

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Executive Summary
Web Development changes when deadlines are real, users are live, and constraints stack up. The work becomes a game of trade-offs rather than feature lists.
This piece maps how those trade-offs behave, where teams usually trip, and what shifts when small projects become systems.
Understand common failure patterns: state drift, performance regressions, handoff gaps
See how implementation flows from intake to production when the clock is running
Learn what changes at scale: more coordination, stricter budgets, slower decision loops
Use examples that show imperfect outcomes and the real friction behind them
Introduction
The late message lands: a critical path is failing on certain devices. The release calendar is full. The owner wants it live by morning. This is the texture of Web Development most people don’t talk about. It’s not a demo. It’s a system under pressure.
Web Development today isn’t just components and routes. It’s trade-offs across UX, security, performance, accessibility, data contracts, and release safety. It’s reading logs between meetings. It’s choosing which test you will not write because you simply won’t make it.
It’s trending because the surface area exploded: more devices, more privacy rules, more integrations, more expectations. Meanwhile, teams are smaller, cycles are tighter, and failures are loud. Doing less but better is no longer a slogan. It’s the only survivable approach.
When Web Development collides with real constraints
In real environments, the unit of work isn’t a ticket. It’s a decision: what will we risk to ship on time. That decision ripples through architecture, testing, and support. Trade-off map: scope, speed, safety.
Boundaries appear fast. Performance budgets shrink on pages that try to be everything at once. Accessibility gets deferred until it blocks a launch, then it becomes expensive. Data models harden after two releases, making “just a small change” anything but.
Failure patterns repeat. State drifts as multiple components try to own the same truth. Network calls creep into places they don’t belong. Visual regressions ship because the stories everyone checked weren’t the ones users touched. A fix for one device quietly breaks another.
The painful part: many of these failures are invisible during development. They surface under real load, with real content, and real user habits. Observability and fast rollback paths aren’t luxury. They’re oxygen.
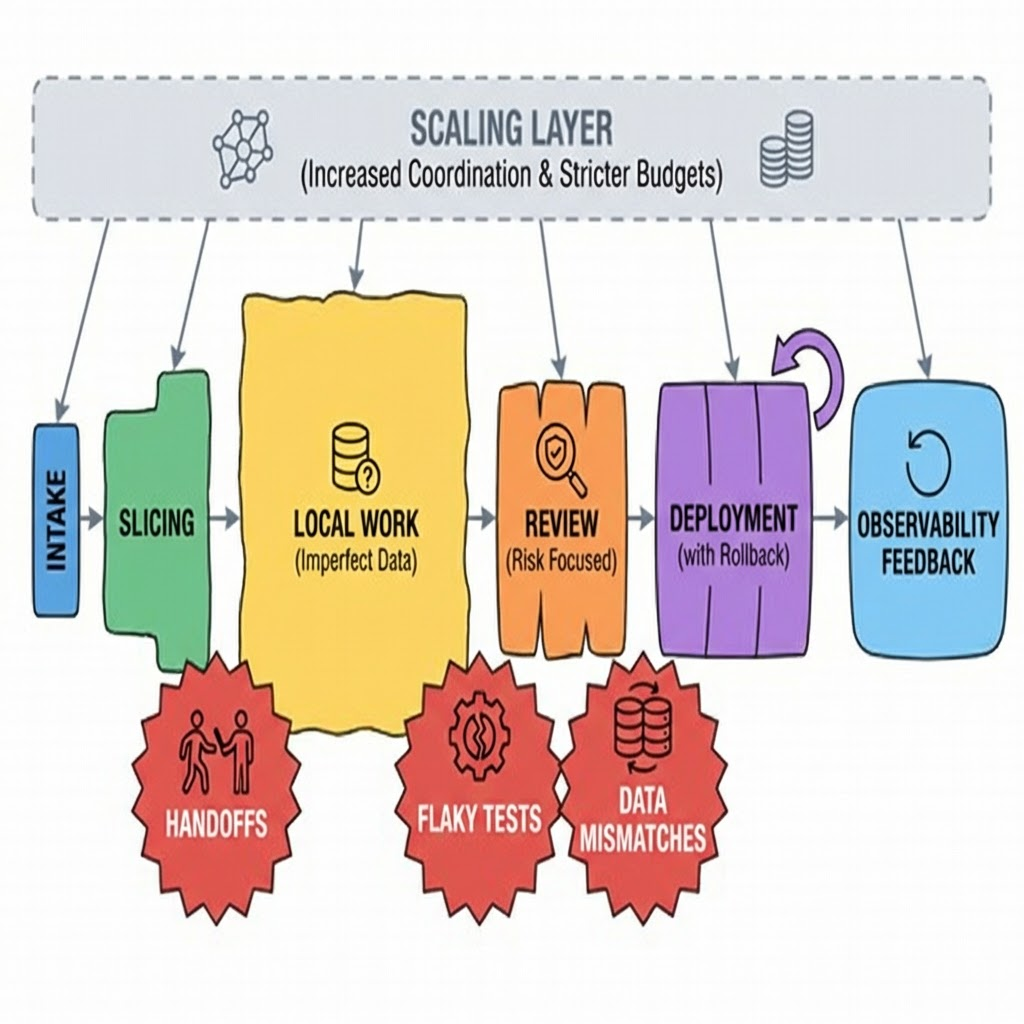
From ticket to production when the clock fights back
Implementation starts with intake, but the shape matters. A vague request creates rework. A too-specific one ignores constraints. The sweet spot is a slice small enough to ship, but large enough to prove the outcome. That slice defines your contracts, test scope, and observability hooks.
