
Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Executive Summary
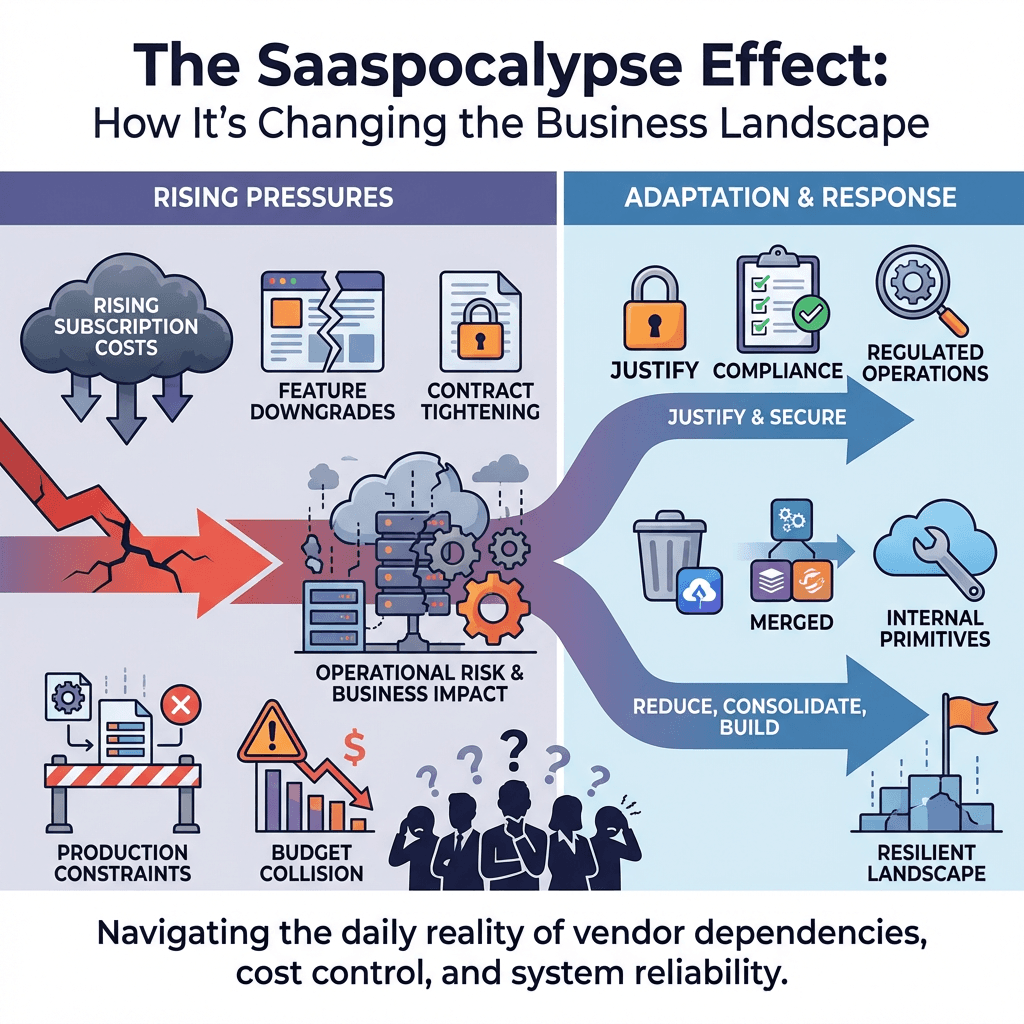
Rising subscription costs, feature downgrades, and contract tightening have turned SaaS portfolios into a source of operational risk. The Saaspocalypse is not a meme, it is a daily reality where business choices collide with production constraints.
Teams are being pushed to justify each vendor by the impact on uptime, latency, and auditability. Some subscriptions make the cut because they enable regulated operations or specialized integrations, others get reduced, consolidated, or replaced by simpler primitives and targeted in-house services.
The Saaspocalypse Effect: How It’s Changing the Business Landscape shows up as sequence, not event. Finance triggers a review, architecture absorbs the stress, ops takes the pager load. Decisions hinge on who carries the risk during transition and what breaks under new limits.
Expect imperfect outcomes. You will accept colder data in one place to preserve hot paths in another, keep a pricey tool for one critical capability while building a thin internal layer around it, and teach stakeholders that cost control is a reliability project, not just a spreadsheet exercise.
Introduction
A quarterly email from finance lands with a quiet directive, pause new subscriptions, re-evaluate renewals, reduce variable spend. Two hours later, a billing rate change in a vendor you barely touch on weekends takes a production pipeline from comfortable to brittle. A free tier disappears, API limits tighten, audit logs move behind a higher plan. This is how the Saaspocalypse feels in motion, small policy shifts creating outsized operational risk.
