
Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Executive Summary
Teams keep wiring Vapi + n8n to move from manual handoffs to dependable automation. It sounds simple until volume, latency, and brittle payloads show up.
This guide focuses on how the stack behaves when it’s not a demo day. You’ll see where it flexes, where it folds, and how to design for the messy middle.
Map Vapi events to n8n triggers without chasing ghosts or duplicates.
Shape payloads for predictable runs and reversible actions.
Choose idempotency patterns that survive retries and lag.
Scale with guardrails: rate limits, backoffs, and observability.
Introduction
You’re in a sprint, not a lab. A teammate ships a Vapi interaction that produces useful context, then hands it to you to automate next steps. You open n8n, wire a quick flow, and it works twice. On the third run a payload shape changes, a timeout hits, and your channel fills with half-done tasks.
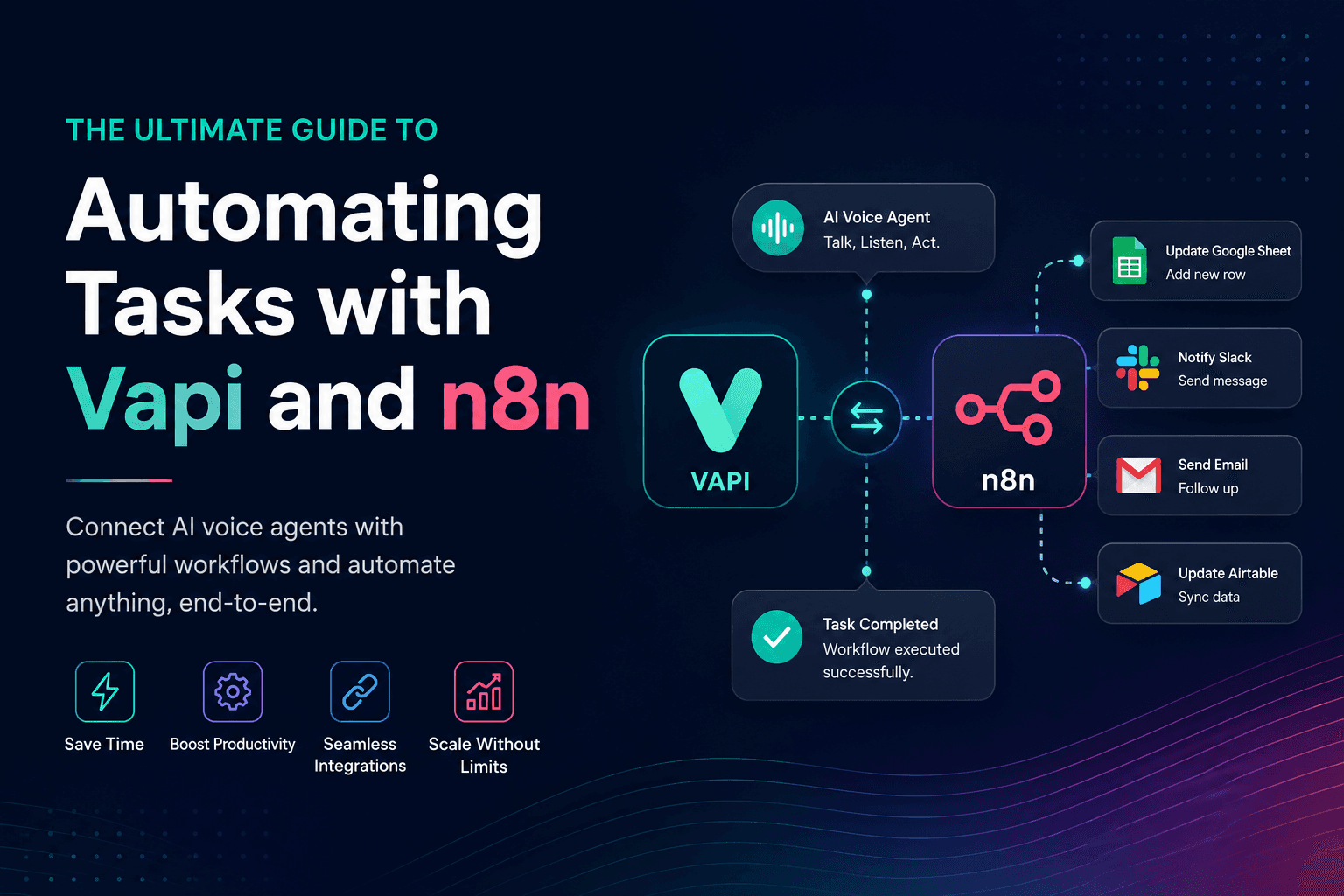
Vapi + n8n is showing up in more roadmaps because it balances speed with control. Vapi gathers signal from conversations or AI-driven calls. n8n turns that signal into action with low ceremony. The gap is all the parts that get hand waved: webhooks, state, partial failures, and what happens under load.
The Ultimate Guide to Automating Tasks with Vapi and n8n is not about feature lists. It’s about choices that carry consequences. If you get the boundaries right, you’ll spend less time firefighting and more time shipping.
What happens when Vapi meets n8n on a busy day
Concept: Edges between real-time AI events and queued jobs
Vapi tends to emit events closer to real time than the rest of your stack. n8n is happiest when work is deterministic and recoverable. The two meet cleanly when you decouple ingestion from execution and treat every event as advice, not truth.
