

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
The Allure of Generative AI in Advertising is obvious: instant variants, endless personalization, fresh creative on demand. Brand reality is less forgiving.
Executive Summary
Generative systems can outpace human creative loops. But in production, speed collides with review queues, policy limits, and subtle brand signals that models don’t intuit.
This piece maps the gap between promise and operations. It’s written from the pressure of real campaigns, where launch windows are fixed and risk tolerance isn’t.
Where generative wins: velocity, exploration, cost per iteration.
Where it breaks: voice drift, off-brief outputs, moderation gates, approval lag.
How to deploy: start narrow, codify guardrails, design reviews for volume, instrument feedback loops.
What changes at scale: taxonomy, asset lifecycle, latency budgets, governance over prompts and data.
Introduction
Picture a team racing toward a seasonal launch. Creative is late. Stakeholders want more variants for more channels. Someone opens a generative tool and, in minutes, you have copy and visuals for every audience slice. Relief. Then the first moderation flags show up. Legal notes appear. A senior brand lead says it sounds nothing like you.
That’s The Allure of Generative AI in Advertising Meets Brand Reality. The Allure of Generative AI in Advertising is real because it changes the math on iteration. It’s trending because channels fragment faster than budgets, and testing needs outrun creative capacity. It’s becoming necessary because audiences expect relevance today, not next quarter.
Where generative ease collides with brand risk
In live environments, generative models behave like interns who can write in any voice, at any volume, but don’t know your hard lines until you teach them. They are great at breadth and fast at first drafts. They are weak at nuance, context, and the unwritten rules your customers feel. Speed, sprawl, scrutiny.
Boundaries appear quickly. Brand guidelines aren’t machine-readable out of the box. Policy rules live in PDFs, not in prompts. Training data reflects public language, not your tone. Even when you get a strong prompt template, it degrades as you stretch to new audiences, new claims, new placements.
Failure patterns repeat. Style drift sneaks in over batches. A small phrasing change trips a platform policy. A layout-bound creative spec breaks when the model improvises. A region-specific reference misfires. The review queue swells because volume rises faster than trust in automation.
Then the operational load shows up. Versioning gets messy. Which output shipped where? Which flagged line was fixed? Who approved it? Without a clear taxonomy, the same mistake recurs across variants. QA becomes the bottleneck you just moved downstream.
What the boundary looks like in practice
There’s a point where more prompts don’t equal more control. You can stack rules and still get a line that feels off. That’s because brand fit isn’t fully captured in discrete words. It’s pacing, rhythm, implied claims, and what you never say. Teams patch this with checklists and word banks, but the gaps remain until those checks are embedded in the generation process and the review flow.
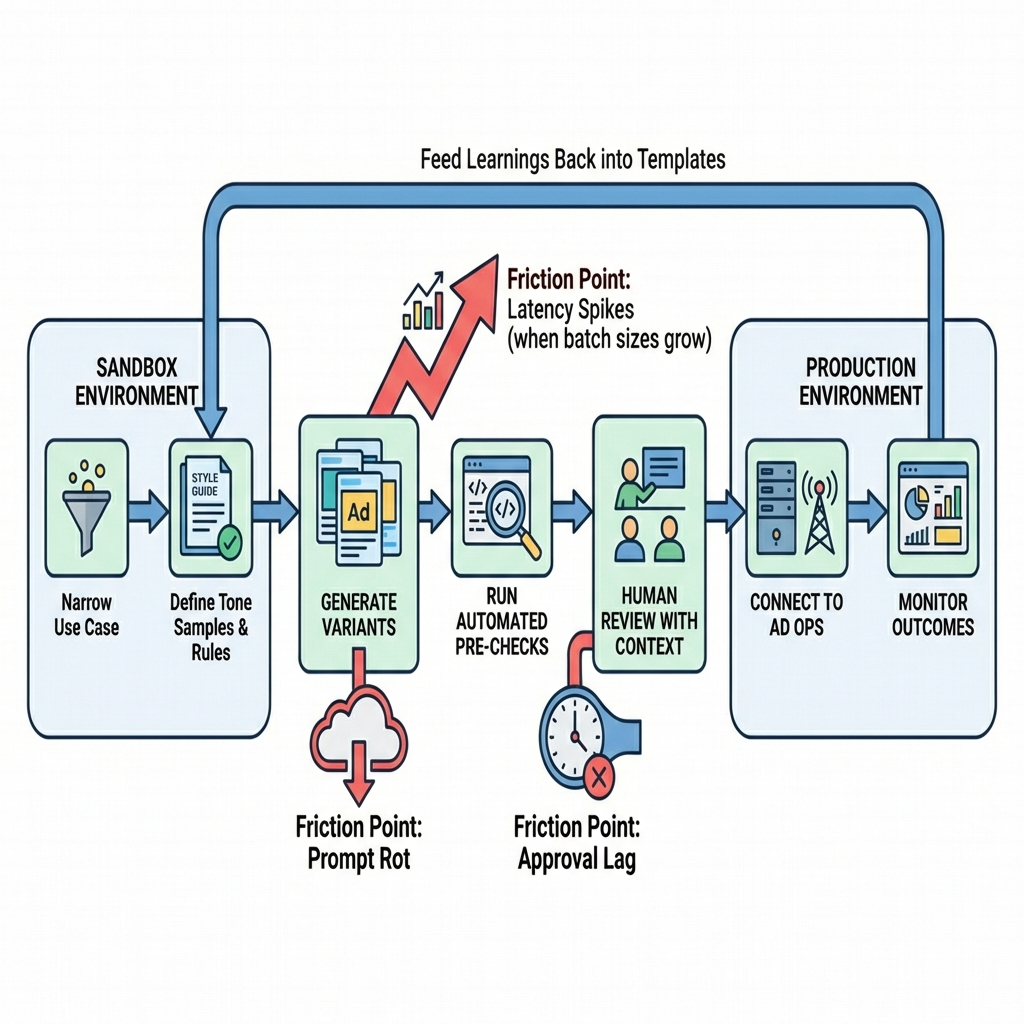
From sandbox to shipping: the path that changes on contact with reality
Rollouts start with a safe slice: one channel, one product, one audience, limited claims. You define a tone sample, assemble do’s and don’ts, and craft a reusable brief. Early wins come fast because the baseline is low and everyone is curious.