We surfaced this topic because systems that looked fine on cost and reliability last year are now presenting hidden dependencies under new terms. The Saaspocalypse Effect: How It’s Changing the Business Landscape is visible in the tempo of incidents and the kinds of trade-offs we make. Not theory, but the awkward reality of shipping while vendors reshape their offerings, and budgets force consolidation during active quarters.
Production pressure when subscription dependencies harden
In production, the Saaspocalypse looks like brittle edges around identity, data movement, and observability. Authentication workflows slow as seats get rebalanced, webhook retries hit stricter rate limits, and a reporting export that used to be daily becomes weekly. The breakage is subtle, then suddenly loud. Nightly jobs slip, dashboards lag, compliance checks flag missing logs. Contracts that felt like conveniences start behaving like hard boundaries.
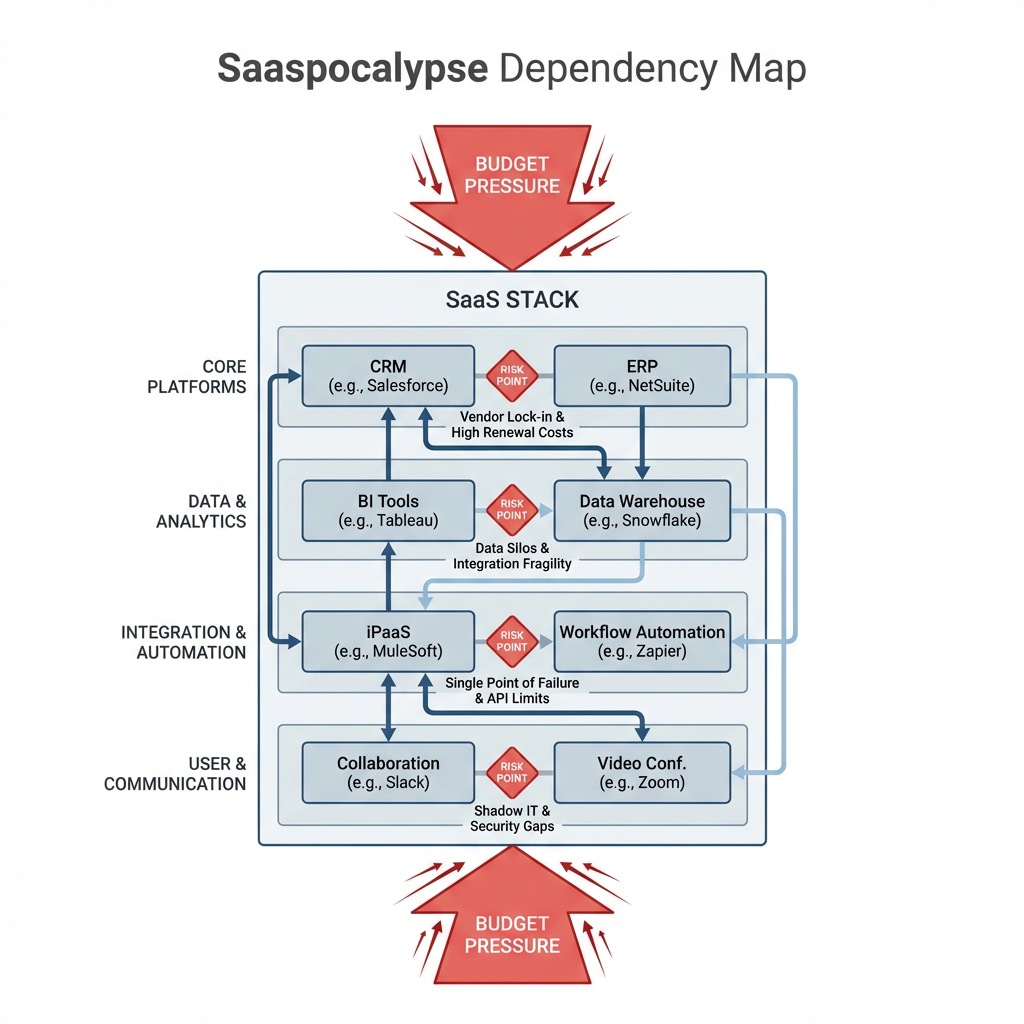
The constraints stack up. Procurement adds review steps before enabling a needed integration, so environment parity drifts and staging no longer mirrors production. Data residency clauses block quick failover to a different region, so recovery plans must absorb latency penalties. Feature caps push teams to multiplex credentials across services, then incident response stalls because you cannot isolate blast radius fast enough. Failure modes pile on top of each other, rate limits colliding with retry storms, deprovisioned seats triggering internal auth loops, new invoicing rules turning background exports into noisy front-line tasks.
