

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Executive Summary
Teams are committing real budgets to AI and Automation because the pressure to move faster is not theoretical. The pull is simple, plug in a model, wrap a workflow, claim a productivity leap. The pushback arrives later when data contracts crack, latency piles up, and a help desk becomes the first line of model ops.
This piece focuses on how open AI interfaces change production behavior, not hypothetical lab wins. When you wire models into revenue paths you inherit new failure modes, new coordination costs, and a different cadence for shipping and rollback. That shift changes who owns what, and when.
You will not find polished frameworks here. You will find how decisions were made under pressure, which ones aged poorly, and the messy parts no one wants to budget for, such as monitoring prompts, taming drift, and negotiating governance without stalling delivery.
If you are deciding whether to embed AI through an open ecosystem, or expand an existing footprint, the consequence profiles matter more than capability lists. The path that looks light at the start gets heavy when incidents hit and policies tighten.
Introduction
We had a quarter where three features depended on model outputs, two were customer facing, one was back office. The demo looked great, then support volumes doubled because model reversions were inconsistent, and the back office process started missing handoffs. That week raised a single requirement, stop treating AI as a toy, treat it as a dependency with real consequences. The Impact of Open AI on Modern Technology and Innovation in 2026 is not about new toys, it is about how interfaces, policies, and costs change the way teams build and operate.
AI and Automation are now intertwined with product delivery. You can ship faster, but you also ship new risks, the kind that do not surface in unit tests. Data freshness, prompt governance, and vendor latency become part of the incident runbook. That is why this topic surfaced as a requirement, not a strategy deck. It came out of breakage under load.
Production reality when AI promises collide with cost, latency, and policy
In production, the shape of AI is not the model, it is the pipeline around it. Inputs are constrained by data contracts, transformations are limited by privacy and compliance, and outputs must fit downstream systems that care about determinism. When a model sits in that path, the system inherits a probabilistic core that your SLOs do not naturally align with.
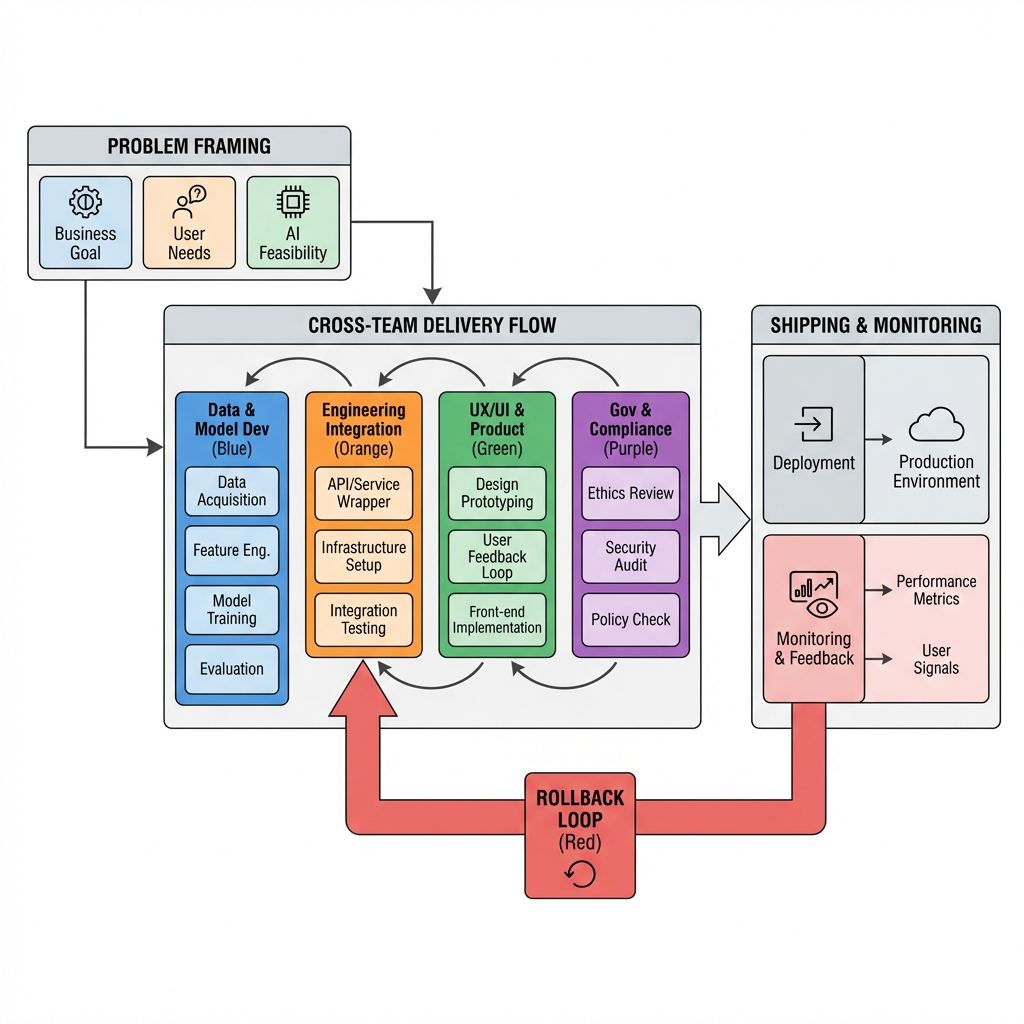
The boundary issues start with data. Training and inference need clean, labeled, permissioned inputs. Most orgs discover their data catalog is optimistic, and their lineage map is a set of assumptions. You end up building a gate, if a record crosses the boundary, it carries a policy tag that decides where the model can touch it. It sounds bureaucratic until an auditor asks how you prevented sensitive data from influencing outputs.
