

Founder & CEO, Devot AI
A multi-domain Data Scientist and Software Engineer specializing in NLP, Large Language Models, and scalable AI systems. Aviral leads Devot AI with a focus on building production-ready solutions that solve complex business challenges.
Teams adopted text-to-SQL to unblock analytics, then hit a wall. Databrick's Genie Agents push past that wall by acting like operators, not translators.
Executive Summary
Text-to-SQL works for demos. Real environments carry schema drift, policy gates, flaky metadata, and tight latency budgets. That’s where single-shot tools fold.
Genie-style agents change the game by planning, verifying, and adapting across steps. They don’t just write a query. They reason about context, constraints, and consequences.
Understand where classic text-to-SQL fails under change and pressure
See how Databrick's Genie Agents plan, check, and self-correct
Learn implementation flow, friction points, and scaling patterns
Compare beginner vs experienced approaches to shipping agents
Beyond Text-to-SQL: Why Genie Agents Are Smarter Than Old AI Tools is not about hype. It’s about fewer incidents, faster answers, and guardrails that hold.
Introduction: when the easy answer breaks production
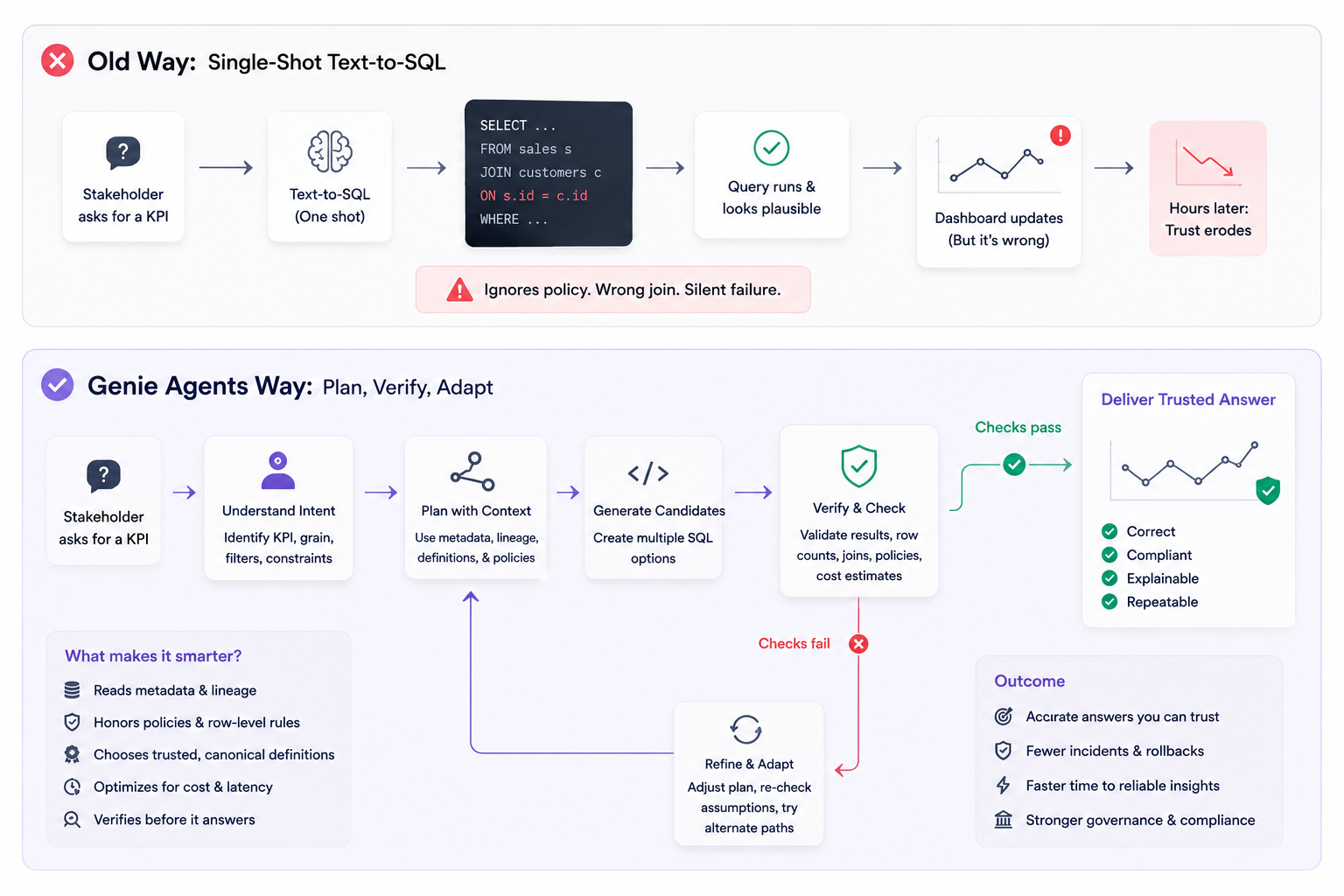
A stakeholder asks for a KPI. You try a text prompt. It returns a query that runs, even looks plausible, but ignores a policy and joins on the wrong key. The dashboard updates. Hours later, trust erodes.
This is the gap between single-shot text-to-SQL and agents that behave like operators. The former converts language to code. The latter plans, checks, and adapts under constraints.
