

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Cloud computing sits behind most modern products, absorbing spikes, hiding complexity, and surfacing new constraints you only meet when things get real.
Executive Summary
This piece translates cloud computing from brochure-speak into the day-to-day realities of building and operating systems.
You’ll see how decisions cascade, where friction shows up, and how scale rewrites rules you thought were settled.
How cloud computing behaves under pressure and why failure patterns cluster
The implementation flow from first deploy to scale, and what breaks
Examples that show imperfect outcomes and the trade-offs behind them
A simple comparison of beginner vs experienced operator choices
Introduction
A small product team ships a new feature late Friday. Traffic triples. One service runs hot, another starves, logging explodes. Nobody wants to rebuild infrastructure at midnight, so they lean on cloud computing: elastic capacity, managed building blocks, quick switches.
That’s the promise. But What is Cloud Computing and How Does It Work? In practice, it’s the on-demand use of shared compute, storage, and network resources delivered as services. You pay for what you use, wire components together through APIs, and inherit constraints shaped by multitenancy, quotas, and shared responsibility.
It’s trending because time-to-value beats perfect architecture, and because Cloud computing compresses experimentation cycles. It’s becoming necessary as systems integrate more moving parts, data sizes swell, and failure surfaces widen across teams, regions, and runtimes.
Cloud computing under pressure: what actually happens
Under load, cloud computing behaves like a set of elastic layers with boundaries you only notice when you hit them: capacity expands, but latency stretches; storage absorbs growth, but indexing lags; network scales, but noisy neighbors and throttles appear. Concept diagram: service layers, capacity spikes, and failure boundaries.
Common boundaries:
Elasticity is not instant. Auto-scaling reacts, but reaction time matters. If bursts arrive in seconds and scale events take minutes, you bridge with buffers or accept transient errors.
Throughput and latency trade. More concurrency pushes queues deeper. You get higher throughput at the cost of tail latency. Downstream timeouts stack like dominos.
Storage grows faster than indexing schemas evolve. Writes keep pace; reads degrade when the model isn’t reshaped for scale. Caching masks it, until a cold path lights up under a rare query.
Multi-tenant realities bite. Quotas protect the platform. You hit a rate limit, fail soft, and watch retries magnify the storm. Circuit breakers stop the bleeding if you added them early.
Observed failure patterns:
Retry storms. Clients retry on timeouts without backoff. Load doubles, then triples. One service misbehaves; upstream collapses.
Partial outages. “Mostly working” systems hide data skew, stale caches, stuck queues. The incident ends when skew is corrected, not when a server restarts.
Cost spikes. Elastic capacity flexes during incidents. It saves uptime, but the bill exposes a noisy component you never tuned.
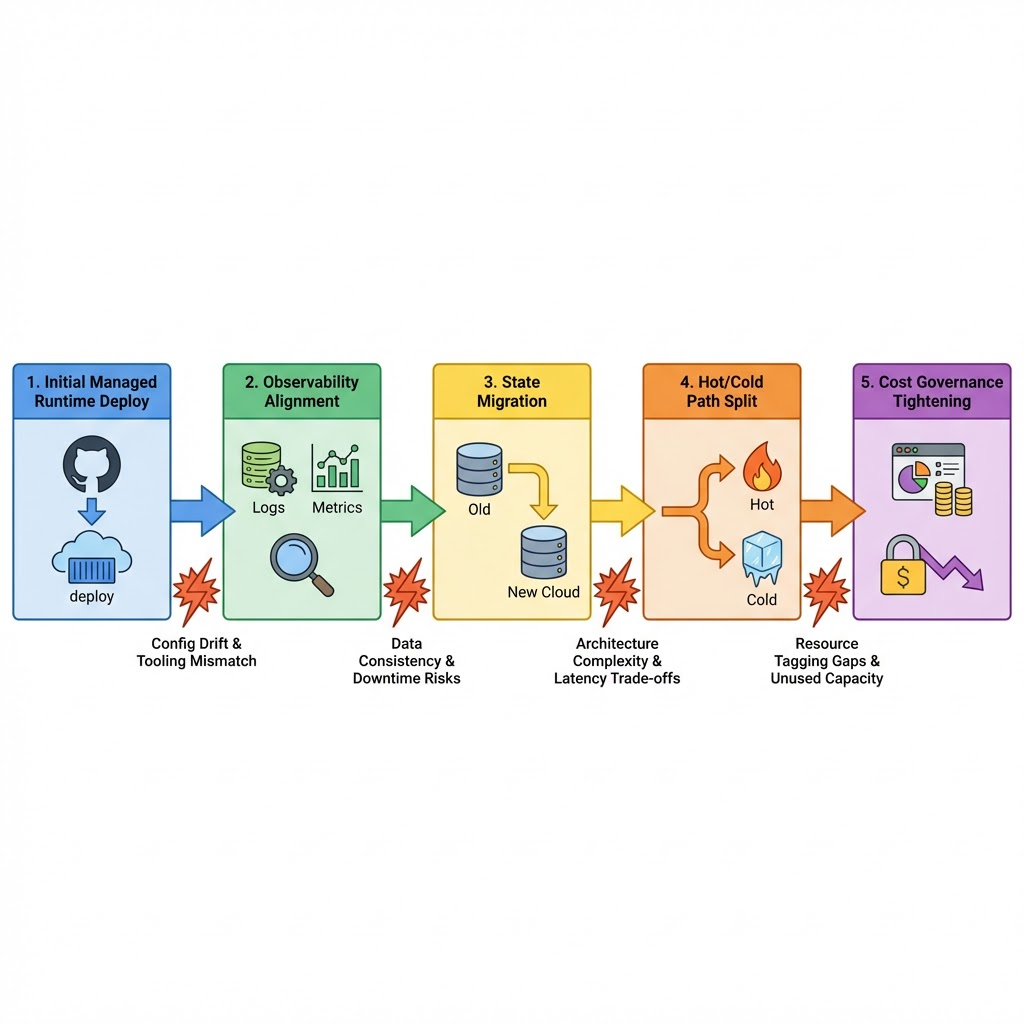
Rolling out cloud computing when deadlines are real: deployment path and friction
First steps are usually pragmatic. You start with a managed runtime to avoid babysitting servers. Wire storage with a simple schema, ship the feature, and monitor only what breaks. That’s honest, and it works long enough to validate value.
