
Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
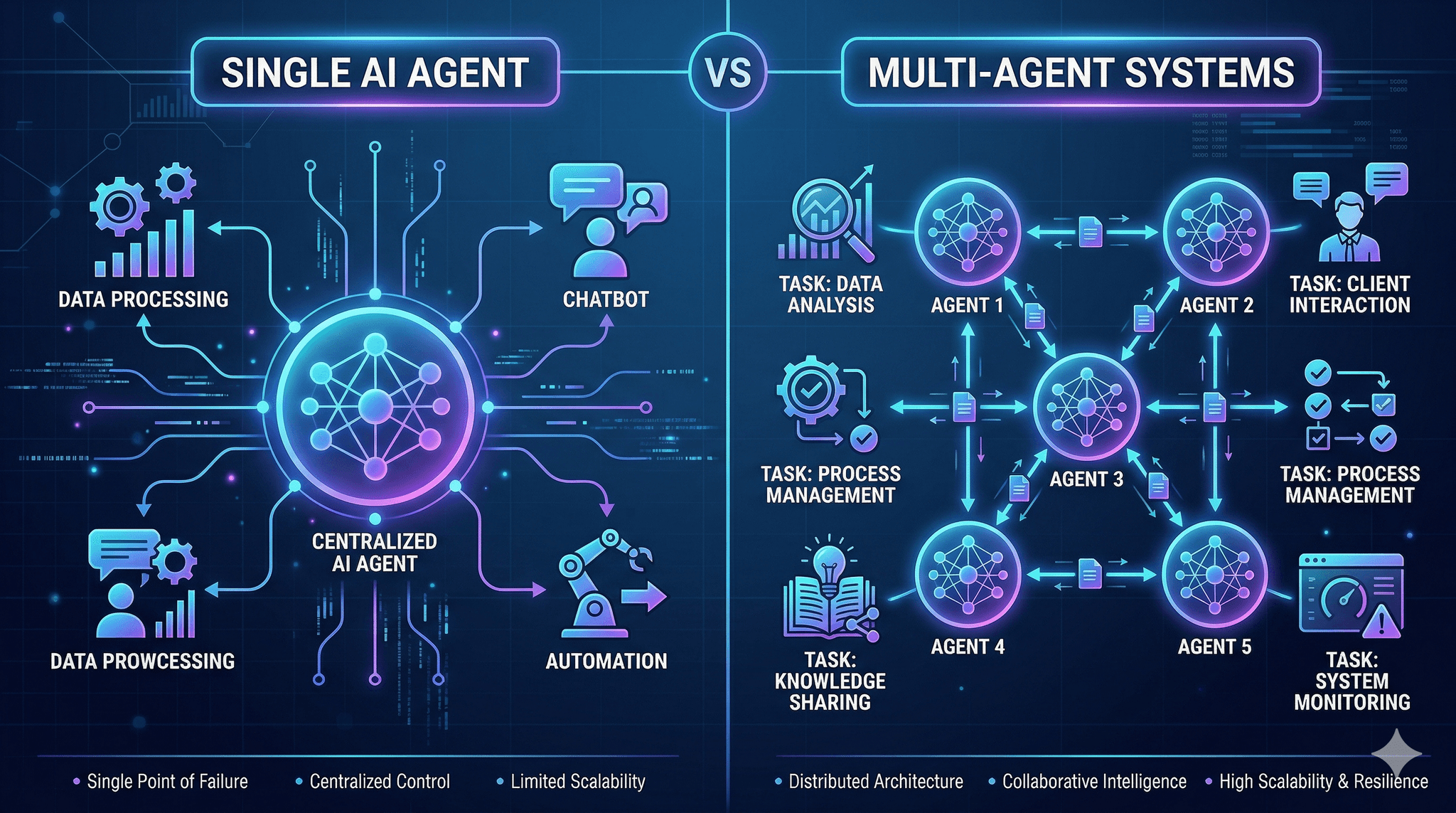
Single AI Agent vs Multi-Agent Systems isn’t a philosophy question. It’s a capacity and consequence decision you’ll live with in production.
Executive Summary
Most teams can ship value faster with a single agent if the problem is narrow and the data surface is stable. Multi-agent setups matter when the work spans different skills, data sources, or policies that can’t be cleanly compressed into one loop.
You’ll trade speed for coordination when you add agents. Sometimes that’s the only way to get reliability, auditability, or throughput. Sometimes it just adds latency and failure points.
When a single agent suffices, it’s usually due to tight scope and a steady input pattern.
Multi-agent is worth it when tasks have separable competencies with clear handoffs.
Evaluate by consequence: error tolerance, oversight needs, scale volatility, and change cadence.
Introduction
Picture a lean team asked to automate a workflow that people already struggle to keep up with. Requirements shift weekly. Data quality is uneven. There’s no appetite for long rewrites. You need something that works now and won’t crumble in a month.
That’s where Single AI Agent vs Multi-Agent Systems stops being a trend and becomes a tactical choice. Single agents offer a compact loop with simpler oversight. Multi-agent systems distribute cognition across roles, with planning and handoffs that can mirror how teams work. Both can fail in different ways.
What Businesses Should Use in 2026 depends on the work’s structure, the blast radius of errors, and how quickly the environment drifts. The topic is trending because teams are moving from demos to durable workflows. It’s becoming necessary because quality, governance, and unit economics are now visible, not theoretical.
Where single agents hold up, and where they don’t
In practice, a single agent performs well when the task is bounded, the input format doesn’t swing wildly, and the acceptable error surface is tight but measurable. It struggles when the task quietly contains multiple skills, or when the context window becomes a catch-all for logic that should be separated.
