. Idempotence matters, if the same webhook fires twice you want the same downstream decision, not two sends an hour apart.
Deliverability is not a switch. Providers throttle by reputation, age of domain, and previous burst patterns. An unthrottled n8n run can burn a warm-up schedule in a day. A rate gate in the workflow is cheaper than rebuilding domain trust. Hard bounces must update suppression immediately. Soft bounces get a retry with a backoff, not a blind second send.
Personalization looks lightweight until fields go missing. You need a fallback strategy that keeps tone consistent without sounding like a form letter. When variables collapse, decide whether to fall back to a generic template or escalate to a manual touch. A missing first name is harmless. A wrong company is not.
Scheduling windows depend on lead timezone and team availability. Send at a reasonable local hour for the lead, but respect internal limits. Don’t run a global batch that fires half your sends at 2 a.m. local to the recipient. If you lack timezone, infer gently from IP or domain, then bias toward mid day windows rather than guessing aggressively.
Sequencing and handoffs create most of the friction
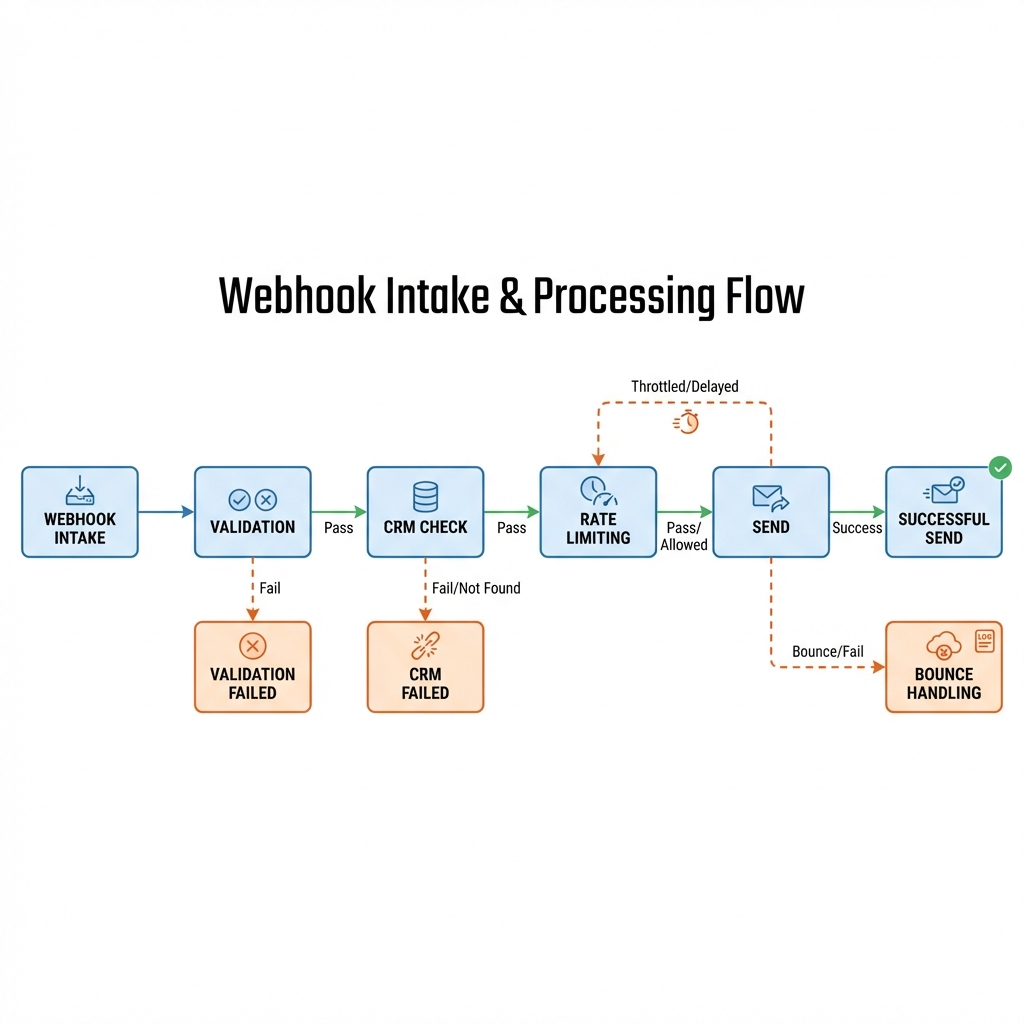
The sequence looks clean on paper, but the handoffs are where you will revisit decisions. Intake from a form or webhook lands in n8n. You validate structure, normalize fields, and check suppression. If the lead passes, tag it for a campaign, then pick a template. That’s the happy path. Reality introduces reassignments and exceptions.
