

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
If you are considering n8n automated workflows to reduce toil and risk, this is a grounded walk through what actually holds up when the traffic, failures, and politics show up.
Executive Summary
Automation does not fail in the obvious places. It fails in the quiet edges where credentials drift, payloads change shape, or a vendor hiccups during your billing window. n8n can absorb a lot of that pain when you set it up with the right boundaries and expectations.
This piece focuses on production realities, not feature tours. It covers how workflows behave under unreliable APIs, how queues and workers affect latency, how to keep runs idempotent when retries pile up, and what changes when multiple teams share one orchestration surface.
You will see how sequencing across environments introduces friction, why rate limits shape architecture more than code style, and where observability pays for itself. The aim is steady outcomes, not perfect ones.
If you are already deep into automation, you will recognize the trade offs between speed and safety. If you are new, you will avoid a few early bruises by designing around the constraints that actually show up.
Introduction
Picture a quarter close where your support system, CRM, and billing tool all need to reconcile within hours. A single change in an external API’s date format starts returning partial data. Manual patches burn time, mistakes creep in, and the backlog grows. The meeting after is not about blame, it is about risk. That is usually when Transform Your Processes with n8n: The Future of Automated Workflows stops sounding like a slogan and becomes a requirement.
We pulled brittle scripts into n8n automated workflows to create a place where errors routed consistently, retries had shape, and data moved with a paper trail. It was not glamorous. The first win was simply not losing data during a vendor outage. From there, the improvements were incremental and practical, tied to constraints we could not negotiate away, like rate limits and shared credentials.
Production pressure reshapes how n8n behaves and what you must defend
In production, n8n is not just a canvas of nodes. It becomes an execution surface that sits between flaky endpoints and impatient stakeholders. The workflow engine runs under Node.js, tied to storage that holds executions and credentials, subject to memory, I/O, and network variability. When volume spikes or a vendor throttles you, behavior changes fast, and those changes surface as queue backlogs, timeouts, and partial runs.