Friction shows up at handoffs. Product wants visible progress; engineering wants fewer moving parts. Design wants consistency; operations wants fewer deployments. If you don’t name the trade-off early, you’ll pay it late as a rollback.
Local work reveals a second layer of friction. Data in development rarely matches production. Mock content behaves nicely, real content does not. You solve this by shaping fixtures to your worst cases and wiring logs where you’ll need them, not where it’s convenient.
Reviews should hunt for risk, not style. What will break if this merges. Where does this create a new source of truth. Which dependency are we trusting too much. If reviews only look for patterns, risk slips through.
At scale, everything slows unless you constrain it. Coordination increases. Dependencies multiply. Performance budgets harden. Your definition of done expands: not just tests passing, but alarms quiet, dashboards clean, and no new error class introduced. Release trains become steadier and more boring by design.
Examples and applications that don’t end perfectly
A public page update under traffic
Goal: add an interactive section without hurting load speed. You ship a lightweight interaction first. It works, but analytics shows a drop in engagement for mid-range devices. Turns out the interaction delayed first input. You pare it down again, add a threshold to disable effects on slower hardware, and document the compromise. It’s not ideal. It’s stable.
Fixing an intermittent form failure
Goal: resolve a rare submit bug. You reproduce using throttled network and skewed device settings. Root cause is a timing mismatch between validation and submit. The quick fix patches timing; it passes tests. A week later, support reports stalled submissions in a different path. The fix missed a secondary trigger. You refactor to centralize validation, add a single source of truth for status, and cut two code paths. Longer, safer. The first fix bought you time to do the second.
Pagination vs endless content
Goal: reduce bounce on a dense list. Infinite loading feels slick, until scroll state breaks on back navigation and metrics go sideways. Pagination brings back control. You add prefetching to soften the edges and a jump-to control for deep navigation. Less magical, more usable.
Real-time updates with rate limits
Goal: show fresh data without burning resources. You start with frequent polling. It hits limits. You back off, add a simple backpressure signal, and cache recent views. Latency increases slightly. Complaints drop. Operations sleeps again.
Where learners get stuck vs how experienced operators move
Area Students/Beginners Experienced Practitioners Scoping Ship features Ship outcomes with smallest risky slice State Duplicate for convenience Consolidate ownership, accept extra plumbing Performance Optimize late Set budgets, measure before and after Accessibility Add after design Design with it, test on rough devices Testing Broader than needed Target high-risk paths, mock the rest Deployments Big batches Small batches, clear rollback plan Observability Add after incidents Wire logs and traces while building Error handling Show generic messages Fail visibly, recover locally, log precisely Scope creep Accept to please Freeze scope, capture backlog, ship baseline Scale Rely on defaults Design for load variance and content extremes
FAQ
How do I choose what to build first when everything feels urgent?
Pick the smallest slice that proves the outcome. If it doesn’t change a metric or reduce an incident, it’s not first.
How do I keep performance from drifting?
Set budgets per critical page and track them in the same place you track errors. Refuse merges that push beyond the line.
When is it okay to rewrite?
When the cost of adding a feature exceeds the cost of replacing the bottleneck. Rewrite slices, not systems.
Do I need end-to-end tests?
Enough to protect revenue or critical paths. Everything else is unit or integration. Keep the slow suite small and stable.
How do I handle browser or device inconsistencies?
Test on constraints, not just on your machine. Build for the worst acceptable baseline, then enhance.
Rising pressure to own outcomes end-to-end
The boundary of responsibility is moving. Web Development is expected to land stable experiences, not just merged code. Reliability, privacy, accessibility, and maintainability are no longer handoffs.
The teams that thrive bake these concerns into the first slice. Small releases. Clear rollbacks. Measured impact. Less ceremony. More ownership.