Latency pressure is next. The happy path is cached embeddings and precomputed summaries, the unhappy path is a spike that blows through tokens and turns a snappy feature into a spinner. You can hide some of it behind clever UX, but when you wire AI into a flow that feeds pricing, routing, or customer resolution, that spinner is a real cost. The operational fix is not a code trick, it is a budgeting decision, do we pay for lower latency or accept partial automation and reroute to humans under load.
Failure modes are different, noisy outputs propagate differently than binary failures. You will have incidents where the system did not go down, it went weird. The dashboard stays green while customers experience contradictions. That is where monitoring must change. You watch for semantic regressions and policy violations, not just throughput. It feels uncomfortable because the metrics are fuzzier, but ignoring it means learning about drift through angry tickets.
Governance shows up like gravity. The more the system touches customers, the heavier the review becomes. Teams often try to push governance late, we will add reviews after launch. Reality flips it. The earlier you define policy hooks, the fewer rewrites later. You still ship slower than a pure code feature, yet you avoid those stop ship meetings where legal, security, and product stare at each other and ask how the model decided anything.
Sequencing work across teams when AI becomes a dependency chain
The delivery sequence changes because AI is not a library import, it is a cross team contract. Product defines what decisions or summaries are acceptable, data engineering exposes clean inputs with policy tags, model ops tunes prompts and monitors drift, and platform sets SLOs around latency and cost. The handoffs are brittle at first, then improve as teams decide who owns which edges.
Friction surfaces in two places. First, at problem framing, if product scopes a capability instead of a decision, experiments balloon. You end up with a prompt playground that never stabilizes. The fix is to frame decisions in terms of failure tolerance, what can be wrong and still be useful. Second, at policy enforcement, if governance arrives as a binder instead of hooks, engineers will route around it and you get shadow systems that collapse later under audit.
Dependencies make prioritization noisy. A small change in data labeling can break a downstream classifier, which forces a re prompt cycle that stalls feature work. Teams learn to stage changes, freeze inputs during model updates, then cut over with observability ready. It feels procedural because it is. Without sequencing discipline, you create work loops that burn weeks without visible progress.