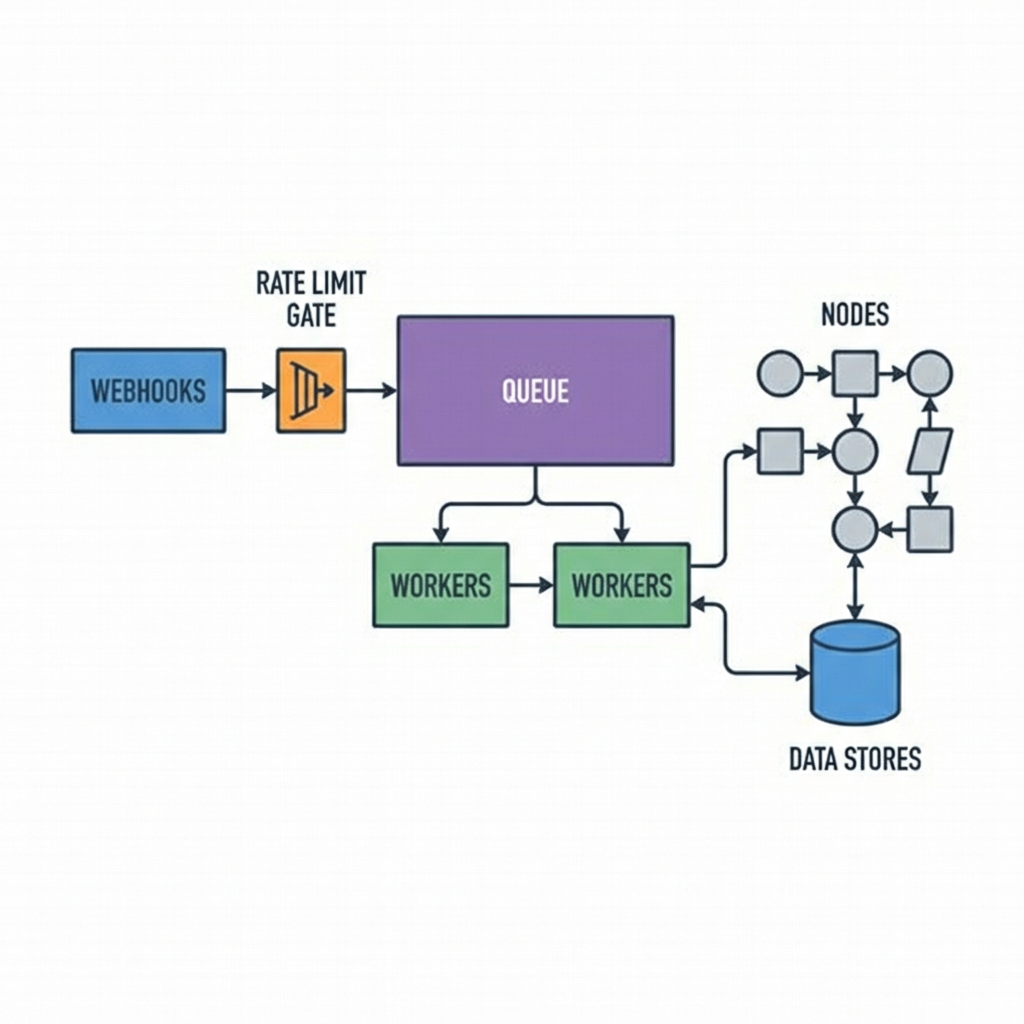
Triggers define your blast radius. Webhooks give you low latency but force you to think about concurrency and back pressure. Scheduled triggers provide stability but add latency and batch effects. If a webhook spikes, a single main process can buckle, so queue mode with workers becomes the lever. That shift buys you throughput and isolation, but it also introduces ordering questions. Two workers can process similar events in parallel and reorder across upstream systems unless you key your logic and persist offsets or dedupe keys.
Retries must be deliberate. Automatic retries make demos look resilient, but in production they can double page counts or cause duplicate side effects. A payment captured twice is far worse than a failed run that alerts. We enforced idempotency by writing external reference IDs and checking before action nodes. It slowed us down a bit, but it avoided very public mistakes.
Error workflows are quiet heroes. Routing failures into a dedicated error flow with context lets you triage without re-running entire pipelines. We learned to attach enough metadata to debug without exposing secrets. This meant stripping tokens from logs, adding correlation IDs, and persisting a small, query friendly subset of payloads for investigation.
Binary data is a memory trap. Large files moving through nodes can saturate memory and stall the process. Offloading to object storage, then passing references, reduced memory pressure and cut timeouts. It also forced us to handle expiry and permissions, a fair trade for stability.
Credentials management is an operational dependency, not an afterthought. Rotations will happen on the worst day. Keep credentials scoped and labeled with owners and expiry dates, and separate environment secrets. If a shared secret changes in production while staging still runs old versions, expect ghost failures that look random at first glance.
Sequencing and handoffs across environments expose hidden coupling
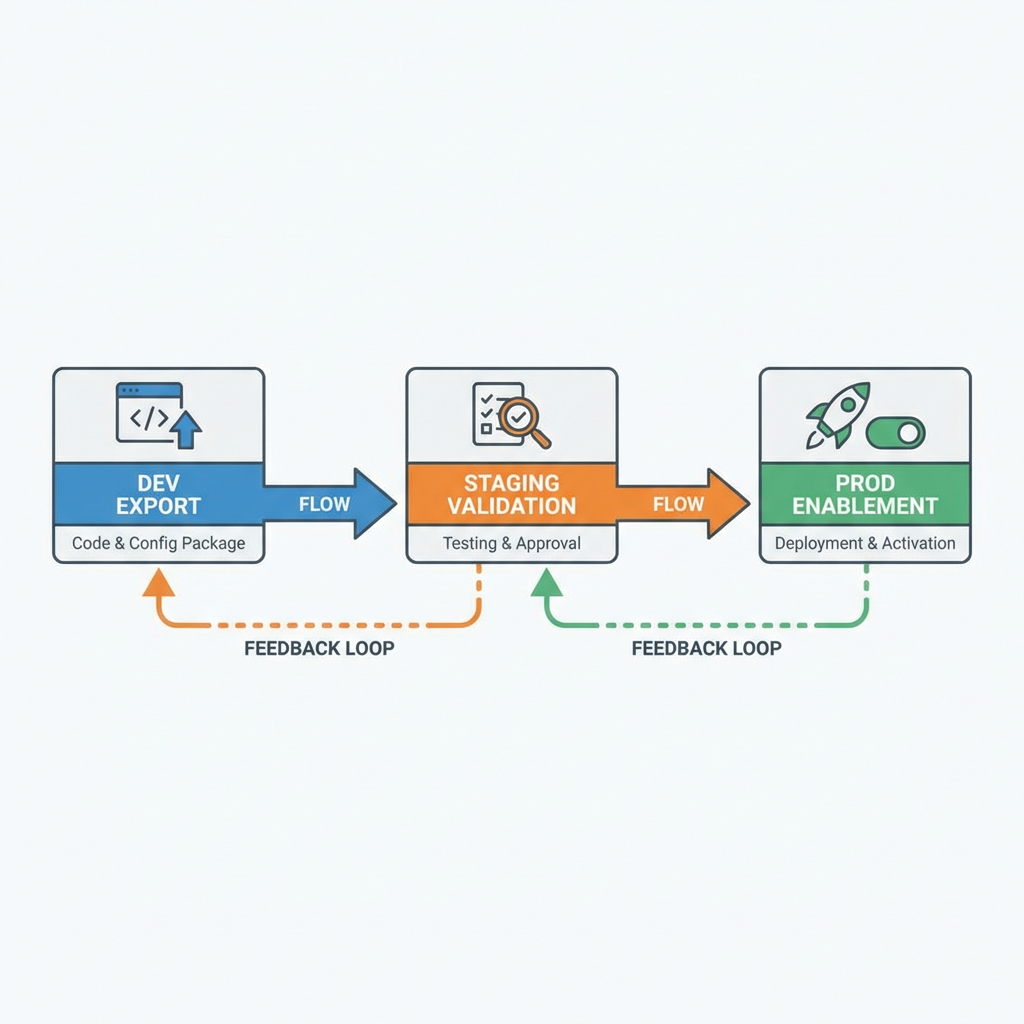