Teams start drawing lines. Anything touching customer identity or compliance gets special handling, budget is protected but requires measurable stability. Anything powering internal convenience is fair game for replacement, often with a thinner layer built over cloud primitives. The question shifts from does this tool help us, to does this tool reduce PagerDuty events under stress.
Sequenced fallout across environments when contracts get tightened
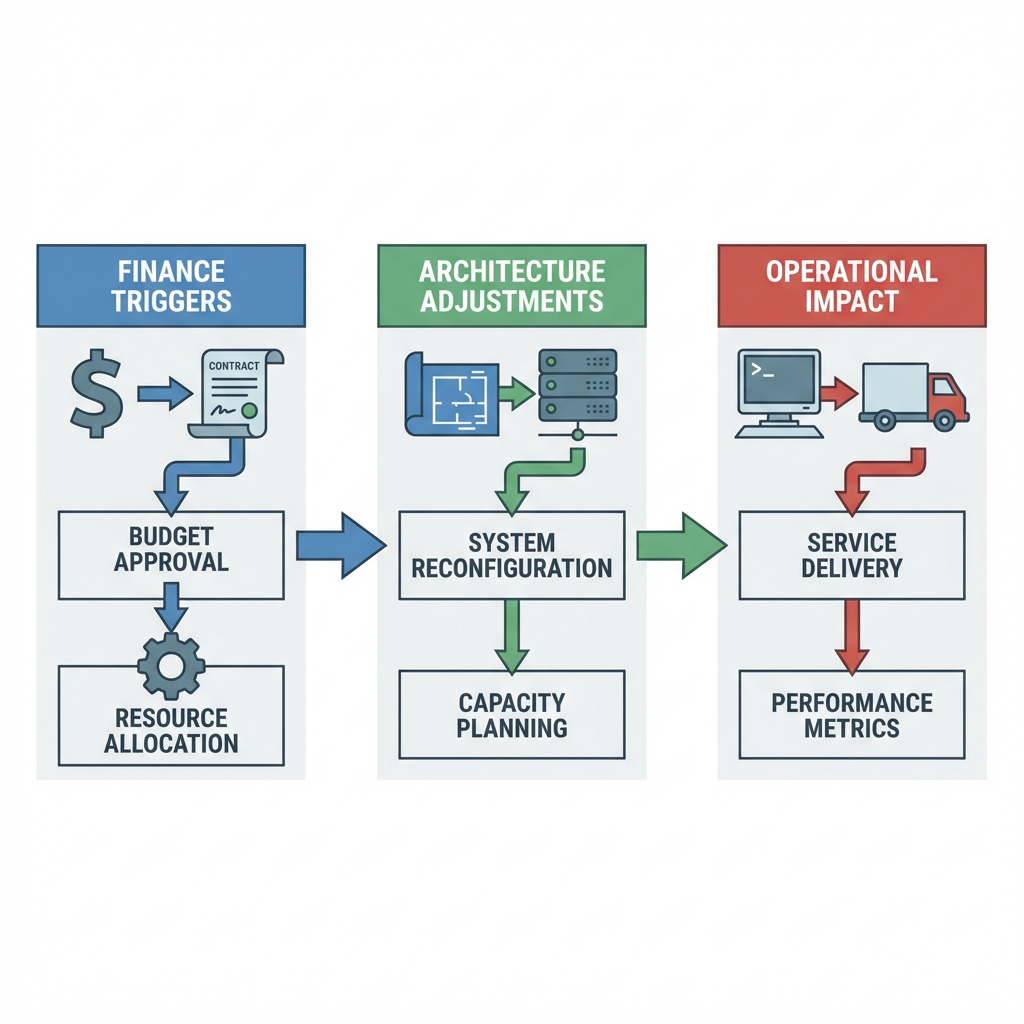
The pattern unfolds in steps. First, finance sets thresholds for usage and seat counts. Then security revisits vendor risk, adding controls that slow access. Engineering maps dependencies and finds the quiet services that turn noisy under new limits. Operations absorbs the mess when jobs, alerts, and billing events collide. The hardest part is handoffs, who owns the gap when a vendor changes behavior and the stack needs refactoring mid-quarter.
Budget pressure hits before architecture adjusts
Renewal cycles do not align with release cycles. A cost clamp arrives while you are halfway through a feature. Seat reductions seem simple until you realize build pipelines rely on service accounts tied to those seats. You ship slower because the architecture is catching up to contracts, not the other way around. The sequencing forces small rewrites, moving from a vendor SDK to direct API calls, swapping out client libraries, and reducing optional hops between services. None of this is free, all of it competes with roadmap work.