Beyond Text-to-SQL: Why Genie Agents Are Smarter Than Old AI Tools matters because data workloads have grown messy. Schemas shift. Definitions diverge. Governance tightens. Latency costs money. Databrick's Genie Agents are trending because they bring planning and verification loops to the table, not just translation.
Necessity comes from pressure. Teams need answers that are explainable, repeatable, and compliant, even when context changes mid-flight.
Where smart agents earn their keep under real pressure
In production, an agent has to do more than generate SQL. It needs to understand intent, find the right canonical definitions, negotiate policy, and adapt if a column moved yesterday. That means planning, tool use, and verification, not one-shot guesses.
How Genie Agents negotiate constraints across data layers
Boundaries show up fast. Ambiguous column names lead to wrong joins. Derived metrics conflict across teams. Row-level rules narrow the dataset and break naive estimates. Cost ceilings block full scans. Agents that only translate text will hallucinate through these edges.
Failure patterns repeat. A generated query returns partial results due to default limits. A deprecated table still exists, so the agent picks it over the curated one. Schema drift silently changes a type and the model’s comparison logic collapses. Without a deliberate repair loop, you only find these issues after the incident review.
Genie-style agents mitigate by reading metadata, planning against constraints, and verifying outputs. They inspect lineage and tags to favor trusted sources. They generate candidate plans, pick the cheapest safe path, and run sanity checks before surfacing an answer. If a check fails, they iterate. That second and third step is where reliability shows up.
From prompt to production: the flow of a Genie Agent under constraints
Implementation starts small. A single entry point accepts a question. The agent parses intent and maps it to known metrics and entities. If definitions conflict, it asks for clarification or chooses the canonical one by policy. Translation happens later. First comes understanding.
Next, it plans. The plan lists target tables, join paths, filters, and checks. It also outlines risks and fallbacks. A good plan encodes the budget for latency and cost, preferred sources, and required validations. Only then does the agent pick the tools to execute.
Execution includes retrieving definitions, composing SQL, and running dry validations. Cheap probes catch missing columns, type mismatches, or access denials. The agent adjusts the plan, not just the query, when something doesn’t fit.
Verification is where old tools stop and agents continue. The agent runs expectations against the result: ranges, cardinality checks, join coverage, and known invariants. If results fail, it attempts targeted repairs. For example, it may switch to a curated table or apply a more precise filter sourced from definitions.
Where friction appears: ambiguous intent, stale metadata, and policy ambiguity. Ambiguity triggers clarifying questions or conservative fallbacks. Stale metadata pushes the agent to inspect live schemas instead of trusting a catalog entry. Policy ambiguity escalates to a safe refusal with guidance instead of a risky guess.
At scale, two things change. First, you instrument every step to measure errors, retries, and cost. Second, you cache safe plans and verified answers for repeated intents. The agent learns preferred join paths and trusted sources, reducing variance. You still keep the verification layer live, because drift never stops.
Examples and applications that don’t go by the book
A team asks for month-over-month growth. The agent finds two definitions of “active.” It picks the canonical metric based on tags, runs the query, then detects a sudden spike that violates a known invariant. It inspects recent schema changes, notices a new event source, and applies a filter that aligns with the canonical definition. The answer arrives with a short rationale. The spike disappears.
Another team asks for top segments by revenue. The agent drafts a join through a deprecated table because names look similar. Verification flags missing coverage. The agent switches to a curated path discovered through lineage. The output now matches historical patterns within tolerance. Time to answer increases slightly, but avoids rework later.
During a migration, a column type changes from integer to string. A naive translator returns no rows due to implicit casts. The agent catches the mismatch in a dry run, adapts the filter, and annotates the plan so the cast is explicit and cheap.
In a restricted project, the agent hits a policy gate. Instead of failing with a stack trace, it returns a minimal aggregate with an explanation and a safe reference query others can run with the right access.
How approach differs when you’re new vs when you’ve shipped systems
Area Students/Beginners Experienced Practitioners Prompting Describe the task and hope for a good query Encode constraints, sources, and checks in the plan Source selection Pick tables by name similarity Prefer curated paths via lineage and tags Validation Trust the first successful run Run invariants, ranges, and coverage checks Error handling Retry the same query with minor edits Adjust the plan, switch tools, or escalate conservatively Scaling Duplicate patterns per use case Instrument, cache safe plans, and centralize policies Security Add checks after incidents Policy as a first-class constraint in planning
FAQ
Can’t we just improve text-to-SQL prompts?
You’ll squeeze marginal gains, but you won’t get planning, verification, or policy negotiation. Prompts can’t replace a multi-step agent.
Are Genie Agents slower?
They add checks, but avoid costly rework and incidents. With caching and smart planning, median time drops as patterns stabilize.
How do we keep agents from using the wrong tables?
Favor curated sources through lineage and tags, and enforce checks that penalize deprecated paths.
What if the agent can’t disambiguate a metric?
Default to safe refusal or ask a targeted question. Silent guesses cost more than a short delay.
Do we need perfect metadata first?
No. Start with what you have. Make verification strict and let the agent surface gaps to improve over time.
Accountability is shifting from answers to orchestration
As agents like Databrick's Genie Agents permeate daily workflows, responsibility moves upstream. It’s less about crafting the perfect query and more about shaping constraints, preferred sources, and checks the agent must honor.
The pressure rises on operators to encode judgment into plans and policies. The model writes code. You define the boundaries where that code is allowed to run and the proofs required before anyone trusts the output.