Moving from a local proof to a shared service introduces a long chain of dependencies. The sequence usually looks simple until you model real handoffs. A developer exports a workflow JSON, another reviews it, credentials differ across staging and prod, schedules shift, and the deployment window collides with a vendor maintenance period. Each step introduces small drift that a single person cannot see end to end.
We learned to stage triggers off by default. Deploy to staging with triggers disabled, verify credentials and sample runs, then enable the schedule or webhook mapping deliberately. That one habit avoided double ingestion when an old schedule lingered on another host.
Handoffs across teams surface schema drift. Upstream teams add fields, rename, or change types. If your nodes assume shape, runs start failing on weekends. We guarded inputs with validation nodes and small pre processors that mapped contract changes to internal shapes. That added work, but it made failures clear and recoverable by design rather than surprise exceptions deep in a flow.
Rate limits determine your plan more than throughput numbers. APIs that allow bursts but punish sustained spikes require adaptive pacing. We used backoff nodes and queue workers keyed per integration to avoid saturating a single vendor. Occasionally, the right answer was to pre aggregate events and push summaries on an interval, trading immediacy for reliability.
Rollback is awkward because workflows are live things, not binary releases. Rolling back a JSON export does not rewind side effects. We treat rollbacks as new versions that stop the bleeding and preserve state, then write follow up compensations. The goal is containment, not time travel.
Tools that limit, unblock, or force a call
Decisions around tools tend to clarify once you connect them to constraints. When webhook bursts threaten stability, queue mode with a backing store and workers becomes less about feature checklists and more about absorbing load without dropping events. We introduced a Redis backed queue to decouple triggers from processing, then adjusted worker concurrency based on API tolerance, not on VM size.
Storage choices ripple into uptime. Persisting execution data in a durable database kept audits intact but increased write pressure during spikes. We tuned retention windows and archived bodies larger than a threshold to object storage, referencing them by key. This kept the database responsive when we needed it most.