If the CRM already has the contact, decide whether the follow-up belongs to sales or automation. When both run, you spam the lead with two versions of the same pitch. A single toggle, "automation suspended due to active opportunity," prevents that collision. This requires your workflow to read CRM state, not just dump events into it.
Timing is not static. The first email gets a wide window, follow-ups tighten. If there’s a reply, cut the sequence and move to human. If there’s a hard bounce, write to suppression and log the reason. If there’s a soft bounce, retry once with a longer delay, then ask for a different channel. Each branch carries a different risk profile, volume, and downstream effect on reputation.
Tracking links and opens is useful, but treat them as noisy signals. Some leads block pixels. Some click protection breaks your tracking. Use opens as a hint, not an absolute. Use replies and site activity as stronger signals. If a lead opens twice and never clicks, don’t send three more emails on autopilot. Adjust cadence or escalate to a manual check.
There is always a moment where volume spikes. Your rate limiter gets tested, and the provider returns 429 or soft bounce codes. This is the stress test. If your system retries immediately with the same pattern, you teach the provider that you are reckless. If you backoff, split the batch, and spread the sends, you preserve reputation at the cost of latency. That trade-off is acceptable when the alternative is landing in spam.
Tools and technologies under constraint, not preference
n8n earns its keep by making routing and state transitions visible. Cron nodes schedule daily checks, Webhook nodes catch form submissions, and Function nodes handle the glue logic that templates cannot capture. You will reach for HTTP Request to talk to your email provider, not because it looks neat, because the provider specific node often lags features like rate hints or custom headers.
Use a real datastore for suppression and lead state. A sheet looks easy until two concurrent writes collide and the wrong record wins. A simple table in Postgres with unique constraints on email and domain hash cuts off duplicates by default. You don’t need a heavy ORM inside the workflow, you do need queries that fail fast and clearly.
Provider choice carries constraints. Some return detailed bounce codes through webhooks, some hide them behind dashboards. If your workflow cannot consume those events, you operate blind. Postmark and SendGrid handle webhooks cleanly, IMAP polling is a last resort you only use when the provider’s event endpoints are not available. If you run through a shared SMTP, you accept weaker deliverability, then compensate with stricter throttles.
Internal comms matter. Slack alerts can be noisy. Ship a single channel message for anomalies, not every send. Alert when bounce rate crosses a threshold, when a campaign stalls, or when dedupe ratio drops unexpectedly. A flood of alerts trains the team to ignore the only one that matters.
Examples and applications under real pressure
Leads arrive dirty, suppression saves your domain
We shipped a campaign that brought in a lot of free email addresses. Bounce rate climbed fast. The fix wasn’t to block all free domains, it was to tighten validation, MX checks at intake, plus immediate suppression on first hard bounce. The n8n workflow changed, validation moved forward, send moved later. Reputation recovered slowly, but it recovered. Success was not a perfect metric, it was fewer 550 codes week over week.
Timezone guesses, safer windows, fewer complaints
We tried aggressive timezone inference. Wrong guesses produced 6 a.m. emails. That created support tickets. We revised the workflow to default to mid day windows when unsure, and run a second pass for known timezones. Reply rates barely moved, complaint rate dropped. The change was small, adding a branch with conservative scheduling, but the downstream friction vanished.
CRM handoff prevents double touches
Sales complained that automation stepped on active deals. We added a check, before sending, look up the email in CRM and skip if there’s an open opportunity. That saved us from scolding by prospects and reduced unsubscribes. It slowed the workflow slightly due to another API call, but the social cost disappeared overnight.