Failure patterns cluster around three spots. First, handshakes: if the webhook or auth breaks, you silently lose events or keep replaying them. Second, shape drift: fields appear or vanish when Vapi’s output changes, and downstream nodes throw. Third, pacing: spikes from Vapi can flood a single workflow if you don’t gate concurrency.
The boundary is timing. Vapi events feel urgent. n8n actions must be safe. That means you lean on idempotency keys, conditional guards, and checkpoints. If an action can be repeated, it will be. If an action cannot be repeated, you guard it with a dedupe gate and persist the decision before doing the work.
Another boundary is context size. Large transcripts or embeddings invite overfetch in n8n. Pull only what’s needed for the next action. Store the rest where it belongs, and pass references, not blobs.
From first trigger to reliable runs
Start with a single trigger that can be observed. Use a test route that you can replay without guessing. Keep the first node after the trigger as a logger or validator. If a payload doesn’t match expectations, stop early and record it.
Normalize event identity next. Extract a stable key from Vapi’s payload. If it’s missing, derive one from consistent fields. Use that key for deduping and for correlating retries. Store it in a lightweight store or a notes field that you can query fast.
Transform before you branch. One transform node should produce a tidy object that downstream nodes can rely on. If you branch early, you’ll chase shape drift in multiple paths. Keep transformations centralized until the data is boring.
Add a backpressure plan. n8n gives you queue-like behavior if you keep concurrency low and break heavy operations into separate workflows. Don’t fight the platform. Use small, sharp flows that pass references between them.
Build reversible steps. If an action can’t be safely repeated, wrap it with a check. Record that it ran, with enough context to reconcile later. If reversal is not possible, move it later in the flow when you’re confident the upstream is stable.
Only then add notifications. Alert fatigue is real. Start with one signal: when a run halts awaiting input, or when a non-retryable error is detected. You want fewer pings, richer context.
When scale arrives, two things change. First, timeouts surface in surprising places. Long LLM calls or fetches need guardrails and retries with jitter. Second, concurrency becomes your throttle. You’ll trade speed for stability by lowering parallelism and increasing buffering.
Scrappy builds that carry weight
Routing follow-ups from a call
A lean team listens for a Vapi event that signals a completed interaction. n8n grabs the summary, checks for a matching contact, and schedules a follow-up. It works until event bursts arrive. Without a dedupe key, follow-ups double-book. The fix was boring: store a run signature, check before creating tasks, and accept one extra read per event.
Triaging transcripts into tasks
Another team extracts action items. Early runs were fine, then the transcript structure changed. A transform node expected a field that moved. Everything broke at once. The recovery was to isolate the transform into one node and add a small schema check. Downstream nodes only read from the cleaned object, not from raw payloads.
Escalation with human-in-the-loop
You might pipe certain Vapi signals to a human review step. n8n pauses, waits for a decision, then proceeds. The friction shows up in stale context. If the pause lasts long enough, data goes stale. The outcome improves when the flow refreshes critical data right before taking a final action, not when it pauses.
Trade-offs you will feel, not just read about
Speed vs safety
Pushing everything in real time feels great until a spike lands. Buffering adds latency but buys you control. Teams tend to start fast and then insert gates when they see failure clusters. That’s normal.
One big workflow vs many small ones
One big flow is easy to reason about until it isn’t. Many small flows are easier to scale and recover but require correlation. If you split, standardize how you pass IDs and references. If you keep it big, be ready for heavier maintenance when fields shift.
Human signals vs automated outcomes
Vapi can surface nuanced intent. Automations can only act on explicit rules. The gray zone is where misfires happen. Add small guardrails: confidence checks, whitelists, and human checkpoints when stakes are high.
Simple comparison: how approaches evolve
Area Beginners Experienced practitioners Trigger choice Direct webhook to one big flow Ingress flow that validates, then forwards Data shaping Use raw payload everywhere Single normalize node, typed object downstream Idempotency Assume events are unique Persist keys, check before write Error handling Global catch, generic retry Per-action policies, selective alerts Scaling Raise concurrency Lower concurrency, add buffers and split flows Observability Logs only when broken Lightweight correlation IDs and run traces Schema drift Fix nodes one by one Guarded transform, tests on key paths
Short answers to common snags
How do I stop duplicate actions from retries?
Use a stable event key and record it before doing work. Check the key at the start of each run.
What if Vapi’s payload changes shape?
Add a validation node early. Default missing fields, and fail fast with context when critical fields shift.
Where should I store large context like transcripts?
Keep it outside the workflow engine. Pass a reference and fetch only the parts you need.
How do I handle spikes without dropping events?
Buffer at ingress, limit concurrency, and prefer smaller flows linked by IDs.
When do I involve a human?
When confidence is low or the action is irreversible. Place the review before the irreversible step.
Responsibility is shifting from wiring to reliability
Vapi + n8n made wiring easy. Now the pressure is on for stable runs, clear rollbacks, and quiet on-call shifts. The job moves from connecting nodes to managing flow health.
Concepts beat tools here. Idempotency, small sharp flows, and thoughtful pacing age well. When the next feature lands, you’ll adjust a transform, not your sleep.