Reverse proxies in front of webhooks solved TLS needs and let us shape traffic, but they also hid client IPs until we forwarded headers properly. That detail matters when you build allowlists or correlate incidents. We captured those headers into workflow context early to avoid silent blind spots.
Observability pays off only if you wire it to decisions. We exported workflow metrics and linked them to alert thresholds tied to business impact. For example, if the backlog in a critical flow crossed a threshold for more than a short span, we paged and shed non critical work. Dashboards were helpful, but budgets and pages changed behavior.
Workflows that earned their keep, and what it cost
One pattern that proved reliable was syncing records across systems with eventual consistency. We accepted that real time would not survive rate limits and designed for reconciliation. Items flowed quickly with light validation, then a scheduled job checked parity and patched gaps. The cost was delayed correctness, the benefit was fewer fire drills.
Another case was enriching tickets with data from a slow vendor API. We split the flow into an immediate lightweight tagger and a deferred enricher feeding off a queue. Support got quick visibility, deeper context arrived later. Complaints about lag were easier to handle than stalled tickets or timeouts.
Invoice generation became manageable when we pushed file rendering out of the hot path. We generated descriptors in the main flow and handed binaries to a worker dedicated to rendering and uploading. Failures in the renderer triggered alerts without blocking upstream processing. Finance cared about totals and delivery, not whether the PDF came twenty minutes later.
We also learned the hard way that connecting too many responsibilities into one monster workflow made changes risky. Smaller flows linked by clear contracts cost more at first but saved hours during incident response. When a vendor changed an endpoint, we touched a thin adapter instead of a tangle of nodes.
Where newcomers and veterans make different calls under pressure
The table below captures choices that tend to diverge once production pressure shows up. It is not about right or wrong, it is about consequences you can live with.
Decision pointNewcomer moveConsequenceExperienced moveConsequenceRetries on external actionsEnable generous automatic retriesDuplicates or side effects pile up during outagesGuard with idempotency keys and bounded retriesFewer surprises, more work upfrontThroughput during burstsIncrease worker concurrency globallyVendor throttling and reordered eventsKey concurrency per integration and add backoffStable processing, slightly higher latencyData handling for large filesPass binaries through nodesMemory pressure and timeoutsStore externally and pass referencesExtra plumbing, lower riskSchema changes upstreamAssume fields remain stableWeekend failures after silent deploysValidate and map into internal shapesPredictable breakpoints and alertsRollbacksRe import old workflowSide effects remain inconsistentCreate compensating versionsContainment over neat reversalsCredentials rotationShare a single prod credentialBlast radius during rotation eventsScope and label per responsibilityMore management, safer changes
Hard questions that come up after the first few incidents
How do we prevent duplicated processing when a vendor retries webhooks? Use a dedupe key derived from the provider’s event ID and store it briefly in a fast store. Check before processing. If the vendor lacks stable IDs, derive a hash from key fields and time windows, then accept rare false positives over duplicates.
What should we monitor first, the platform or the workflows? Start with business outcomes tied to specific flows, then add platform health. Backlog age and failure rate per critical workflow are early signals. CPU graphs are interesting, but stakeholders need to know when deliveries slip.
How do we test changes without replaying production data? Create fixtures that mimic shape and volume, and run them through staging with triggers disabled. For stateful flows, snapshot external systems or simulate endpoints so you can verify idempotency and ordering without making real side effects.
When is it worth moving to a worker and queue setup? Once webhook bursts or schedules collide and you see consistent timeouts or growing backlogs, separate ingestion from processing. If a single failure can stall unrelated flows, you are past the point of needing workers.
Given today’s constraints, responsibility shifts toward orchestration choices
Given how things behave today, this is what quietly changes next. As more teams share n8n, the center of gravity moves from building nodes to defining contracts, limits, and failure handling. The hard work becomes shaping flows that fail safely, recover deliberately, and leave evidence that people can act on.
ad hoc scripts -> shared nodes -> managed queues -> governed workflows