Concept map of decision points for choosing one agent or several
Boundaries appear fast. One agent that must parse, plan, retrieve context, perform reasoning, and validate results tends to accumulate hidden state. Retries blur cause and effect. You’ll see odd regressions after minor prompt changes because the agent is doing too much with brittle instruction stacking.
Failure patterns look like this: latency spikes as the agent juggles steps without explicit handoffs. Hallucinations increase when retrieval is bolted on without a clear separation between finding facts and using them. Monitoring becomes shallow because you only see the final output, not the intermediate decisions that explain it.
On the other side, multi-agent systems introduce their own failure modes. Inter-agent chatter expands latency. Handoffs get stuck when a downstream agent expects guarantees the upstream can’t provide. You trade a single complex prompt for multiple simpler prompts, but coordination becomes the new complexity. When the orchestration isn’t opinionated about ownership of steps, loops form and costs drift.
From idea to impact: how teams actually ship agents
Implementation usually starts with a constrained wedge. You pick a slice of the workflow that has clear inputs and outputs. With a single agent, you encode the decision path as instructions, add minimal context retrieval, and enforce a basic validation gate. If that loop ships value, you keep it small and reinforce alignment using examples and fast feedback.
Friction shows up as soon as the agent needs to do two different kinds of thinking. Planning versus retrieval. Drafting versus checking. If you push both into one loop, you’ll find prompt conflicts and noisy failures. If you split the responsibilities into two agents, friction shifts to handoff clarity, especially on the contract between outputs and inputs.
As you scale, the quiet costs emerge. With a single agent, scaling means bigger context windows, deeper prompts, and more retries. Latency becomes unpredictable. With multi-agent, scaling means an orchestrator that can route tasks, enforce ordering, and perform backpressure when downstream agents are saturated. You either accept the coordination overhead or the single-agent complexity cost. There is no free path.
Governance changes the calculus. If you need traceable decision steps and auditability, multi-agent flows offer natural checkpoints. If you need fast iteration while requirements are moving, a single agent gives you fewer moving parts to repair. Either way, you’ll need guardrails that are external to the prompts to survive drift.
Choosing the right shape for real environments
When a single agent is the right bet
Use one agent when the problem has a narrow skill footprint. A tightly scoped assistant that transforms a predictable input into a defined output can be kept reliable without orchestration layers. You can add a small validation pass or a post-processor without calling it multi-agent.
Expectations should be modest but consistent. You want fewer prompts to maintain, a clear evaluation harness, and a fast path to improvement. The win is agility.
When multi-agent earns its complexity
Choose multiple agents when the work separates cleanly into different competencies. Planning and execution. Retrieval and synthesis. Drafting and critique. If each step can be owned by a focused loop with a well-specified contract, you gain reliability and interpretability.
You also get a natural place to insert policies. Quality checks are easier when a distinct agent has that job. But you must design for timeouts, partial failures, and fallbacks. Otherwise, you simply move ambiguity from one large loop into three smaller ones that argue.
Examples and applications that reflect real pressure
Scenario 1: A team needs to standardize short reports from semi-structured inputs. The format drifts a little, but the core fields rarely change. A single agent with a tight schema and a post-check is enough. Imperfections show up as occasional field misplacements, which are cheap to catch and fix. Adding more agents would slow the loop without improving outcomes.
Scenario 2: A process requires pulling facts from multiple sources, aligning them to a policy, drafting an explanation, and verifying compliance. One agent can attempt all of this, but failures are opaque and costly. Moving to a small set of agents with explicit roles creates visibility. Friction appears in the handoffs when a check agent rejects drafts for reasons the draft agent doesn’t understand. You fix it by clarifying contracts, not by adding more agents.
Scenario 3: A support workflow triages messages, classifies intent, suggests actions, and prepares a human-ready summary. Peaks in volume stress the system. A single agent starts dropping accuracy when inputs vary too much. A multi-agent approach that separates classification from action drafting holds up, but latency grows due to coordination. The trade-off is acceptable because quality matters more than speed during peaks.
Simple comparison to clarify the decision
Context Students/Beginners Experienced Practitioners Problem scope Try a single agent for most tasks Map skills first, then choose single or multi Design focus Prompt until it seems right Define contracts, inputs, and outputs upfront Failure handling Rely on retries Plan for fallbacks and timeouts Monitoring Check final outputs manually Track intermediate steps and decisions Scaling Increase context and hope Split responsibilities or harden the single loop
FAQ
How do I know if one agent is enough?
If most errors come from ambiguous inputs rather than missing skills, keep one agent and improve contracts and validation.
When should I add a second agent?
Add one when a clear subtask needs different reasoning or policy enforcement that conflicts with the main prompt.
Will multi-agent always cost more?
Coordination adds overhead, but clearer steps often reduce rework. Costs depend on how clean your handoffs are.
What about reliability?
Single agents are simpler to stabilize. Multi-agent becomes more reliable when each role is narrow and measurable.
What’s the fastest path to value?
Start with a thin single-agent wedge, prove value, then split roles only where evidence shows persistent conflicts.
Rising pressure to design for orchestration and oversight
In 2026, the question isn’t whether Single AI Agent vs Multi-Agent Systems is better in the abstract. It’s who owns the boundaries and how you make decisions observable. Responsibility is shifting from prompts to system design.
Keep the loop small until it creaks. Then split responsibility where it relieves real tension. What Businesses Should Use in 2026 is whatever keeps your decisions legible under load and change.