Friction appears when outputs must survive policy, legal, and brand review at volume. The same reviewers who could handle a dozen assets are now staring at a hundred. They ask for context: where will this run, what’s the intent, what proof supports the claim. You realize the generation step knows none of that unless you pipe it in.
Where friction appears first
Prompt rot. The template that worked last week underdelivers on a new audience. You patch it, then patch again, and a tree of slightly different prompts starts to form. No one knows which one is canonical.
Approval lag. Outputs that looked fine in the sandbox hit edge cases in production. One phrase runs afoul of a policy. Another implies a guarantee. The queue grows. Cycle time expands.
Context gaps. The model can produce tone, but product details change daily. Without a structured feed and freshness checks, you risk shipping outdated or inconsistent points.
What changes when you scale
Governance becomes the main feature. You need a naming system for variants, a way to capture decisions, and a mechanism to retire weak templates. The work shifts from writing to system design: who can change prompts, how are reviews logged, what happens when a rule updates.
Performance pressure strengthens feedback loops. It’s not enough to generate. You need to connect outcomes to inputs. Which prompt variant consistently clears moderation and performs? Which phrasing drives escalations? Without that tracing, you optimize blindly.
Latency budgets start to matter. Generating a few lines is instant. Generating hundreds with checks, across time zones and languages, is not. Teams blunt this by batching, caching, or switching when generation happens in the process. Each choice trades freshness for stability or speed for oversight.
Examples and applications that don’t go to plan
A campaign lead asks for quick alternates for a headline. The model offers a confident, punchy line that subtly implies a guarantee. It tests well in a small sample. Policy flags it in production. You roll back, lose momentum, and spend a day rewriting. The takeaway: testing can’t ignore policy gravity.
A performance team uses prompts to create dozens of audience-specific variants. Some audiences receive tone that feels too casual. Engagement looks fine, complaints spike in one region. The fix is not more adjectives in the prompt; it’s a structured tone ladder and pre-approved patterns that reflect cultural context.
A product feed powers dynamic descriptions. The generator pulls attributes that are technically correct but framed in ways your brand avoids. You patch with banned phrases, then discover a new synonym slipped through. The resolution isn’t a longer list; it’s a controlled vocabulary and an enforcement step before output leaves the system.
A social unit experiments with visual variants. Looks great on desktop. Crops poorly on a specific placement. The team assumed the generator understood spec nuance. It didn’t. Now, templates include hard constraints and a post-generation audit that checks render, not just content.
Tables and comparisons
Topic Beginners Experienced Practitioners Starting point Open-ended prompts and ad hoc tests Structured briefs, tone samples, fixed templates Brand guardrails Lists of banned words Controlled vocabulary, claim tiers, contextual rules Review process Manual spot checks Tiered reviews with automated pre-checks and logging Measurement Looks at click metrics in isolation Links outcomes to prompts, policies, and approvals Scaling approach More prompts, more variants Fewer, stronger patterns with lifecycle management
FAQ
How do we keep brand voice without hand-writing everything?
Codify tone with examples, not adjectives. Use controlled vocabularies and embed them in generation and review, not just in guidelines.
What’s the fastest safe place to start?
Pick a low-risk unit with clear specs. Build one strong template, one review path, and measure clearance rate as much as performance.
Do we need custom training to sound like us?
Not always. Good sampling of on-brand copy and strict guardrails often beats heavy modeling. Train only where examples and rules can’t cover nuance.
How do we reduce moderation and legal escalations?
Translate policy into machine-checkable rules. Pre-screen outputs before human review. Track escalations and tune inputs to avoid repeat trips.
What proves value beyond speed?
Show reduced rework, higher clearance rates, and stable performance across variants tied back to consistent templates.
Rising volume shifts responsibility from copy to systems
The Allure of Generative AI in Advertising doesn’t vanish. It matures. As teams push for scale, the work becomes less about crafting a single great line and more about designing environments where great lines appear reliably and safely.
That responsibility moves toward system stewards. People who translate brand and policy into structures the machines and the reviewers can follow. When that happens, speed stops being a gamble and starts being an asset you can plan around.