Friction shows up in the seams:
Service boundaries are fuzzy at first. Logging and tracing don’t align, so incidents feel like guesswork. You tighten your interfaces, add simple correlation IDs, and pare down noisy logs.
State gets sticky. Stateless components scale cleanly; stateful ones do not. Migrations under live traffic teach you to move state incrementally and keep rollback plans small but executable.
Scaling changes decisions you made early:
Write patterns matter. Bursty writes punish downstream consistency. You stagger workloads, adopt idempotent operations, and accept that some paths should be slow.
Cost governance matures. You start with a single budget line. Later, you tag resources and review costs by feature. Teams own their footprint, and unused capacity becomes visible enough to kill.
Reliability shifts left. You don’t get perfection from managed services. You build small guardrails: timeouts, retries with backoff, circuit breakers, and dead-letter queues. Each one buys you time during an incident.
Examples and Applications
A spiky analytics job that looked simple
A nightly batch grew from minutes to hours. Compute scaled, but storage read latencies ballooned and caches thrashed. The team split the job: pre-aggregate hot data earlier, push cold data to a slower lane, and keep the top-line report timely. Uptime held; accuracy lagged on low-priority segments for a day. Acceptable, documented.
Feature flags at scale
Moving configuration to a cloud-hosted store removed redeploys, but reads hit rate limits during a rollout. Caching helped until a rare toggle caused cache churn. The fix wasn’t a bigger cache. It was bounded change windows and backpressure on flag updates. Operations stepped into product workflows; deploys slowed to protect availability.
Real-time messaging that refused to be “serverless”
The team embraced event-driven components. Fine for bursts. Under sustained streams, costs climbed and cold starts became noticeable. They kept the event model, but introduced a small, long-lived worker pool for hot paths. The rest stayed elastic. Result: lower latency on the hot route, slightly higher complexity, tighter cost bounds.
Comparisons: beginners vs experienced operators
Decision Area Beginners Experienced Practitioners Scaling Strategy Auto-scale everything and trust defaults Separate hot/cold paths; set floor/ceiling; tune cooldowns Retries & Timeouts Add retries broadly Use bounded retries with jitter; match timeouts to dependency SLAs State Management Monolithic schema; big-bang migrations Incremental migration; dual-write or backfill; easy rollback Cost Visibility Single budget; react post hoc Tag by feature; alerts on anomalies; kill unused capacity Observability Verbose logs; minimal correlation Lean logs; trace IDs; dashboards tied to user impact Incident Posture Scale up and hope Rate-limit, shed load, protect core paths, then scale
FAQ
Is cloud computing always cheaper?
Not by default. It’s cheaper when elasticity replaces idle capacity and teams control scale, retries, and data retention.
How does cloud computing change release cadence?
It speeds early releases. Later, guardrails and cost checks add steps. Cadence stays high if you automate the boring parts.
Do I need full microservices to benefit?
No. You can start with a small set of managed services around a simple core and expand boundaries as needs grow.
What’s the first reliability control to add?
Time-box calls and add backoff on retries. Those two prevent most cascade failures.
When should I split hot and cold paths?
As soon as tail latency matters or costs spike during bursts. It’s usually earlier than you think.
Responsibility shifts as cloud computing matures
Early on, the platform carries you. Later, responsibility drifts back to teams: shaping workloads, owning costs, and designing for graceful failure.
The progression is simple: from consuming services to orchestrating them thoughtfully. The pressure rises where seams exist. That’s where good engineering shows.