Access controls create delivery friction
Security tightens scopes, single sign-on rules change, and SCIM syncs are paused pending a new agreement. Environment parity suffers because staging loses a connector that production still has for a few weeks. Developers start testing local fallbacks that do not exactly match production behavior, so incident risk grows. Teams learn to put release toggles on vendor features, separate credentials per environment, and define hard time windows for migration to keep blast radius contained.
Observability drifts, blind spots appear
When SaaS vendors move logs behind higher tiers, trace depth shrinks and the runbook gets hazy. Ops compensates by pushing more events into the core data plane, then eats the cost in storage or query complexity. Some teams pivot to sampling and tighter SLOs. Others accept slower incident triage and spend time building probes that mimic vendor behavior to detect boundary changes early. You pick the pain you can live with, and live with it publicly during postmortems.
Tools and technologies under price hikes and lock-in pressure
Tool choices become arguments about risk surfaces. An identity provider may stay even under price pressure because it anchors audit trails and regulated workflows. A niche analytics layer may be replaced with queries directly on your warehouse to avoid duplicated storage and seat creep. A managed queue might get traded for a cloud-native message bus, not because vendor is bad, but because billing spikes during bursts created uncomfortable incident patterns.
Teams move away from generic webhooks dependent on third-party retries toward event buses they control, then wrap thin ingestion layers for external systems. Reverse ETL becomes selective, only for data that truly requires it, while bulk exports get re-timed or batched. Monitor cost and reliability together, because cheaper with missing logs is rarely cheaper after an outage. The Saaspocalypse rewards boring primitives where they cut complexity, and keeps specialized tools where they reduce real risk.
Concrete moves when subscription gravity hits production
A team maintaining customer billing notices webhooks throttling after a vendor rate change. They carve out a small relay they own, queue locally, and drain with backoff under strict limits. They keep the vendor, but remove the direct dependency from hot paths.
Another group runs an internal analytics tool that became increasingly expensive with no hard SLA. They collapse reports into the warehouse and schedule extracts to match traffic heat maps. The reporting quality dips during peak windows, but the production service gets back headroom and incidents decline.
Customer notifications are spread across two providers for redundancy. After contract shifts, they migrate cold messages to one provider and keep hot transactional notifications dual-routed through a thin abstraction. Operations carries some complexity, finance gets predictable costs, and the engineering team accepts a maintenance burden because it actually buys reliability.
Who stalls where when subscription gravity kicks in
PressureNewcomers likely responseExperienced practitioners likely responseConsequenceSeat cuts across identity and admin toolsShare accounts, defer access reviewsSplit roles, enforce environment boundariesShort term speed vs long term auditabilityRate limits on webhooks and data exportsIncrease retries, hope for quiet nightsInsert local queues, add circuit breakersLower incident noise, modest build costLogs gated behind higher tiersOperate blind, escalate only on alertsPush critical events into owned telemetryBetter triage, higher storage footprintVendor SDKs changing terms and featuresFreeze upgrades, delay refactorsMove to stable APIs, isolate dependenciesSmoother releases, upfront migration effortProcurement reviews slowing enablementWork around with manual stepsPlan toggles, timeboxed migrationsReduced blast radius, slower feature cadence
Questions that surface when consolidation meets uptime risk
How do we audit hidden dependencies without slowing releases? Tag vendor calls at the boundary, add lightweight tracing on integrations, and review those traces during planning. Keep it simple, make it visible.
Should we replace a high churn SaaS with open source right away? Only if the churn is hitting your hot paths. Replace thin conveniences first, keep specialized tools that stabilize regulated or customer facing work.
Which contracts deserve renegotiation before the others? Start where operational risk is greatest, identity, data movement, observability. If the tool anchors compliance, negotiate terms not features, if it is a convenience, trim or replace.
How do we convince stakeholders this is not just cost cutting? Tie each decision to incident history and SLOs. Show the pager math, a saved dollar that increases pages is not a save.
How do we avoid death by build it ourselves? Define small boundaries, build thin layers, keep boring primitives. If a build choice expands your on call pain, stop.
Responsibility shifts back to engineering to justify every recurring dollar
Given how things behave today, this is what quietly changes next. Finance will keep pushing subscription gravity, security will raise friction on vendor risk, and engineering will own the reliability consequences. Thin internal layers will become the default glue, vendors will be chosen for the risk they remove, not the slides they show.
Cost pressure -> Consolidation -> Critical evaluation -> Selective build vs buy -> Contract discipline