Tables and comparisons where decisions bite differently
DecisionImpact on newcomersImpact on experienced practitionersOperational consequenceUse sheets for suppressionFeels simple, quick to shipAvoided due to concurrency riskRace conditions, duplicates leak into campaignsSkip CRM check before sendFaster, fewer API callsRed flag, causes double touchesHigher unsubscribes, reputation damageAggressive timezone inferenceLooks smart on paperUsed with cautious defaultsEarly morning sends, complaints, policy reviewsRetry soft bounces immediatelyCommon naive stepReplaced with backoffProvider throttling, higher spam placementSingle template for all segmentsEasy to maintainWeak personalization accepted only with guardrailsLower engagement, uneven brand tone
Required Section A, what this actually looks like when it runs
In production the n8n workflow for email lead follow-ups runs as a living system. Cron schedules batched sends and checks, webhooks accept new leads, a Function node normalizes data, and a datastore gate decides if the email can move forward. Every step writes a trace, because recovery without breadcrumbs is a guess. When one provider coughs up a rate limit, the workflow doesn’t stop, it reroutes into a queue with time based release.
Error paths are not rare. They are the norm. Bounces route to suppression and counters. Replies route to a CRM integration that drops the rest of the sequence. Unsubscribes are absolute, regardless of who triggered the original send. This boundary is non negotiable. If someone tries to push a "short exception" through, you flag it and cut off the sequence forcibly.
Idempotence is enforced twice. First at intake with unique keys, second at send time with a token written alongside the message intent. If a retry execution kicks in due to n8n process restarts, the token stops a second email. Without that, you learn the hard way that infra events leak into recipient experience.
Monitoring is dull and necessary. A daily report of sends, soft and hard bounces, dedupe ratio, and retries tells you whether the system is drifting. This isn’t vanity metrics, it’s pressure management. When dedupe ratio drops suddenly, either marketing shifted targeting or a bot is hammering your form. You respond differently depending on which it is.
Required Section B, how the workflow evolves across environments and handoffs
In development you run against a sandbox email provider, a toy datastore, and fake CRM endpoints. You make timing decisions loosely to unblock logic. In staging you discover that webhooks fire out of order under load. Then you add sequence numbers and tolerate eventual consistency. In production the handoffs harden. The intake gate writes to a durable queue. Sends respect a global throttle and per domain limits. The CRM check introduces latency. You decide that correctness beats speed because reputation is slower to rebuild than a rested lead.
Teams slow down at template changes. Marketing wants edits mid sequence. Engineering wants stability. The workflow must allow a cutover without resending the first email. That means templating separated from sequence intent. You store intent per lead, not just a "current step" pointer. Content changes do not backfill previous steps unless explicitly commanded.
Dependencies matter. If the email provider webhook fails for an hour, your suppression events don’t arrive. You risk resending to bad addresses. Build a fallback pull with a low frequency check. It’s not pretty, it avoids a blast of errors. A post mortem later can simplify the path, but in the moment you choose the path that preserves trust.
Revisiting decisions happens after weird weeks. A conference produces surge traffic with poor signal quality. Your validation sharpens for a month, then relaxes. Keep those changes in configuration rather than code, with clear versioning tagged to campaigns. Otherwise you forget the pivot and diagnose the wrong knob next quarter.
FAQ
Where should suppression live to avoid duplicate sends?
In a durable datastore with unique keys, not a sheet. Write suppression on first hard bounce and enforce it before any send decision.
How do we stop automation when sales engages?
Check the CRM for open opportunities before each send. If found, mark the lead as human handled and halt the sequence.
What’s the minimal retry policy that protects reputation?
Single soft bounce retry with exponential backoff, then switch channel or pause. Hard bounces write to suppression immediately.
How do we handle missing personalization fields without sounding robotic?
Use fallbacks that keep tone neutral. If critical fields are missing, choose a lighter template or route to manual touch.
What metrics actually help day to day?
Dedupe ratio, bounce codes, send throttle hits, reply rate, and stalled sequences. Trend them, don’t chase single day spikes unless they break something.
Pressure shifts from automation to data hygiene and accountability
Given how things behave today, the burden moves from building sequences to maintaining clean intake, honest suppression, and clear handoffs. The n8n workflow for email lead follow-ups becomes a reflection of how disciplined your data and teams are, not just how clever your nodes are.
changes over time flow chart in 1 line: collect -> dedupe -> throttle -> personalize -> reconsider