There is also a business cadence mismatch. Finance wants predictable unit economics, models deliver variable costs, and platform wants stable latency across regions. Negotiating these requires showing the trade often. For example, raise temperature under low risk, drop it when cost spikes, and route to humans above a certain threshold. The decision is not driven by elegance, it is driven by where the budget sits and how much variability the customer experience can tolerate.
Where teams revisit decisions under pressure
After the first incident, teams reconsider what should be automated. Some flows move from full automation to assistive modes, because the combined cost of latency, monitoring, and policy reviews outweighed the benefit. That is not failure, it is recalibration. The systems that survive choose automation where errors are easy to absorb, and keep humans where nuance matters more than speed.
Tools constrained by governance, not by features
Tool choice often looks flashy until you run it through policy gates. Interfaces that log prompts cleanly, allow structured outputs, and expose cost controls end up winning over those with marginal raw capability gains. This is The Impact of Open AI on Modern Technology and Innovation in 2026 in one sentence, operator friendly beats feature packed when auditors and incident pagers are involved.
Ingest layers that respect data tags become mandatory. Orchestration that can roll back to a safer path is more important than a clever chain. Model hosting with clear isolation guarantees makes risk conversations shorter. Retrieval layers that document source influence avoid nasty surprises when a hallucinated reference slips through. These are not brand calls, they are constraint calls. You pick what reduces blast radius and eases coordination, not what demos best.
Applications that hold up when things get weird
Assisted summarization for internal cases tends to survive incidents because errors only slow resolution, they do not mischarge a customer. Classification of low stakes tickets is similar, you can route wrong once or twice and still recover. In contrast, automated changes to account settings or pricing without a human checkpoint invite trouble. When policy shifts, those flows create headaches.
Another pattern that holds is tiered automation. Let the system propose, show confidence, let a human accept or edit, then learn from the edits. It does not hit the headline numbers, but it keeps the line moving under drift. AI and Automation play differently in assistive mode. You still earn speed, and you avoid the all or nothing bet that explodes during a spike.
Comparing impact under delivery pressure
Newcomers and experienced practitioners feel different pain. One group underestimates handoffs and policy, the other over indexes on governance and ships slower than necessary. The table below is not a checklist, it is a set of decisions you will face. It supports picking an approach based on the consequences you are willing to carry.
Decision AreaNewcomer ImpactExperienced ImpactData readinessAssumes catalog is accurate, discovers policy tags lateInvests early in tagging and lineage, fewer reworksModel integrationOptimizes demos, ignores deterministic constraintsDesigns for structured outputs and fallbacksFailure handlingFocuses on uptime, misses semantic regressionsMonitors for drift, builds rollback pathsDeployment cadenceShips prompts often without stagingStages changes, freezes inputs during cutoverCost visibilityTreats variable costs as noise until finance escalatesSets guardrails, routes to humans on spikesGovernance frictionPushes reviews late, faces stop shipBuilds policy hooks early, ships smoother
FAQ, the doubts that block momentum
How do we keep latency tolerable without blowing the budget You decide which paths get cached, which get assistive stops, and which routes fail fast to a human. Measure cost per successful action, not per call.
What does monitoring look like beyond basic metrics Track semantic drift, policy violations, and confidence aligned to business impact. Add alerting around unusual prompt patterns, not just throughput.
Who owns prompt changes when incidents hit Treat prompts like code with review and rollback. Product frames the decision boundary, model ops edits, platform gates the release, and support validates outcomes.
How do we avoid governance halting delivery Put policy hooks in the pipeline. Tag data at ingestion, enforce constraints at inference, and log decisions with context. Reviews shift from paperwork to verifying the hooks work.
Where does AI help most without high risk Internal assistive flows, low stakes classification, and drafting tasks that humans approve. Push full automation only where errors are cheap to absorb.
Responsibility shifts from capability to control
Given how things behave today, the quiet change is that ownership moves from modeling prowess to operational control. Teams that ship reliably are the ones that treat AI as a living dependency, budget for its variability, and wire governance into the workflow before anyone asks.
model drift -> policy refactor -> workflow rebalancing -> budget reallocation -> accountability moves to product


